
Базираният в Париж стартъп Mistral AI, който наскоро получи оценка от 2 млрд. долара, пусна Mixtral – отворен голям езиков модел (LLM), който според него превъзхожда GPT 3.5 на OpenAI в няколко сравнителни теста, като същевременно е много по-ефективен.
Мистрал привлече значителна инвестиция от серия А от Andreessen Horowitz (a16z), компания за рисков капитал, известна със стратегическите си инвестиции в трансформиращи се технологични сектори, особено в областта на изкуствения интелект. Други технологични гиганти като Nvidia и Salesforce също участваха в кръга на финансиране.
„Mistral е в центъра на малка, но страстна общност от разработчици, която се развива около ИИ с отворен код“, заяви Andreessen Horowitz в съобщението си за финансиране. „Моделите, настроени от общността, вече рутинно доминират в класациите с отворен код (и дори побеждават моделите със затворен код при някои задачи).“
Mixtral използва техника, наречена рядка смес от експерти (SM), която според Mistral прави модела по-мощен и ефективен от предшественика му Mistral 7b – и дори от по-мощните му конкуренти.
Смес от експерти (MoE) е техника за машинно обучение, при която разработчиците обучават или създават множество виртуални експертни модели за решаване на сложни проблеми. Всеки експертен модел се обучава по определена тема или област. Когато му бъде зададен проблем, моделът избира група експерти от пул от агенти, а тези експерти използват обучението си, за да решат кой изход отговаря по-добре на тяхната експертиза.
MoE може да подобри капацитета на модела, ефективността и точността на моделите за дълбоко обучение – тайният сос, който отличава Mixtral от останалите, способен да се конкурира с модел, обучен на 70 милиарда параметри, използвайки модел, който е 10 пъти по-малък.
„Mixtral разполага с 46,7 млрд. общи параметри, но използва само 12,9 млрд. параметри за един токен“, казват от Mistral AI. „Следователно той обработва входни данни и генерира изходни данни със същата скорост и на същата цена като модел с 12,9B параметри.“
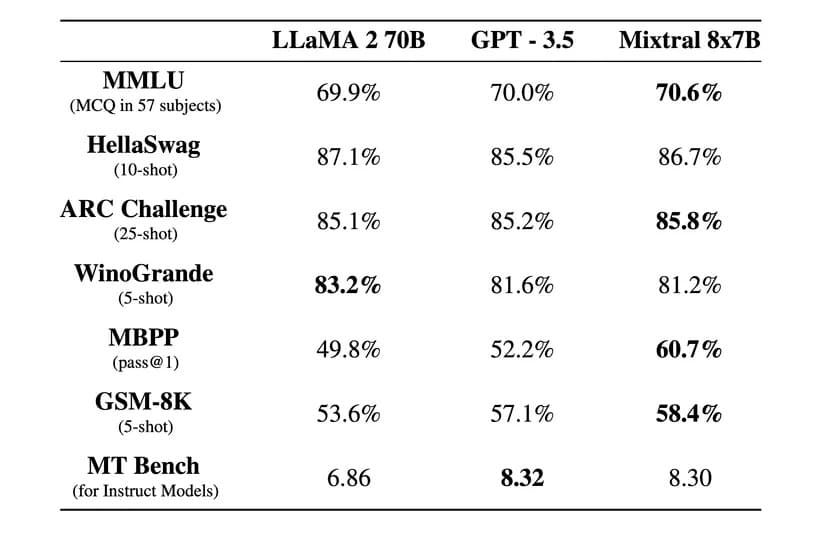
„Mixtral превъзхожда Llama 2 70B в повечето бенчмаркове с 6 пъти по-бърз извод и съвпада или превъзхожда GPT 3.5 в повечето стандартни бенчмаркове“, заяви Mistral AI в официална публикация в блога.
Изображение: Mistral AI
Mistral също така е лицензиран под разрешаващия лиценз Apache 2.0. Това позволява на разработчиците свободно да проверяват, стартират, модифицират и дори да изграждат персонализирани решения върху модела.
Съществува обаче дебат за това дали Mixtral е 100% отворен код или не, тъй като Mistral твърди, че е пуснала само „отворени тежести“, а лицензът на ядрото на модела не позволява използването му за конкуриране с Mistral AI. Стартъпът също така не е предоставил набора от данни за обучение и кода, използван за създаване на модела, което би било задължително при проект с отворен код.
Компанията твърди, че Mixtral е бил прецизиран, за да работи изключително добре на чужди езици, освен на английски. „Mixtral 8x7B владее френски, немски, испански, италиански и английски език“, постигайки високи резултати в стандартизирани многоезични сравнителни тестове, казват от Mistral AI.
Беше пусната и версия с инструкции, наречена Mixtral 8x7B Instruct, за внимателно следване на инструкциите, която постигна най-добър резултат от 8,3 точки в бенчмарка MT-Bench. Това го прави най-добрият модел с отворен код в момента в този бенчмарк.
Новият модел на Мистрал обещава революционна архитектура с рядка смес от експерти, добри многоезични възможности и напълно отворен достъп, И като се има предвид, че това се случи само няколко месеца след създаването му, общността с отворен код преминава през вълнуваща и интересна ера.
Mixtral е на разположение за изтегляне чрез Hugging Face, но потребителите могат да използват и инструктивната версия онлайн.