
En la carrera por desarrollar inteligencia artificial avanzada, no todos los grandes modelos lingüísticos son iguales. Dos nuevos estudios revelan sorprendentes diferencias en las capacidades de sistemas tan populares como ChatGPT cuando se ponen a prueba en tareas complejas del mundo real.
Según los investigadores de la Universidad de Purdue, ChatGPT tiene dificultades incluso con los retos básicos de codificación. El equipo evaluó las respuestas de ChatGPT a más de 500 preguntas en Stack Overflow, una comunidad en línea para desarrolladores y programadores, sobre temas como depuración y uso de API.
«Nuestro análisis muestra que el 52% de las respuestas generadas por ChatGPT son incorrectas y el 77% son verbales», escribieron los investigadores. «Sin embargo, las respuestas de ChatGPT siguen siendo las preferidas el 39,34% de las veces debido a su exhaustividad y a su estilo de lenguaje bien articulado».
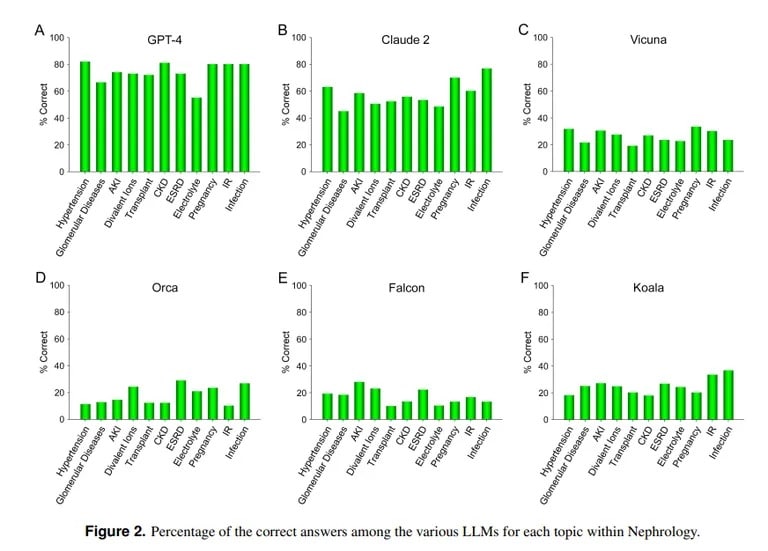
En cambio, un estudio de la UCLA y la Universidad Pepperdine de Malibú demuestra la destreza de ChatGPT para responder a preguntas difíciles de exámenes médicos. Cuando se le plantearon más de 850 preguntas de opción múltiple sobre nefrología, una especialidad avanzada dentro de la medicina interna, ChatGPT obtuvo una puntuación del 73%, similar a la tasa de aprobados de los médicos residentes humanos.
Crédito de la imagen: UCLA vía Arvix
«La capacidad superior demostrada actualmente por GPT-4 para responder con precisión a preguntas de opción múltiple en Nefrología apunta a la utilidad de modelos de IA similares y más capaces en futuras aplicaciones médicas», concluye el equipo de la UCLA.
Claude AI, de Anthropic, fue el segundo mejor LLM, con un 54,4% de respuestas correctas. El equipo evaluó otros LLM de código abierto, pero estaban lejos de ser aceptables, siendo la mejor puntuación el 25,5% logrado por Vicuna.
¿Por qué ChatGPT destaca en medicina y fracasa en codificación? Los modelos de aprendizaje automático tienen puntos fuertes diferentes, señala el informático del MIT Lex Fridman. Claude, el modelo que está detrás de los conocimientos médicos de ChatGPT, recibió datos de entrenamiento propios adicionales de su fabricante, Anthropic. ChatGPT, de OpenAI, se basó únicamente en datos públicos. Los modelos de IA hacen grandes cosas si se entrenan adecuadamente con grandes cantidades de datos, incluso mejor que la mayoría de los modelos.
Imagen cortesía: MIT
Sin embargo, una IA no será capaz de actuar correctamente fuera de los parámetros en los que fue entrenada, por lo que intentará crear contenidos sin conocimiento previo de los mismos, lo que da lugar a lo que se conoce como alucinaciones. Si el conjunto de datos de un modelo de IA no incluye un contenido específico, no podrá dar buenos resultados en ese ámbito.
Como explican los investigadores de la UCLA, «sin negar la importancia de la potencia computacional de los LLM específicos, la falta de libre acceso a material de datos de entrenamiento que actualmente no es de dominio público seguirá siendo probablemente uno de los obstáculos para conseguir mejorar el rendimiento en un futuro previsible.»
El traqueteo de ChatGPT en la codificación coincide con otras evaluaciones. Como TCN informó anteriormente, investigadores de Stanford y UC Berkeley descubrieron que las habilidades matemáticas y de razonamiento visual de ChatGPT disminuyeron drásticamente entre marzo y junio de 2022. Aunque al principio era experto en números primos y rompecabezas, en verano solo obtuvo un 2% de puntos de referencia clave.
Así que, aunque ChatGPT puede jugar a los médicos, aún tiene mucho que aprender antes de convertirse en un programador experto. Pero no está lejos de la realidad, después de todo, ¿cuántos médicos conoces que también sean hackers competentes?