
Im Wettlauf um die Entwicklung fortschrittlicher künstlicher Intelligenz sind nicht alle großen Sprachmodelle gleich. Zwei neue Studien zeigen eklatante Unterschiede in den Fähigkeiten beliebter Systeme wie ChatGPT, wenn sie bei komplexen realen Aufgaben auf die Probe gestellt werden.
Nach Angaben von Forschern der Purdue University hat ChatGPT selbst mit grundlegenden Codierungsaufgaben Schwierigkeiten. Das Team bewertete ChatGPTs Antworten auf über 500 Fragen auf Stack Overflow, einer Online-Community für Entwickler und Programmierer, zu Themen wie Debugging und API-Nutzung.
„Unsere Analyse zeigt, dass 52 % der von ChatGPT generierten Antworten falsch und 77 % ausführlich sind“, schreiben die Forscher. „Dennoch werden ChatGPT-Antworten in 39,34% der Fälle aufgrund ihrer Ausführlichkeit und ihres gut artikulierten Sprachstils bevorzugt. „
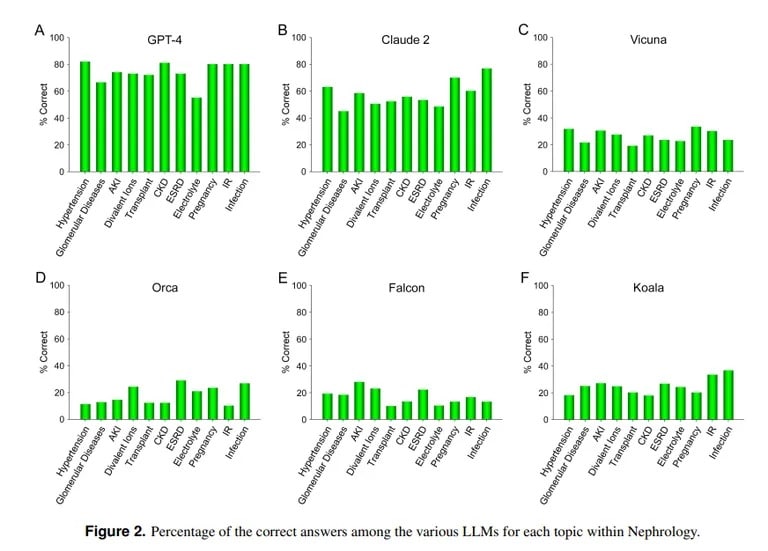
Eine Studie der UCLA und der Pepperdine University of Malibu zeigt dagegen, dass ChatGPT bei der Beantwortung schwieriger medizinischer Prüfungsfragen erfolgreich ist. Bei der Beantwortung von mehr als 850 Multiple-Choice-Fragen in der Nephrologie, einem fortgeschrittenen Fachgebiet der inneren Medizin, erzielte ChatGPT 73% – ähnlich der Bestehensquote von menschlichen Assistenzärzten.
Bildnachweis: UCLA via Arvix
„Die nachgewiesene derzeitige Überlegenheit von GPT-4 bei der genauen Beantwortung von Multiple-Choice-Fragen in der Nephrologie deutet auf den Nutzen ähnlicher und leistungsfähigerer KI-Modelle in zukünftigen medizinischen Anwendungen hin“, so das UCLA-Team abschließend.
Die KI Claude von Anthropic war mit 54,4 % richtigen Antworten das zweitbeste LLM. Das Team bewertete andere quelloffene LLMs, die jedoch bei weitem nicht akzeptabel waren, wobei Vicuna mit 25,5 % das beste Ergebnis erzielte.
Warum ist ChatGPT so gut in der Medizin, aber so schlecht in der Programmierung? Die Modelle des maschinellen Lernens haben unterschiedliche Stärken, erklärt der MIT-Informatiker Lex Fridman. Claude, das Modell hinter ChatGPTs medizinischem Wissen, erhielt zusätzliche proprietäre Trainingsdaten von seinem Hersteller Anthropic. Das ChatGPT von OpenAI stützte sich nur auf öffentlich verfügbare Daten. KI-Modelle leisten Großartiges, wenn sie richtig mit großen Datenmengen trainiert werden, und zwar besser als die meisten anderen Modelle.
Image courtesy: MIT
Eine KI ist jedoch nicht in der Lage, außerhalb der Parameter, auf die sie trainiert wurde, richtig zu agieren, also wird sie versuchen, Inhalte ohne Vorwissen zu erstellen, was zu so genannten Halluzinationen führt. Wenn der Datensatz eines KI-Modells einen bestimmten Inhalt nicht enthält, kann es in diesem Bereich keine guten Ergebnisse erzielen.
Die UCLA-Forscher erklärten: „Ohne die Bedeutung der Rechenleistung bestimmter LLMs zu negieren, wird der Mangel an freiem Zugang zu Trainingsdatenmaterial, das derzeit nicht öffentlich zugänglich ist, wahrscheinlich eines der Hindernisse für eine weitere Leistungssteigerung in absehbarer Zukunft bleiben.“
Das Scheitern von ChatGPT bei der Codierung deckt sich mit anderen Bewertungen. Wie TCN bereits berichtete, stellten Forscher der Stanford und der UC Berkeley fest, dass die mathematischen und visuellen Fähigkeiten von ChatGPT zwischen März und Juni 2022 stark abgenommen haben. Obwohl es anfangs bei Primzahlen und Rätseln gut abschnitt, erreichte es im Sommer nur noch 2 % bei wichtigen Benchmarks.
ChatGPT kann zwar Doktor spielen, muss aber noch viel lernen, bevor es ein hervorragender Programmierer wird. Aber das ist nicht weit von der Realität entfernt, denn wie viele Ärzte kennen Sie, die auch fähige Hacker sind?