
OpenAI hat einen neuen Web-Crawling-Bot, GPTBot, veröffentlicht, um seinen Datensatz für das Training der nächsten Generation von KI-Systemen zu erweitern – und die nächste Iteration hat offenbar einen offiziellen Namen. Das Unternehmen hat sich den Begriff „GPT-5“ schützen lassen, was auf eine bevorstehende Veröffentlichung hindeutet und gleichzeitig Web-Publishern eine Vorwarnung gibt, wie sie ihre Inhalte aus dem riesigen Korpus heraushalten können.
Laut OpenAI wird der Web-Crawler öffentlich zugängliche Daten von Websites sammeln, während er kostenpflichtige, sensible und verbotene Inhalte vermeidet. Ähnlich wie bei anderen Suchmaschinen wie Google, Bing und Yandex ist das System jedoch opt-out – standardmäßig geht GPTBot davon aus, dass zugängliche Informationen Freiwild sind. Um zu verhindern, dass der Web-Crawler von OpenAI eine Website aufnimmt, muss der Besitzer eine „disallow“-Regel in eine Standarddatei auf dem Server einfügen.
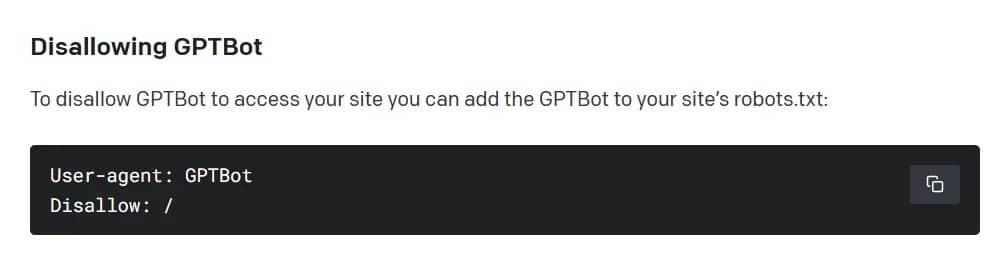
Wie man OpenAIs GPTBot verbietet. Bild: OpenAI
OpenAI sagt auch, dass GPTBot die gescannten Daten präventiv scannt, um persönlich identifizierbare Informationen (PII) und Text, der gegen seine Richtlinien verstößt, zu entfernen.
Einigen Technologieethikern zufolge wirft der Opt-Out-Ansatz jedoch immer noch Fragen der Zustimmung auf.
Auf Hacker News rechtfertigten einige Nutzer den Schritt von OpenAI damit, dass das Unternehmen alles sammeln muss, was es kann, wenn die Menschen in Zukunft ein fähiges generatives KI-Tool haben wollen. „Sie brauchen immer noch aktuelle Daten, oder ihre GPT-Modelle werden für immer im September 2021 stecken bleiben“, sagte ein Nutzer. Ein anderer, datenschutzbewussterer Nutzer argumentierte, dass „OpenAI nicht einmal in Maßen zitiert. Es macht ein abgeleitetes Werk ohne Zitierung und macht es damit unkenntlich.“
Die Veröffentlichung von GPTBot folgt auf die jüngste Kritik daran, dass OpenAI früher Daten ohne Erlaubnis abgegriffen hat, um Large Language Models (LLMs) wie ChatGPT zu trainieren. Um diese Bedenken auszuräumen, hat das Unternehmen im April seine Datenschutzrichtlinien aktualisiert.
In der Zwischenzeit scheint ein kürzlich eingereichter Markenantrag für GPT-5 zu bestätigen, dass OpenAI sein nächstes Modell für eine zukünftige Markteinführung trainiert. Das neue System würde höchstwahrscheinlich Web-Scraping im großen Stil beinhalten, um seine Trainingsdaten zu aktualisieren und zu erweitern.
Dies könnte eine Abkehr von OpenAIs früherer Betonung von Transparenz und KI-Sicherheit bedeuten, aber es ist nicht überraschend, wenn man bedenkt, dass ChatGPT trotz eines zunehmend überfüllten und leistungsstarken Marktes das meistgenutzte LLM der Welt ist. Das Starprodukt von OpenAI – und das jedes LLM – ist nur so gut wie die Qualität der Daten, mit denen es trainiert wurde.
