
パリを拠点とするスタートアップのMistral AIは、最近20億ドルの評価を獲得し、オープンな大規模言語モデル(LLM)であるMixtralをリリースした。
ミストラルは、変革をもたらすテクノロジー分野、特にAIへの戦略的投資で有名なベンチャーキャピタル、アンドリーセン・ホロウィッツ(a16z)から、シリーズAで多額の投資を受けた。この資金調達ラウンドには、NvidiaやSalesforceといった他のハイテク大手も参加している。
「アンドリーセン・ホロウィッツは資金調達の発表の中で、「ミストラルは、オープンソースのAIを中心に成長している、小規模だが情熱的な開発者コミュニティの中心にいる。「コミュニティが微調整したモデルは現在、オープンソースのリーダーボードを日常的に席巻している(タスクによってはクローズドソースのモデルに勝つことさえある)。
Mixtralは、スパース混合エキスパート(MoE)と呼ばれる技術を使用しており、Mistralによると、このモデルはその前身であるMistral 7bや、さらに強力な競合他社よりも強力で効率的だという。
専門家の混合(MoE)とは、開発者が複雑な問題を解決するために複数の仮想専門家モデルを訓練または設定する機械学習技術である。各エキスパート・モデルは、特定のトピックや分野についてトレーニングされる。問題が発生すると、モデルはエージェントのプールから専門家グループを選択し、それらの専門家はトレーニングを利用して、どの出力がより自分の専門知識に適しているかを決定する。
MoEは、ディープラーニングモデルの容量、効率、精度を向上させることができる。Mixtralを他から引き離す秘密のソースは、10倍小さいモデルを使用して700億のパラメータで訓練されたモデルに対抗することができる。
「Mixtralは総パラメータ46.7Bを持つが、トークンあたり12.9Bのパラメータしか使わない」とMistral AIは言う。「したがって、12.9Bのモデルと同じスピードとコストで入力を処理し、出力を生成する。
“MixtralはほとんどのベンチマークでLlama 2 70Bを6倍高速推論で上回り、ほとんどの標準ベンチマークでGPT 3.5と同等か上回ります “とMistral AIは公式ブログポストで述べています
。
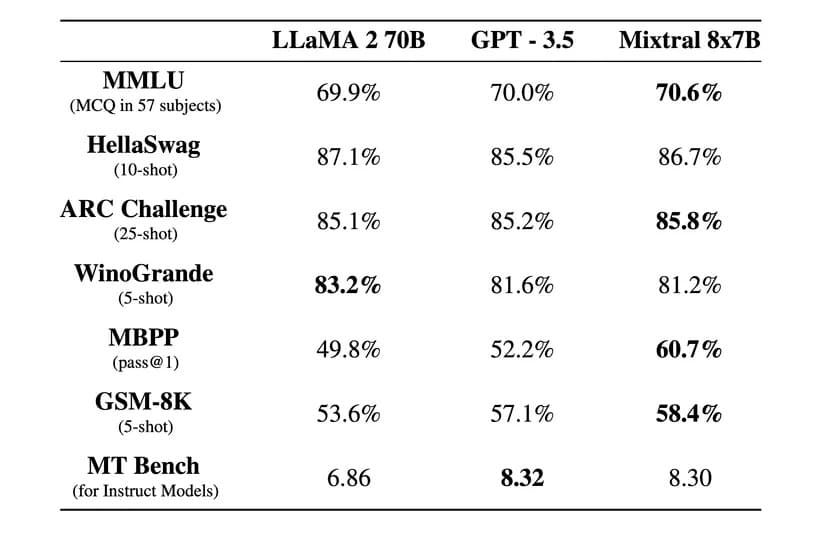
Image: Mistral AI
Mixtralは、寛容なApache 2.0ライセンスでもライセンスされています。これによって開発者は、このモデルの上で自由に検査、実行、修正、さらにはカスタムソリューションを構築することができる。
しかし、Mixtralが100%オープンソースかどうかについては議論がある。Mistralは「オープン・ウェイト」のみをリリースしたと言っており、コアモデルのライセンスはMistral AIと競合するために使用することを妨げている。また、オープンソースのプロジェクトであれば、トレーニングデータセットやモデルの作成に使用されたコードも提供されていない。
同社によると、Mixtralは英語以外の外国語でも非常にうまく動作するように微調整されているという。「Mixtral 8x7Bはフランス語、ドイツ語、スペイン語、イタリア語、英語をマスターし、標準化された多言語ベンチマークで高得点を獲得した」とMistral AIは述べている。
Mixtral 8x7B Instructと呼ばれるインストラクション・バージョンもリリースされ、MT-Benchベンチマークで8.3の最高得点を獲得した。これは、同ベンチマークにおける現在のオープンソース最高モデルとなる。
Mistralの新しいモデルは、革命的なスパース混合エキスパート・アーキテクチャ、優れた多言語能力、完全なオープンアクセスを約束している。
MixtralはHugging Faceからダウンロード可能だが、オンラインでインストラクター・バージョンを使うこともできる。