
В гонке за создание передового искусственного интеллекта не все большие языковые модели созданы одинаковыми. Два новых исследования показывают разительные различия в возможностях таких популярных систем, как ChatGPT, при решении сложных реальных задач.
По данным исследователей из Университета Пердью, ChatGPT не справляется даже с базовыми задачами кодирования. Группа исследователей оценила ответы ChatGPT на более чем 500 вопросов на Stack Overflow, онлайн-сообществе для разработчиков и программистов, по таким темам, как отладка и использование API.
«Наш анализ показал, что 52% ответов, сгенерированных ChatGPT, являются неправильными, а 77% — многословными», — пишут исследователи. «Однако ответы ChatGPT все равно предпочтительнее в 39,34% случаев благодаря их полноте и хорошо сформулированному стилю языка.»
В отличие от этого, исследование, проведенное Калифорнийским университетом и Университетом Пеппердайн в Малибу, демонстрирует превосходство ChatGPT в ответах на сложные вопросы медицинских экзаменов. При ответе на более чем 850 вопросов с несколькими вариантами ответов по нефрологии — углубленной специализации в области внутренней медицины — ChatGPT набрал 73%, что соответствует уровню сдачи экзамена для резидентов-медиков
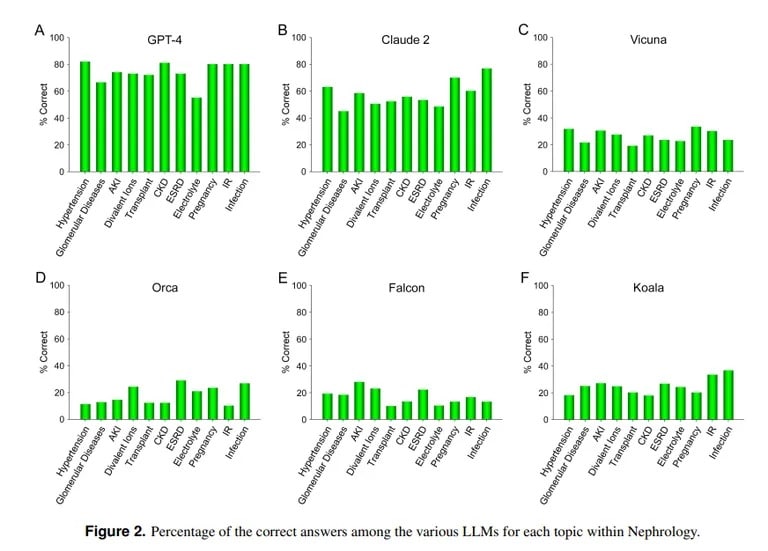
Image credit: UCLA via Arvix
«Продемонстрированные в настоящее время превосходные возможности GPT-4 в точном ответе на вопросы с несколькими вариантами ответов в нефрологии указывают на целесообразность использования подобных и более способных моделей ИИ в будущих медицинских приложениях», — заключили специалисты Калифорнийского университета.
ИИ Claude компании Anthropic стал вторым лучшим ИИ с 54,4% правильных ответов. Команда оценивала и другие открытые ИИ, но их результаты были далеки от приемлемых: лучший результат — 25,5% — был получен от Vicuna.
Почему же ChatGPT преуспевает в медицине и не справляется с кодированием? Модели машинного обучения имеют разные сильные стороны, отмечает Лекс Фридман, специалист по информатике Массачусетского технологического института. Claude, модель, обеспечивающая медицинские знания ChatGPT, получила дополнительные собственные обучающие данные от своего создателя Anthropic. Модель ChatGPT от OpenAI опиралась только на общедоступные данные. Модели искусственного интеллекта при правильном обучении на огромных объемах данных делают отличные вещи, даже лучше, чем большинство других моделей.
Image courtesy: MIT
Однако ИИ не сможет правильно действовать вне тех параметров, на которые он был обучен, поэтому он будет пытаться создавать контент без предварительных знаний о нем, что приводит к так называемым галлюцинациям. Если в наборе данных модели ИИ нет определенного контента, то она не сможет добиться хороших результатов в этой области.
Как пояснили исследователи из Калифорнийского университета, «не отрицая важности вычислительной мощности конкретных ИИ, отсутствие свободного доступа к материалам обучающих данных, которые в настоящее время не являются общественным достоянием, вероятно, останется одним из препятствий для достижения дальнейшего повышения производительности в обозримом будущем».
Неудачи ChatGPT при кодировании согласуются с другими оценками. Как уже сообщало агентство TCN, исследователи из Стэнфорда и Калифорнийского университета в Беркли обнаружили, что в период с марта по июнь 2022 года уровень математических и визуальных способностей ChatGPT резко снизился. Хотя вначале ChatGPT хорошо разбирался в простых задачах и головоломках, к лету он набрал всего 2% по ключевым показателям.
Таким образом, хотя ChatGPT и умеет играть в доктора, ему еще предстоит многому научиться, прежде чем он станет искусным программистом. Но это не так уж и далеко от реальности: в конце концов, много ли вы знаете врачей, которые одновременно являются и умелыми хакерами?