
W wyścigu o rozwój zaawansowanej sztucznej inteligencji nie wszystkie duże modele językowe są sobie równe. Dwa nowe badania ujawniają uderzające różnice w możliwościach popularnych systemów, takich jak ChatGPT, podczas testowania złożonych zadań w świecie rzeczywistym.
Według naukowców z Purdue University, ChatGPT zmaga się nawet z podstawowymi wyzwaniami związanymi z kodowaniem. Zespół ocenił odpowiedzi ChatGPT na ponad 500 pytań na Stack Overflow, internetowej społeczności dla programistów i programistów, na tematy takie jak debugowanie i korzystanie z API.
„Nasza analiza pokazuje, że 52% odpowiedzi wygenerowanych przez ChatGPT jest nieprawidłowych, a 77% jest rozwlekłych” – napisali naukowcy. „Jednak odpowiedzi ChatGPT są nadal preferowane w 39,34% przypadków ze względu na ich kompleksowość i dobrze sformułowany styl językowy.”
Z kolei badanie przeprowadzone przez UCLA i Pepperdine University of Malibu wykazało, że ChatGPT jest w stanie odpowiedzieć na trudne pytania z egzaminów medycznych. Podczas quizu na ponad 850 pytań wielokrotnego wyboru z nefrologii, zaawansowanej specjalizacji w ramach medycyny wewnętrznej, ChatGPT uzyskał wynik 73% – podobny do wskaźnika zdawalności dla ludzkich rezydentów medycyny.
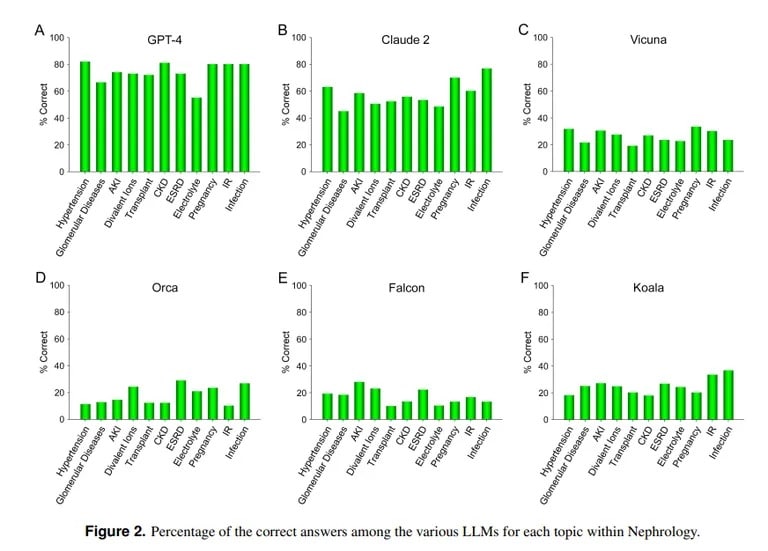
Image credit: UCLA via Arvix
„Wykazana obecnie wyższa zdolność GPT-4 do dokładnego odpowiadania na pytania wielokrotnego wyboru w nefrologii wskazuje na użyteczność podobnych i bardziej wydajnych modeli sztucznej inteligencji w przyszłych zastosowaniach medycznych” – podsumował zespół UCLA.
Claude AI firmy Anthropic był drugim najlepszym LLM z 54,4% poprawnych odpowiedzi. Zespół ocenił inne modele LLM typu open source, ale były one dalekie od akceptowalnych, z najlepszym wynikiem 25,5% osiągniętym przez Vicunę.
Dlaczego więc ChatGPT przoduje w medycynie, ale nie radzi sobie z kodowaniem? Modele uczenia maszynowego mają różne mocne strony, zauważa informatyk z MIT Lex Fridman. Claude, model stojący za wiedzą medyczną ChatGPT, otrzymał dodatkowe zastrzeżone dane szkoleniowe od swojego producenta Anthropic. ChatGPT OpenAI opierał się wyłącznie na publicznie dostępnych danych. Modele AI robią świetne rzeczy, jeśli są odpowiednio trenowane z ogromnymi ilościami danych, nawet lepiej niż większość innych modeli.
Zdjęcie dzięki uprzejmości: MIT
Jednak sztuczna inteligencja nie będzie w stanie działać poprawnie poza parametrami, na których została przeszkolona, więc będzie próbowała tworzyć treści bez wcześniejszej wiedzy na ich temat, co skutkuje tak zwanymi halucynacjami. Jeśli zbiór danych modelu sztucznej inteligencji nie zawiera określonej treści, nie będzie on w stanie uzyskać dobrych wyników w tym obszarze.
Jak wyjaśnili naukowcy z UCLA: „Nie negując znaczenia mocy obliczeniowej konkretnych LLM, brak swobodnego dostępu do danych szkoleniowych, które obecnie nie są w domenie publicznej, prawdopodobnie pozostanie jedną z przeszkód w osiągnięciu dalszej poprawy wydajności w dającej się przewidzieć przyszłości”.
ChatGPT nie radzi sobie z kodowaniem, co jest zgodne z innymi ocenami. Jak wcześniej informował TCN, naukowcy ze Stanford i UC Berkeley odkryli, że umiejętności matematyczne i wizualne ChatGPT gwałtownie spadły między marcem a czerwcem 2022 roku. Choć początkowo był biegły w liczbach pierwszych i łamigłówkach, latem uzyskał tylko 2% punktów w kluczowych testach porównawczych.
Tak więc, chociaż ChatGPT może bawić się w lekarza, wciąż musi się wiele nauczyć, zanim stanie się doskonałym programistą. Ale nie jest to dalekie od rzeczywistości, w końcu ilu znasz lekarzy, którzy są również biegłymi hakerami?