
V závodě o vývoj pokročilé umělé inteligence nejsou všechny velké jazykové modely stejné. Dvě nové studie odhalují nápadné rozdíly ve schopnostech populárních systémů, jako je ChatGPT, když jsou podrobeny zkoušce na složitých reálných úlohách.
Podle výzkumníků z Purdue University má ChatGPT problémy i se základními kódovacími úlohami. Tým hodnotil odpovědi ChatGPT na více než 500 otázek na Stack Overflow, online komunitě pro vývojáře a programátory, na témata jako ladění a používání API.
„Naše analýza ukázala, že 52 % odpovědí generovaných ChatGPT je nesprávných a 77 % je mnohomluvných,“ napsali výzkumníci. „Nicméně odpovědi ChatGPT jsou stále preferovány v 39,34 % případů díky své komplexnosti a dobře formulovanému stylu jazyka.“
Studie z UCLA a Pepperdinské univerzity v Malibu naproti tomu prokazuje zdatnost ChatGPT při odpovídání na obtížné otázky lékařské zkoušky. Při testu na více než 850 otázek s výběrem odpovědí z nefrologie, což je pokročilá specializace v rámci interní medicíny, dosáhl ChatGPT 73 % bodů – podobně jako u lidských lékařských rezidentů.
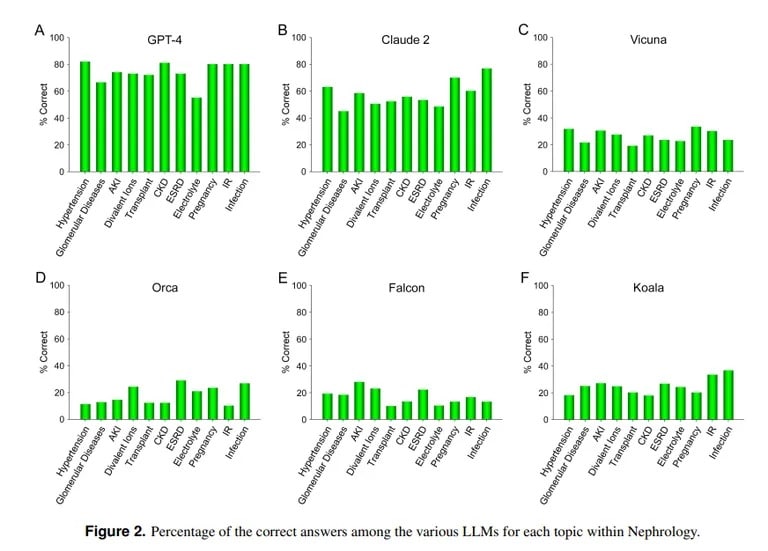
Image credit: UCLA via Arvix
„Prokázaná současná vynikající schopnost GPT-4 přesně odpovídat na otázky s výběrem odpovědí v nefrologii ukazuje na užitečnost podobných a schopnějších modelů umělé inteligence v budoucích lékařských aplikacích,“ uzavírá tým UCLA.
Druhým nejlepším LLM se stal Claude AI společnosti Anthropic s 54,4 % správných odpovědí. Tým hodnotil i další LLM s otevřeným zdrojovým kódem, které však zdaleka nebyly přijatelné, přičemž nejlepšího skóre 25,5 % dosáhla Vicuna.
Proč tedy ChatGPT vyniká v medicíně, ale tápe v kódování? Modely strojového učení mají různé silné stránky, poznamenává počítačový vědec z MIT Lex Fridman. Claude, model, který stojí za lékařskými znalostmi ChatGPT, získal od svého tvůrce, společnosti Anthropic, další patentovaná tréninková data. ChatGPT od OpenAI se spoléhal pouze na veřejně dostupná data. Modely umělé inteligence dokážou skvělé věci, pokud jsou správně vyškoleny na obrovském množství dat, dokonce lépe než většina ostatních modelů.
Obrázek s laskavým svolením: MIT
Umělá inteligence však nebude schopna správně jednat mimo parametry, na kterých byla vyškolena, takže se bude snažit vytvářet obsah bez předchozí znalosti, což vede k tzv. halucinacím. Pokud soubor dat modelu UI neobsahuje určitý obsah, nebude schopen v této oblasti dosahovat dobrých výsledků.
Jak vysvětlili výzkumníci z UCLA: „Aniž bychom popírali význam výpočetního výkonu konkrétních LLM, nedostatek volného přístupu k tréninkovému datovému materiálu, který v současné době není veřejně dostupný, pravděpodobně zůstane v dohledné budoucnosti jednou z překážek pro dosažení dalšího zlepšení výkonu.“
ChatGPT clunking at coding se shoduje s dalšími hodnoceními. Jak TCN již dříve informoval, výzkumníci ze Stanfordu a Kalifornské univerzity v Berkeley zjistili, že matematické a vizuální dovednosti ChatGPT se mezi březnem a červnem 2022 prudce zhoršily. Ačkoli zpočátku byla zdatná v řešení prvočísel a hádanek, v létě dosáhla v klíčových kritériích pouze 2 %.
ChatGPT si tedy sice umí hrát na doktora, ale než se stane programátorským esem, musí se ještě hodně učit. Ale není to daleko od reality, koneckonců kolik znáte lékařů, kteří jsou zároveň zdatnými hackery?