
La startup Mistral AI con sede a Parigi, che ha recentemente ottenuto una valutazione di 2 miliardi di dollari, ha rilasciato Mixtral, un modello linguistico aperto di grandi dimensioni (LLM) che, a suo dire, supera GPT 3.5 di OpenAI in diversi benchmark ed è molto più efficiente.
Mistral ha ottenuto un sostanzioso investimento di serie A da Andreessen Horowitz (a16z), una società di venture capital rinomata per i suoi investimenti strategici in settori tecnologici trasformativi, in particolare l’IA. Al round di finanziamento hanno partecipato anche altri giganti della tecnologia come Nvidia e Salesforce.
“Mistral è al centro di una piccola ma appassionata comunità di sviluppatori che sta crescendo intorno all’IA open source”, ha dichiarato Andreessen Horowitz nell’annuncio del finanziamento. “I modelli messi a punto dalla comunità dominano ormai abitualmente le classifiche open source (e battono persino i modelli closed source in alcuni compiti)”.
Mixtral utilizza una tecnica chiamata sparse mixture of experts (MoE), che secondo Mistral rende il modello più potente ed efficiente del suo predecessore, Mistral 7b, e anche dei suoi concorrenti più potenti.
Una miscela di esperti (MoE) è una tecnica di apprendimento automatico in cui gli sviluppatori addestrano o impostano più modelli esperti virtuali per risolvere problemi complessi. Ogni modello esperto viene addestrato su un argomento o un campo specifico. Quando gli viene sottoposto un problema, il modello sceglie un gruppo di esperti da un pool di agenti, e questi esperti utilizzano la loro formazione per decidere quale output si adatta meglio alle loro competenze.
MoE può migliorare la capacità, l’efficienza e l’accuratezza dei modelli di deep learning: la salsa segreta che distingue Mixtral dagli altri, in grado di competere con un modello addestrato su 70 miliardi di parametri utilizzando un modello 10 volte più piccolo.
“Mixtral ha 46,7 miliardi di parametri totali ma utilizza solo 12,9 miliardi di parametri per token”, ha dichiarato Mistral AI. “Pertanto, elabora l’input e genera l’output alla stessa velocità e allo stesso costo di un modello da 12,9B”.
“Mixtral supera Llama 2 70B nella maggior parte dei benchmark, con un’inferenza 6 volte più veloce, ed eguaglia o supera GPT 3.5 nella maggior parte dei benchmark standard”, ha dichiarato Mistral AI in un post sul blog ufficiale.
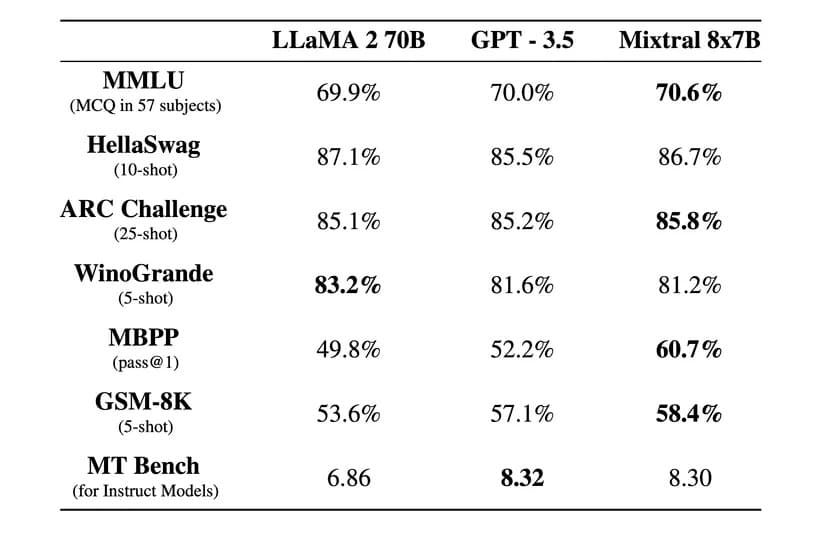
Immagine: Mistral AI
Mixtral è anche concesso in licenza con la licenza permissiva Apache 2.0. Ciò consente agli sviluppatori di ispezionare, eseguire, modificare e persino costruire soluzioni personalizzate sulla base del modello.
Si discute tuttavia se Mixtral sia o meno open source al 100%, poiché Mistral afferma di aver rilasciato solo “pesi aperti” e la licenza del modello principale ne impedisce l’uso per competere con Mistral AI. Inoltre, la startup non ha fornito il set di dati di addestramento e il codice utilizzato per creare il modello, come invece avverrebbe in un progetto open-source.
L’azienda afferma che Mixtral è stato messo a punto per funzionare in modo eccezionale nelle lingue straniere oltre all’inglese. “Mixtral 8x7B è in grado di padroneggiare il francese, il tedesco, lo spagnolo, l’italiano e l’inglese”, ottenendo un punteggio elevato nei benchmark multilingue standardizzati, ha dichiarato Mistral AI.
È stata rilasciata anche una versione istruita, chiamata Mixtral 8x7B Instruct, che ha ottenuto un punteggio massimo di 8,3 nel benchmark MT-Bench. Questo lo rende l’attuale miglior modello open source su questo benchmark.
Il nuovo modello di Mistral promette un’architettura rivoluzionaria di tipo sparse mixture-of-experts, buone capacità multilinguistiche e un accesso completamente aperto.
Mixtral è disponibile per il download tramite Hugging Face, ma gli utenti possono anche utilizzare la versione istruita online.