
V době, kdy umělá inteligence (AI) často vytváří fiktivní a urážlivý obsah, se společnost Anthropic, v jejímž čele stojí bývalí výzkumníci OpenAI, vydala jiným směrem – vyvinula AI schopnou poznat, co je dobro a zlo, a to s minimálním zásahem člověka.
Chatbot Claude společnosti Anthropic je navržen s jedinečnou „ústavou“, souborem pravidel inspirovaných Všeobecnou deklarací lidských práv, vytvořenou tak, aby vedle robustní funkčnosti zajistila i etické chování, spolu s dalšími „etickými“ normami, jako jsou pravidla společnosti Apple pro vývojáře aplikací.
Pojem „ústava“ však může být spíše metaforický než doslovný. Jared Kaplan, bývalý konzultant OpenAI a jeden ze zakladatelů společnosti Anthropic, řekl časopisu Wired, že Claudovu ústavu lze interpretovat jako specifický soubor tréninkových parametrů – které každý trenér používá k modelování své umělé inteligence. Z toho vyplývá jiný soubor úvah pro model, který své chování více přizpůsobuje své konstituci a odrazuje od činností považovaných za problematické.
Metoda tréninku Anthropic je popsána ve výzkumné práci s názvem „Constitutional AI: Harmlessness from AI Feedback“, která vysvětluje způsob, jak přijít s „neškodnou“, ale užitečnou umělou inteligencí, která je po vyškolení schopna se sama zlepšovat bez zpětné vazby od člověka, identifikovat nevhodné chování a přizpůsobit své vlastní chování.
„Díky ústavní umělé inteligenci a tréninku neškodnosti můžete Claudovi důvěřovat, že bude reprezentovat vaši společnost a její potřeby,“ uvádí společnost na svých oficiálních webových stránkách. „Claude byl vycvičen tak, aby s grácií zvládl i nepříjemné nebo zlomyslné konverzační partnery.“
Pozoruhodné je, že Claude dokáže zpracovat více než 100 000 tokenů informací – mnohem více než ChatGPT, Bard nebo jakýkoli jiný kompetentní velký jazykový model nebo chatbot s umělou inteligencí, který je v současné době k dispozici.
Představujeme 100K kontextových oken! Rozšířili jsme Claudovo kontextové okno na 100 000 tokenů textu, což odpovídá přibližně 75 tisícům slov. Předkládejte Claudovi stovky stránek materiálů, které může zpracovat a analyzovat. Konverzace s Claudem může trvat hodiny nebo dny. pic.twitter.com/4WLEp7ou7U
– Anthropic (@AnthropicAI) Květen 11, 2023
V oblasti umělé inteligence se „tokenem“ obecně rozumí část dat, například slovo nebo znak, které model zpracovává jako diskrétní jednotku. Kapacita tokenů modelu Claude umožňuje zvládat rozsáhlé konverzace a složité úlohy, což z něj činí impozantní osobnost na poli umělé inteligence. Pro kontext byste mu mohli snadno poskytnout celou knihu jako výzvu a on by věděl, co má dělat.
AI a relativismus dobra a zla
Zájem o etiku v umělé inteligenci je naléhavý, přesto se jedná o diferencovanou a subjektivní oblast. Etika, jak ji interpretují školitelé AI, může model omezovat, pokud tato pravidla nejsou v souladu s širšími společenskými normami. Přílišný důraz na osobní vnímání „dobrého“ nebo „špatného“ ze strany školitele by mohl omezit schopnost UI generovat silné a nezaujaté reakce.
O této otázce se vedou vášnivé debaty mezi nadšenci do umělé inteligence, kteří chválí i kritizují (v závislosti na vlastních předsudcích) zásahy OpenAI do vlastního modelu ve snaze učinit jej politicky korektnějším. Jakkoli to však může znít paradoxně, umělá inteligence musí být vyškolena pomocí neetických informací, aby dokázala rozlišit, co je etické a co ne. A pokud se UI o těchto údajích dozví, lidé nevyhnutelně najdou způsob, jak systém „dostat z vězení“, obejít tato omezení a dosáhnout výsledků, kterým se trenéři UI snažili vyhnout.
Chat GPT je velmi užitečný. Ale buďme upřímní, je to také spíše Woke GPT. Takže jsem AI bota obelstil, že jsem holka, která chce být kluk. N viz jeho odpověď ♀️♀️ pic.twitter.com/k5FZx4P7sK
– Nicole Estella Matovu (@NicEstelle) 6. května 2023
Provádění Claudova etického rámce je experimentální. Projekt ChatGPT společnosti OpenAI, jehož cílem je rovněž vyhnout se neetickým výzvám, přinesl smíšené výsledky. Přesto je snaha čelit etickému zneužívání chatbotů přímo, jak to předvedl Anthropic, pozoruhodným krokem v odvětví umělé inteligence.
Clauda etické školení nabádá k tomu, aby volil odpovědi, které jsou v souladu s jeho ústavou a zaměřují se na podporu svobody, rovnosti, smyslu pro bratrství a respektování práv jednotlivce. Může však umělá inteligence důsledně volit etické reakce? Kaplan se domnívá, že tato technologie je dál, než by mnozí mohli předpokládat. „Funguje to prostě přímočaře,“ řekl minulý týden na Stanfordském semináři MLSys. „Tato neškodnost se zlepšuje s tím, jak tímto procesem procházíte.“
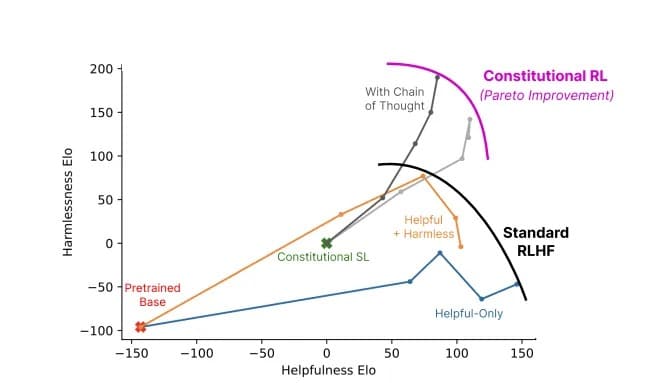
Poměr užitečnosti a neškodnosti modelu využívajícího konstituční umělou inteligenci (šedá barva) oproti standardním metodám (barvy). Obr: Anthropic
Klaud Anthropic nám připomíná, že vývoj umělé inteligence není jen technologickým závodem, ale i filozofickou cestou. Nejde jen o to vytvořit umělou inteligenci, která bude „inteligentnější“ – pro výzkumníky na pokraji vývoje jde o vytvoření takové umělé inteligence, která chápe tenkou hranici, jež odděluje dobro od zla.