
Nella corsa allo sviluppo di un’intelligenza artificiale avanzata, non tutti i modelli linguistici di grandi dimensioni sono uguali. Due nuovi studi rivelano differenze sorprendenti nelle capacità di sistemi popolari come ChatGPT quando vengono messi alla prova su compiti complessi del mondo reale.
Secondo i ricercatori della Purdue University, ChatGPT ha difficoltà anche nelle sfide di codifica di base. Il team ha valutato le risposte di ChatGPT a oltre 500 domande su Stack Overflow, una comunità online per sviluppatori e programmatori, su argomenti come il debug e l’uso delle API.
“La nostra analisi mostra che il 52% delle risposte generate da ChatGPT non sono corrette e il 77% sono prolisse”, scrivono i ricercatori. “Tuttavia, le risposte di ChatGPT sono ancora preferite nel 39,34% dei casi, grazie alla loro completezza e allo stile linguistico ben articolato. “
Uno studio condotto dall’UCLA e dalla Pepperdine University di Malibu dimostra invece la bravura di ChatGPT nel rispondere a domande difficili di esami medici. Quando è stato interrogato su oltre 850 domande a scelta multipla di nefrologia, una specialità avanzata della medicina interna, ChatGPT ha ottenuto un punteggio del 73%, simile al tasso di superamento degli specializzandi in medicina umani.
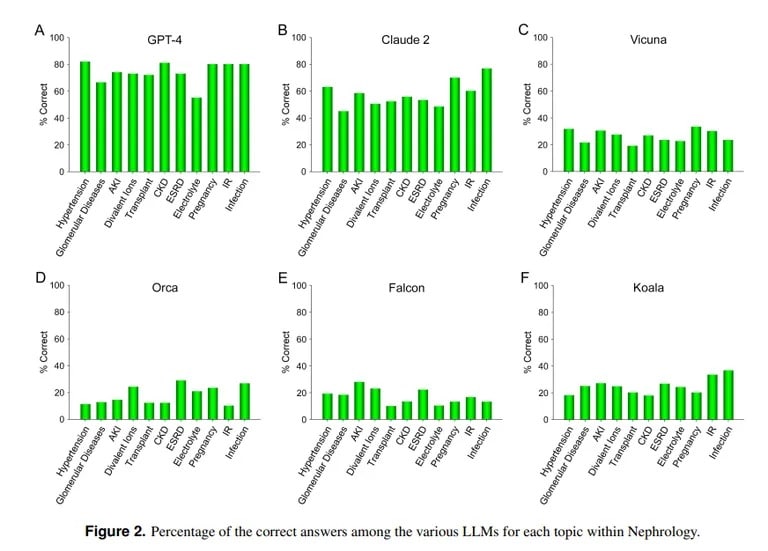
Crediti immagine: UCLA via Arvix
“La dimostrata capacità superiore di GPT-4 nel rispondere accuratamente a domande a scelta multipla in Nefrologia fa pensare all’utilità di modelli di IA simili e più capaci in applicazioni mediche future”, ha concluso il team dell’UCLA.
Claude AI di Anthropic è stato il secondo miglior LLM con il 54,4% di risposte corrette. Il team ha valutato altri LLM open-source, ma i risultati sono stati tutt’altro che accettabili: il miglior punteggio è stato ottenuto da Vicuna con il 25,5%.
Perché ChatGPT eccelle in medicina, ma non è all’altezza della codifica? I modelli di apprendimento automatico hanno punti di forza diversi, osserva l’informatico del MIT Lex Fridman. Claude, il modello alla base delle conoscenze mediche di ChatGPT, ha ricevuto ulteriori dati di addestramento proprietari dal suo produttore Anthropic. ChatGPT di OpenAI si è basato solo su dati disponibili pubblicamente. I modelli di intelligenza artificiale fanno grandi cose se addestrati correttamente con enormi quantità di dati, persino meglio della maggior parte degli altri modelli.
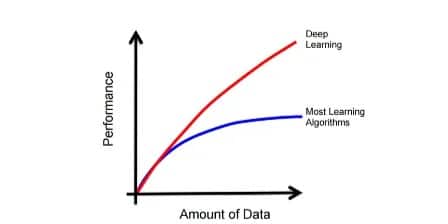
Immagine per gentile concessione: MIT
Tuttavia, un’IA non sarà in grado di agire correttamente al di fuori dei parametri su cui è stata addestrata, quindi cercherà di creare contenuti senza alcuna conoscenza preliminare, il che si traduce nelle cosiddette allucinazioni. Se il set di dati di un modello di intelligenza artificiale non include un contenuto specifico, non sarà in grado di produrre buoni risultati in quell’area.
Come hanno spiegato i ricercatori dell’UCLA, “senza negare l’importanza della potenza di calcolo di specifici LLM, la mancanza di libero accesso a materiale di dati di addestramento che attualmente non è di dominio pubblico rimarrà probabilmente uno degli ostacoli al raggiungimento di prestazioni ulteriormente migliorate per il prossimo futuro”.
L’incapacità di codifica di ChatGPT è in linea con altre valutazioni. Come riportato in precedenza da TCN, i ricercatori di Stanford e UC Berkeley hanno riscontrato che le capacità di ragionamento matematico e visivo di ChatGPT sono diminuite drasticamente tra marzo e giugno 2022. Sebbene inizialmente abile con i numeri primi e i rompicapo, entro l’estate ha ottenuto solo il 2% dei punti di riferimento.
Quindi, anche se ChatGPT è in grado di giocare al dottore, ha ancora molto da imparare prima di diventare un programmatore eccellente. Ma non è lontano dalla realtà, dopo tutto, quanti medici conoscete che siano anche hacker esperti?