
OpenAI ha rilasciato un nuovo bot di web crawling, GPTBot, per espandere il suo set di dati per l’addestramento della prossima generazione di sistemi di intelligenza artificiale e, a quanto pare, la prossima iterazione ha un nome ufficiale. L’azienda ha registrato il termine “GPT-5”, alludendo a un rilascio imminente e avvisando gli editori web su come tenere i loro contenuti fuori dal suo enorme corpus.
Secondo OpenAI, il web crawler raccoglierà i dati disponibili pubblicamente dai siti web, evitando i contenuti a pagamento, sensibili e vietati. Come altri motori di ricerca come Google, Bing e Yandex, tuttavia, il sistema è di tipo opt-out: per impostazione predefinita, GPTBot presuppone che le informazioni accessibili siano un gioco da ragazzi. Per impedire al web crawler di OpenAI di ingerire un sito web, il suo proprietario deve aggiungere una regola di “disallow” a un file standard sul server.
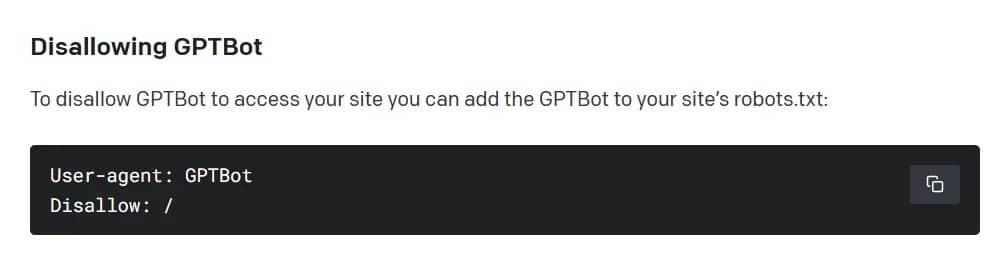
Come vietare il GPTBot di OpenAI. Immagine: OpenAI
OpenAI afferma inoltre che GPTBot esegue una scansione preventiva dei dati raccolti per rimuovere le informazioni di identificazione personale (PII) e i testi che violano le sue politiche.
Secondo alcuni etici della tecnologia, tuttavia, l’approccio opt-out solleva ancora problemi di consenso.
Su Hacker News, alcuni utenti hanno giustificato la mossa di OpenAI dicendo che deve raccogliere tutto il possibile se si vuole avere uno strumento di IA generativa capace in futuro. “Hanno ancora bisogno di dati attuali o i loro modelli GPT saranno bloccati per sempre al settembre 2021”, ha detto un utente. Un altro utente più attento alla privacy ha sostenuto che “OpenAI non sta nemmeno citando con moderazione. Sta facendo un’opera derivata senza citare, oscurandola”.
Il rilascio di GPTBot fa seguito alle recenti critiche rivolte a OpenAI, che in passato ha effettuato lo scraping di dati senza autorizzazione per addestrare modelli linguistici di grandi dimensioni (LLM) come ChatGPT. Per rispondere a queste preoccupazioni, ad aprile l’azienda ha aggiornato le sue politiche sulla privacy.
Nel frattempo, una recente richiesta di marchio per GPT-5 sembra confermare che OpenAI sta addestrando il suo prossimo modello per un lancio futuro. È molto probabile che il nuovo sistema preveda lo scraping del web su larga scala per aggiornare ed espandere i dati di addestramento.
Questo potrebbe rappresentare un allontanamento dall’enfasi iniziale di OpenAI sulla trasparenza e sulla sicurezza dell’IA, ma non sorprende se si considera che ChatGPT è il LLM più utilizzato al mondo, nonostante un mercato sempre più affollato e potente. Il prodotto di punta di OpenAI – e di qualsiasi LLM – è buono solo quanto la qualità dei dati utilizzati per addestrarlo.
OpenAI ha bisogno di più dati e di nuovi dati, e ne ha bisogno di molti.
D’altra parte, esiste un LLM open-source, assemblato dal gigante dei social media Meta. Il colosso tecnologico ha offerto il suo modello gratuitamente, a patto che non siate un concorrente o un’azienda troppo grande. Meta non ha rivelato quali set di dati ha utilizzato per addestrare il modello e quali informazioni ha raccolto. Tuttavia, l’approccio consente agli utenti di perfezionare il modello utilizzando i propri set di dati.
Mentre OpenAI si affida a tutti i dati raccolti per addestrare i propri modelli e per costruire un ecosistema redditizio attorno ai propri strumenti di intelligenza artificiale, Meta vuole costruire un’attività redditizia attorno ai propri dati. Pertanto, Meta non solo li utilizza per creare modelli migliori, ma li condivide anche con terze parti in modo che possano utilizzarli.
“Non vendiamo i vostri dati. Invece, sulla base delle informazioni in nostro possesso, gli inserzionisti e altri partner ci pagano per mostrarvi annunci personalizzati”, spiega Meta. Secondo le informazioni standard sulla privacy di Meta, alcuni dei dati raccolti dall’azienda includono acquisti, cronologia del browser, ID, informazioni finanziarie, contatti e informazioni sensibili non divulgate.
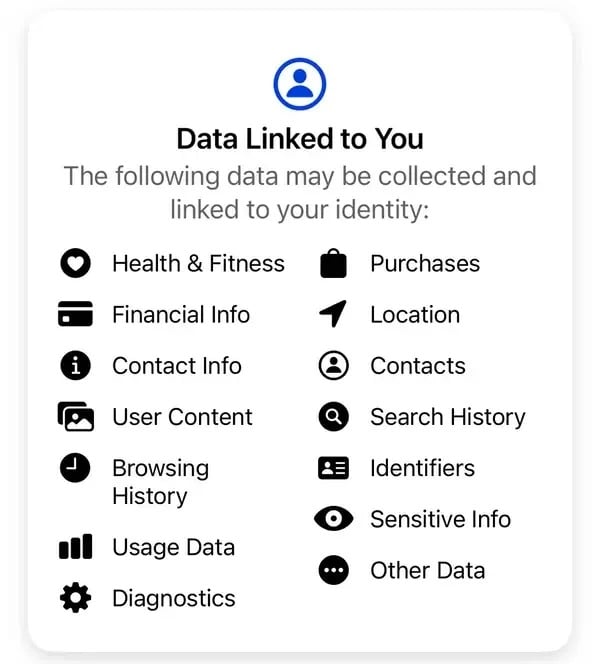
Alcuni dei dati raccolti da Meta dagli utenti della sua Thread App. Immagine: Meta
ChatGPT conta oggi oltre 1,5 miliardi di utenti attivi mensili. E l’investimento di 10 miliardi di dollari di Microsoft in OpenAI appare preveggente, dato che l’integrazione di ChatGPT ha potenziato le capacità di Bing.
Per il momento, OpenAI è in testa allo spazio dell’intelligenza artificiale, con i giganti della tecnologia in corsa per raggiungerlo. Il nuovo web crawler dell’azienda potrebbe far progredire ulteriormente le capacità dei suoi modelli. Ma l’espansione della raccolta di dati su Internet solleva anche questioni etiche legate al copyright e al consenso.
Man mano che i sistemi di IA diventano sempre più sofisticati, il bilanciamento tra trasparenza, etica e capacità rimarrà un complesso gioco di equilibri.