
A OpenAI lançou um novo bot de rastreamento da web, o GPTBot, para expandir seu conjunto de dados para treinar sua próxima geração de sistemas de IA – e a próxima iteração aparentemente tem um nome oficial. A empresa registou o termo “GPT-5”, sugerindo um próximo lançamento, ao mesmo tempo que dá aos editores da Web um aviso sobre como manter o seu conteúdo fora do seu enorme corpus.
De acordo com a OpenAI, o rastreador da Web recolherá dados disponíveis publicamente nos sítios Web, evitando conteúdos proibidos, sensíveis e pagos. No entanto, à semelhança de outros motores de busca como o Google, o Bing e o Yandex, o sistema é opcional – por defeito, o GPTBot assume que a informação acessível é um jogo justo. Para evitar que o rastreador da web OpenAI ingira um site, o seu proprietário deve adicionar uma regra “disallow” a um ficheiro padrão no servidor.
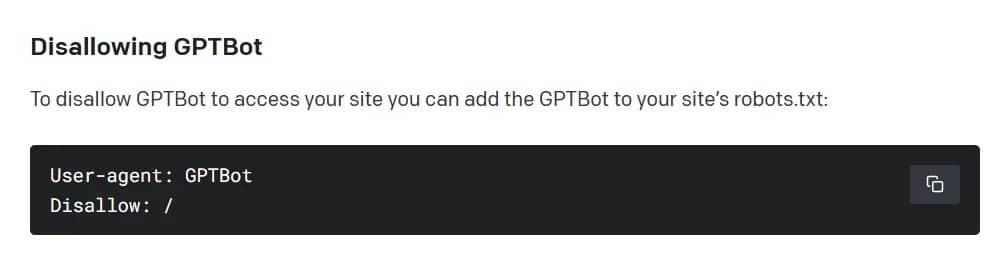
Como banir o GPTBot da OpenAI. Imagem: OpenAI
A OpenAI também afirma que o GPTBot irá analisar preventivamente os dados recolhidos para remover informações de identificação pessoal (PII) e textos que violem as suas políticas.
De acordo com alguns especialistas em ética tecnológica, no entanto, a abordagem de exclusão ainda levanta questões de consentimento.
No Hacker News, alguns utilizadores justificaram a iniciativa da OpenAI dizendo que tem de reunir tudo o que puder se as pessoas quiserem ter uma ferramenta de IA generativa capaz no futuro. “Eles ainda precisam de dados atuais ou seus modelos GPT ficarão presos em setembro de 2021 para sempre”, disse um usuário. Outro utilizador mais preocupado com a privacidade argumentou que “a OpenAI nem sequer está a citar com moderação. Está a fazer um trabalho derivado sem citar, obscurecendo-o assim”.
O lançamento do GPTBot vem na sequência de críticas recentes sobre o facto de a OpenAI ter anteriormente extraído dados sem autorização para treinar Modelos de Linguagem Grandes (LLMs) como o ChatGPT. Para responder a essas preocupações, a empresa actualizou as suas políticas de privacidade em abril.
Entretanto, um recente pedido de registo de marca para o GPT-5 parece confirmar que a OpenAI está a treinar o seu próximo modelo para um futuro lançamento. É muito provável que o novo sistema envolva a recolha de dados da Web em grande escala para atualizar e expandir os seus dados de treino.
Isto pode representar um afastamento da ênfase inicial da OpenAI na transparência e na segurança da IA, mas não é surpreendente, tendo em conta que o ChatGPT é o LLM mais utilizado no mundo, apesar de um mercado cada vez mais concorrido e potente. O produto estrela da OpenAI – e o de qualquer LLM – é tão bom quanto a qualidade dos dados utilizados para o treinar.
A OpenAI precisa de mais e mais recentes dados, e precisa de muitos.
Por outro lado, existe um LLM de código aberto, montado pelo gigante dos media sociais Meta. O gigante da tecnologia ofereceu o seu modelo gratuitamente, desde que não seja um concorrente nem uma empresa demasiado grande. A Meta não revelou quais os conjuntos de dados que utilizou para treinar o seu modelo e quais as informações que recolheu. No entanto, a abordagem permite aos utilizadores afinar o modelo utilizando os seus próprios conjuntos de dados.
Enquanto a OpenAI se baseia em todos os seus dados rastreados para treinar os seus modelos e construir um ecossistema rentável em torno das suas ferramentas de IA, a Meta está a tentar construir um negócio rentável em torno dos seus dados. Assim, a Meta não só os utiliza para criar melhores modelos, como também os partilha com terceiros para que estes os possam utilizar.
“Não vendemos as suas informações. Em vez disso, com base nas informações de que dispomos, os anunciantes e outros parceiros pagam-nos para lhe mostrarmos anúncios personalizados”, explica a Meta. De acordo com as divulgações de privacidade padrão da Meta, alguns dos dados que a empresa recolhe incluem compras, histórico do navegador, IDs, informações financeiras, contactos e informações confidenciais não reveladas, entre outros.
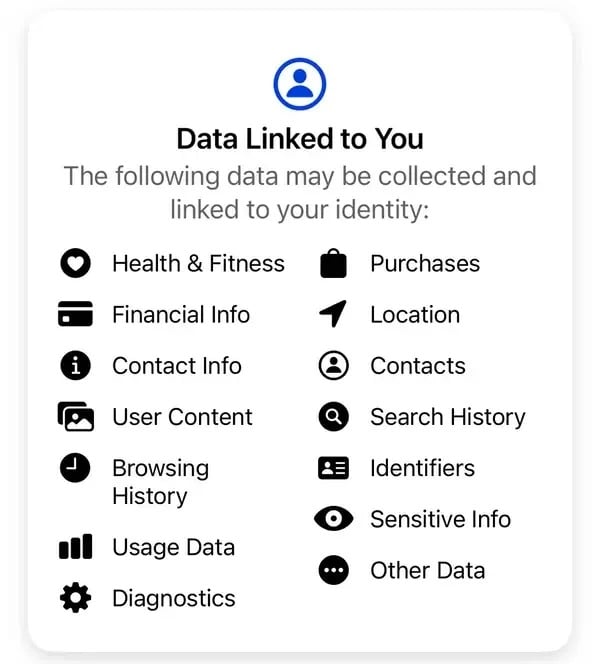
Alguns dos dados recolhidos pela Meta dos utilizadores da sua aplicação Thread. Imagem: Meta
O
ChatGPT atrai agora mais de 1,5 mil milhões de utilizadores activos mensais. E o investimento de 10 mil milhões de dólares da Microsoft na OpenAI parece ter sido feito de forma inteligente, uma vez que a integração do ChatGPT aumentou as capacidades do Bing.
Por enquanto, a OpenAI lidera o espaço da IA, com os gigantes da tecnologia a correrem para a apanhar. O novo web crawler da empresa pode aumentar ainda mais as capacidades dos seus modelos. Mas a expansão da recolha de dados na Internet também levanta questões éticas relacionadas com os direitos de autor e o consentimento.
À medida que os sistemas de IA se tornam mais sofisticados, o equilíbrio entre transparência, ética e capacidades continuará a ser um ato de equilíbrio complexo.