
In de race om de ontwikkeling van geavanceerde kunstmatige intelligentie zijn niet alle grote taalmodellen gelijk. Twee nieuwe onderzoeken onthullen opvallende verschillen in de capaciteiten van populaire systemen zoals ChatGPT wanneer ze op de proef worden gesteld met complexe taken in de echte wereld.
Volgens onderzoekers van de Purdue University heeft ChatGPT zelfs moeite met basale coderingsuitdagingen. Het team evalueerde de antwoorden van ChatGPT op meer dan 500 vragen op Stack Overflow, een online community voor ontwikkelaars en programmeurs, over onderwerpen als debuggen en API-gebruik.
“Onze analyse toont aan dat 52% van de door ChatGPT gegenereerde antwoorden onjuist zijn en 77% langdradig,” schreven de onderzoekers. “ChatGPT antwoorden hebben echter nog steeds 39,34% van de tijd de voorkeur vanwege hun uitgebreidheid en goed geformuleerde taalstijl.”
Daarentegen toont een onderzoek van UCLA en de Pepperdine University of Malibu de bekwaamheid van ChatGPT aan bij het beantwoorden van moeilijke medische examenvragen. Bij een quiz over 850 meerkeuzevragen in nefrologie, een gevorderd specialisme binnen de interne geneeskunde, scoorde ChatGPT 73% – vergelijkbaar met het slagingspercentage voor menselijke arts-assistenten.
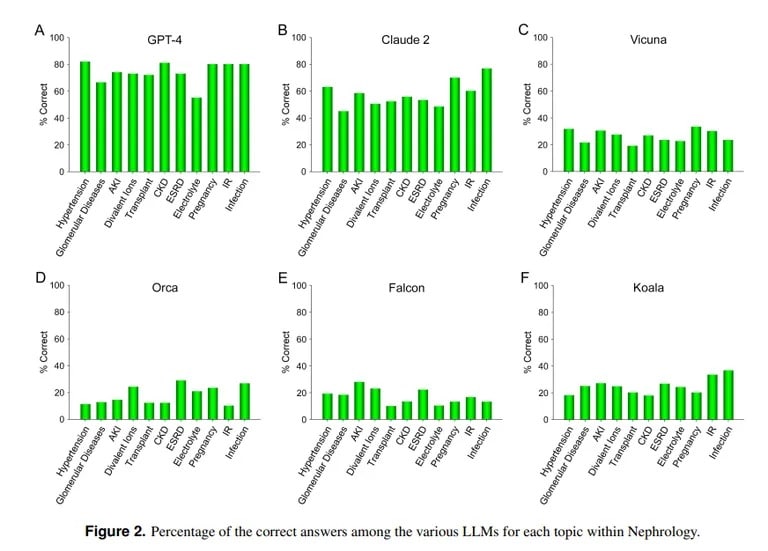
Image credit: UCLA via Arvix
“De huidige superieure capaciteit van GPT-4 in het nauwkeurig beantwoorden van meerkeuzevragen in Nefrologie wijst op het nut van soortgelijke en meer capabele AI-modellen in toekomstige medische toepassingen,” concludeerde het UCLA-team.
Anthropic’s Claude AI was de op één na beste LLM met 54,4% correcte antwoorden. Het team evalueerde andere open-source LLM’s, maar deze waren verre van acceptabel, met als beste score 25,5% behaald door Vicuna.
Dus waarom blinkt ChatGPT uit in geneeskunde, maar hapert het bij coderen? De machine learning-modellen hebben verschillende sterktes, merkt MIT computerwetenschapper Lex Fridman op. Claude, het model achter de medische kennis van ChatGPT, ontving extra eigen trainingsgegevens van zijn maker Anthropic. ChatGPT van OpenAI baseerde zich alleen op openbaar beschikbare gegevens. AI-modellen doen geweldige dingen als ze goed getraind worden met enorme hoeveelheden gegevens, zelfs beter dan de meeste andere modellen.
Image courtesy: MIT
Een AI kan echter niet goed handelen buiten de parameters waarop hij getraind is, dus zal hij proberen inhoud te creëren zonder voorkennis, wat resulteert in wat bekend staat als hallucinaties. Als de dataset van een AI-model geen specifieke inhoud bevat, zal het op dat gebied geen goede resultaten kunnen leveren.
Zoals de UCLA-onderzoekers uitlegden: “Zonder het belang van de rekenkracht van specifieke LLM’s te ontkennen, zal het gebrek aan vrije toegang tot trainingsdatamateriaal dat zich momenteel niet in het publieke domein bevindt waarschijnlijk een van de obstakels blijven voor het bereiken van verder verbeterde prestaties in de nabije toekomst.”
ChatGPT stuntelt bij het coderen en sluit aan bij andere beoordelingen. Zoals TCN eerder meldde, ontdekten onderzoekers van Stanford en UC Berkeley dat de wiskundige en visuele redeneervaardigheden van ChatGPT sterk afnamen tussen maart en juni 2022. Hoewel het aanvankelijk bedreven was in priemgetallen en puzzels, scoorde het tegen de zomer slechts 2% op belangrijke benchmarks.
Dus hoewel ChatGPT doktertje kan spelen, moet het nog veel leren voordat het een uitmuntende programmeur wordt. Maar het is niet ver van de realiteit, per slot van rekening, hoeveel dokters ken jij die ook bekwame hackers zijn?