OpenAI braucht mehr und neuere Daten, und zwar jede Menge davon.
Auf der anderen Seite gibt es ein quelloffenes LLM, das vom Social-Media-Giganten Meta entwickelt wurde. Der Tech-Gigant hat sein Modell kostenlos zur Verfügung gestellt, solange Sie kein Konkurrent oder ein zu großes Unternehmen sind. Meta hat nicht bekannt gegeben, welche Datensätze es zum Trainieren seines Modells verwendet und welche Informationen es gesammelt hat. Der Ansatz ermöglicht es den Nutzern jedoch, das Modell mit ihren eigenen Datensätzen fein abzustimmen.
Während sich OpenAI auf alle seine gecrawlten Daten stützt, um seine Modelle zu trainieren und ein profitables Ökosystem um seine KI-Tools herum aufzubauen, bemüht sich Meta darum, ein profitables Geschäft um seine Daten herum aufzubauen. Daher verwendet Meta die Daten nicht nur, um bessere Modelle zu erstellen, sondern gibt sie auch an Dritte weiter, damit diese sie nutzen können.
„Wir verkaufen Ihre Daten nicht. Stattdessen werden wir von Werbetreibenden und anderen Partnern dafür bezahlt, Ihnen personalisierte Werbung zu zeigen“, erklärt Meta. Laut Metas Standard-Datenschutzerklärung gehören zu den Daten, die das Unternehmen sammelt, unter anderem Einkäufe, Browser-Verlauf, IDs, Finanzdaten, Kontakte und nicht offengelegte sensible Informationen.
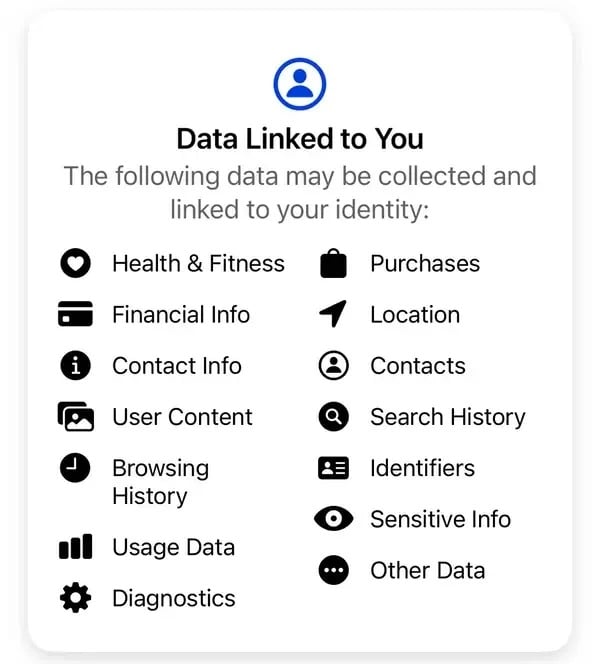
Einige der Daten, die Meta von den Nutzern seiner Thread-App sammelt. Bild: Meta
ChatGPT hat inzwischen über 1,5 Milliarden monatlich aktive Nutzer. Und Microsofts 10-Milliarden-Dollar-Investition in OpenAI scheint vorausschauend zu sein, da die ChatGPT-Integration die Fähigkeiten von Bing gesteigert hat.
Im Moment führt OpenAI den brandaktuellen Bereich der KI an, während die Tech-Giganten versuchen, aufzuholen. Der neue Web-Crawler des Unternehmens könnte die Fähigkeiten seiner Modelle weiter verbessern. Die zunehmende Datenerfassung im Internet wirft jedoch auch ethische Fragen in Bezug auf Urheberrecht und Einwilligung auf.
Da KI-Systeme immer ausgeklügelter werden, bleibt die Abwägung zwischen Transparenz, Ethik und Fähigkeiten ein komplexer Balanceakt.