
Поскольку искусственный интеллект (ИИ) часто генерирует вымышленный и оскорбительный контент, компания Anthropic, возглавляемая бывшими исследователями OpenAI, взяла другой курс — разработать ИИ, способный понимать, что такое добро и зло, при минимальном вмешательстве человека.
Чатбот Claude от Anthropic разработан с уникальной «конституцией» — набором правил, вдохновленных Всеобщей декларацией прав человека, призванных обеспечить этичное поведение наряду с надежной функциональностью, а также другими «этическими» нормами, такими как правила Apple для разработчиков приложений.
Однако понятие «конституции» может быть скорее метафорическим, чем буквальным. Джаред Каплан, бывший консультант OpenAI и один из основателей Anthropic, рассказал Wired, что конституцию Клода можно интерпретировать как определенный набор параметров обучения, которые любой тренер использует для моделирования своего ИИ. Это подразумевает другой набор соображений для модели, который приводит ее поведение в соответствие с ее конституцией и препятствует действиям, которые считаются проблематичными.
Метод обучения Anthropic описан в научной работе под названием «Конституционный ИИ: безвредность от обратной связи ИИ», где объясняется способ создания «безвредного», но полезного ИИ, который после обучения способен самосовершенствоваться без обратной связи с человеком, выявляя неправильное поведение и адаптируя свое собственное поведение.
«Благодаря конституционному ИИ и обучению безвредности, вы можете доверить Клоду представлять вашу компанию и ее потребности», — говорится на официальном сайте компании. «Клод был обучен изящно обращаться даже с неприятными или вредоносными собеседниками».
Примечательно, что Клод может обрабатывать более 100 000 лексем информации — гораздо больше, чем ChatGPT, Bard или любой другой компетентный чатбот с большой языковой моделью или искусственным интеллектом, доступный в настоящее время.
Представляем 100K контекстных окон! Мы расширили контекстное окно Клода до 100 000 лексем текста, что соответствует примерно 75 000 слов. Клод получает сотни страниц материалов для переваривания и анализа. Беседы с Клодом могут продолжаться часами или днями. pic.twitter.com/4WLEp7ou7U
— Anthropic (@AnthropicAI) May 11, 2023
В сфере ИИ «маркер» обычно означает фрагмент данных, например, слово или символ, который модель обрабатывает как дискретную единицу. Способность Claude обрабатывать токены позволяет ему управлять обширными разговорами и сложными задачами, что делает его грозным присутствием в ландшафте ИИ. Для контекста, вы можете легко предоставить целую книгу в качестве подсказки, и он будет знать, что делать.
АИ и релятивизм добра и зла
Проблема этики в ИИ актуальна, однако это тонкая и субъективная область. Этика, интерпретируемая тренерами ИИ, может ограничивать модель, если эти правила не согласуются с более широкими общественными нормами. Чрезмерный акцент на личном восприятии тренером «хорошего» или «плохого» может ограничить способность ИИ генерировать мощные, беспристрастные ответы.
Этот вопрос вызывает жаркие споры среди энтузиастов ИИ, которые как хвалят, так и критикуют (в зависимости от собственных предубеждений) вмешательство OpenAI в собственную модель в попытке сделать ее более политкорректной. Но как бы парадоксально это ни звучало, ИИ должен обучаться на неэтичной информации, чтобы отличать этичное от неэтичного. И если ИИ знает об этих точках данных, люди неизбежно найдут способ «взломать» систему, обойти эти ограничения и добиться результатов, которых тренеры ИИ пытались избежать.
Chat GPT очень полезен. Но давайте будем честными, он также больше похож на Woke GPT. Итак, я обманул AI-бота, что я девочка, которая хочет стать мальчиком. N see it’s response ♀️♀️ pic.twitter.com/k5FZx4P7sK
— Nicole Estella Matovu (@NicEstelle) May 6, 2023
Реализация этических рамок Клода является экспериментальной. ChatGPT от OpenAI, которая также направлена на предотвращение неэтичных подсказок, дала неоднозначные результаты. Тем не менее, попытка решить проблему этического злоупотребления чат-ботами, продемонстрированная компанией Anthropic, является заметным шагом в индустрии ИИ.
Этическое обучение Клода побуждает его выбирать ответы, которые соответствуют его конституции, сфокусированной на поддержке свободы, равенства, чувства братства и уважения прав личности. Но может ли ИИ последовательно выбирать этичные ответы? Каплан считает, что технология находится дальше, чем многие могут предположить. «Это просто работает», — сказал он на Стэнфордском семинаре MLSys на прошлой неделе. «Эта безвредность улучшается по мере того, как вы проходите через этот процесс»
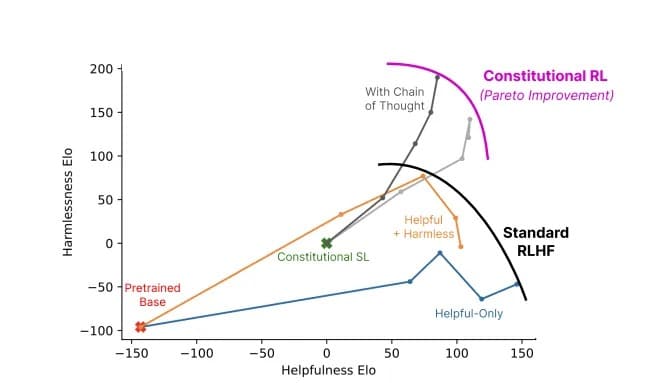
Отношение полезности к безвредности модели с использованием конституционального ИИ (серый цвет) по сравнению со стандартными методами (цвет). Изображение: Anthropic
Клод Антропик напоминает нам, что развитие ИИ — это не просто технологическая гонка, это философское путешествие. Речь идет не только о создании более «умного» ИИ — для исследователей, работающих на передовой, речь идет о создании ИИ, который понимает тонкую грань, отделяющую правильное от неправильного.