
De in Parijs gevestigde startup Mistral AI, die onlangs een waardering van $ 2 miljard opeiste, heeft Mixtral uitgebracht, een open groot taalmodel (LLM) dat naar eigen zeggen beter presteert dan OpenAI’s GPT 3.5 in verschillende benchmarks en tegelijkertijd veel efficiënter is.
Mistral heeft een substantiële Serie A-investering aangetrokken van Andreessen Horowitz (a16z), een durfkapitaalbedrijf dat bekend staat om zijn strategische investeringen in transformatieve technologiesectoren, met name AI. Andere techgiganten zoals Nvidia en Salesforce namen ook deel aan de financieringsronde.
“Mistral staat in het middelpunt van een kleine maar gepassioneerde ontwikkelaarsgemeenschap die groeit rond open source AI”, zegt Andreessen Horowitz in de aankondiging van de financiering. “Door de gemeenschap verfijnde modellen domineren nu routinematig open source leaderboards (en verslaan zelfs closed source modellen op sommige taken).”
Mixtral gebruikt een techniek genaamd sparse mixture of experts (MoE), die volgens Mistral het model krachtiger en efficiënter maakt dan zijn voorganger Mistral 7b en zelfs zijn krachtigere concurrenten.
Een Mixture of experts (MoE) is een techniek voor machinaal leren waarbij ontwikkelaars meerdere virtuele expertmodellen trainen of opzetten om complexe problemen op te lossen. Elk expertmodel wordt getraind op een specifiek onderwerp of gebied. Wanneer het model een probleem voorgeschoteld krijgt, kiest het een groep experts uit een pool van agenten, en die experts gebruiken hun training om te beslissen welke uitvoer beter bij hun expertise past.
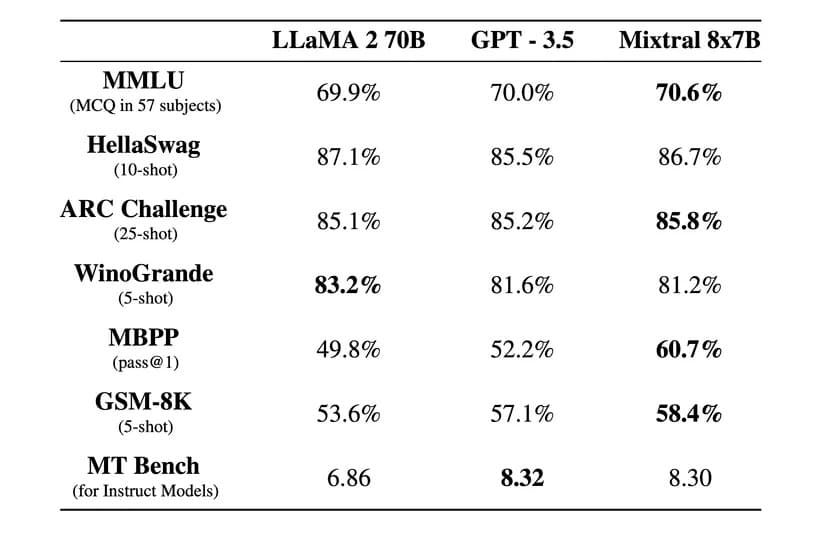
MoE kan de modelcapaciteit, efficiëntie en nauwkeurigheid van deep learning-modellen verbeteren – het geheime sausje waarmee Mixtral zich onderscheidt van de rest, in staat om het op te nemen tegen een model dat is getraind op 70 miljard parameters met behulp van een model dat 10 keer kleiner is.
“Mixtral heeft 46,7B totale parameters maar gebruikt slechts 12,9B parameters per token,” aldus Mistral AI. “Het verwerkt dus input en genereert output met dezelfde snelheid en voor dezelfde kosten als een 12,9B model.”
“Mixtral presteert beter dan Llama 2 70B op de meeste benchmarks met 6x snellere inferentie en evenaart of overtreft GPT 3.5 op de meeste standaard benchmarks,” zei Mistral AI in een officiële blogpost.
Afbeelding: Mistral AI
Mixtral is ook gelicenseerd onder de permissieve Apache 2.0 licentie. Hierdoor kunnen ontwikkelaars het model vrij inspecteren, uitvoeren, aanpassen en zelfs aangepaste oplossingen bouwen bovenop het model.
Er is echter discussie over de vraag of Mixtral 100% open source is of niet, aangezien Mistral zegt dat het alleen “open weights” heeft vrijgegeven en de licentie van het kernmodel voorkomt dat het gebruikt wordt om te concurreren met Mistral AI. De startup heeft ook de trainingsdataset en de code die is gebruikt om het model te maken niet vrijgegeven, wat wel het geval zou zijn bij een open-source project.
Het bedrijf zegt dat Mixtral is verfijnd om uitzonderlijk goed te werken in andere talen dan Engels. “Mixtral 8x7B beheerst Frans, Duits, Spaans, Italiaans en Engels” en scoort hoog in gestandaardiseerde meertalige benchmarks, aldus Mistral AI.
Een geïnstrueerde versie genaamd Mixtral 8x7B Instruct werd ook uitgebracht voor het zorgvuldig volgen van instructies en behaalde een topscore van 8,3 op de MT-Bench benchmark. Daarmee is het op dit moment het beste open source model in de benchmark.
Het nieuwe model van Mistral belooft een revolutionaire sparse mixture-of-experts-architectuur, goede meertalige mogelijkheden en volledige open toegang. En gezien het feit dat dit slechts enkele maanden na de creatie gebeurde, maakt de open-source gemeenschap een opwindend en interessant tijdperk door.
Mixtral is te downloaden via Hugging Face, maar gebruikers kunnen de instructieversie ook online gebruiken.