
在开发先进人工智能的竞赛中,并非所有大型语言模型都是一样的。两项新研究揭示了 ChatGPT 等流行系统在复杂的实际任务测试中能力的显著差异。
普渡大学的研究人员指出,ChatGPT 甚至连基本的编码挑战都难以应付。研究小组评估了 ChatGPT 对开发人员和程序员在线社区 Stack Overflow 上 500 多个问题的回答,这些问题涉及调试和 API 使用等主题。
“研究人员写道:”我们的分析表明,在 ChatGPT 生成的答案中,52% 是错误的,77% 是冗长的。”然而,由于 ChatGPT 答案的全面性和清晰的语言风格,在 39.34% 的情况下,ChatGPT 答案仍然是首选。
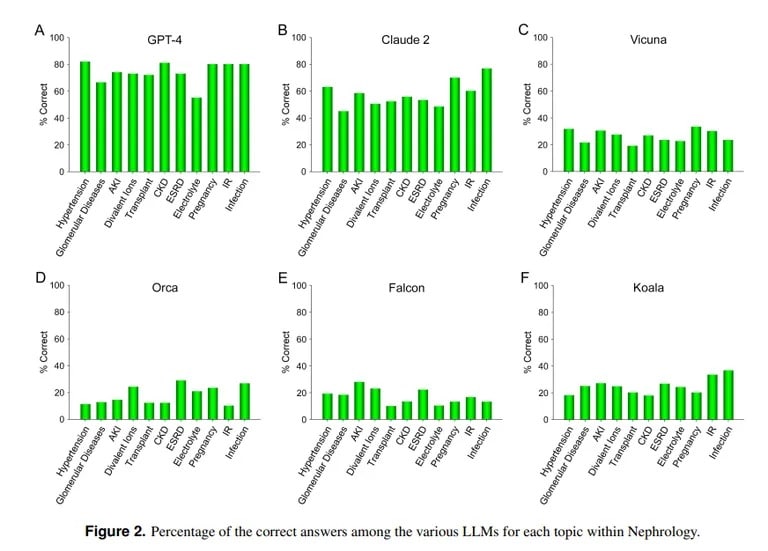
相比之下,加州大学洛杉矶分校和马里布佩珀代因大学的一项研究则证明了 ChatGPT 在回答医学考试难题方面的优势。在回答肾脏病学(内科的一个高级专业)的 850 多道选择题时,ChatGPT 的得分率为 73%,与人类医学住院医生的及格率相似。
图片来源:加州大学洛杉矶分校通过 Arvix
“GPT-4目前在准确回答肾脏病学多项选择题方面表现出的卓越能力表明,在未来的医疗应用中,类似的、能力更强的人工智能模型将大有用武之地,”加州大学洛杉矶分校团队总结道。
Anthropic 的克劳德人工智能以 54.4% 的正确率位居第二。研究小组还评估了其他开源 LLM,但它们的表现都差强人意,其中 Vicuna 的得分最高,为 25.5%。
那么,为什么 ChatGPT 在医学方面表现出色,而在编码方面却一筹莫展呢?麻省理工学院计算机科学家莱克斯-弗里德曼(Lex Fridman)指出,机器学习模型各有所长。ChatGPT 医学知识背后的模型 Claude 从其制造商 Anthropic 那里获得了额外的专有训练数据。而 OpenAI 的 ChatGPT 仅依赖公开数据。如果利用海量数据进行适当的训练,人工智能模型将大有作为,甚至优于大多数其他模型。
Image courtesy: MIT
然而,人工智能无法在其训练参数之外正常行动,因此它会在事先一无所知的情况下尝试创建内容,这就是所谓的幻觉。如果人工智能模型的数据集不包括特定内容,那么它就无法在该领域取得好成绩。
正如加州大学洛杉矶分校研究人员解释的那样:”在不否定特定乐虎国际客户端下载计算能力重要性的前提下,在可预见的未来,缺乏对目前不属于公共领域的训练数据资料的免费访问可能仍将是实现性能进一步提高的障碍之一。”
ChatGPT 在编码方面的笨拙与其他评估不谋而合。据 TCN 此前报道,斯坦福大学和加州大学伯克利分校的研究人员发现,ChatGPT 的数学和视觉推理能力在 2022 年 3 月至 6 月期间急剧下降。虽然 ChatGPT 最初擅长素数和拼图,但到了夏天,它在关键基准上的得分仅为 2%。
因此,虽然 ChatGPT 可以扮演医生,但在成为王牌程序员之前,它还有很多东西要学。但这离现实并不遥远,毕竟,你认识多少同时也是精通黑客的医生呢?