
OpenAI выпустила нового веб-бота GPTBot, чтобы расширить набор данных для обучения следующего поколения систем искусственного интеллекта, и, судя по всему, у следующей итерации уже есть официальное название. Компания получила торговую марку «GPT-5», намекая на предстоящий релиз и одновременно предупреждая веб-издателей о том, что их контент не должен попасть в массивную базу данных.
По словам представителей OpenAI, веб-краулер будет собирать общедоступные данные с сайтов, избегая при этом платного, конфиденциального и запрещенного контента. Как и в других поисковых системах, таких как Google, Bing и Yandex, в системе предусмотрена опция opt out — по умолчанию GPTBot будет считать, что доступная информация является честной игрой. Для того чтобы предотвратить попадание веб-сайта в базу OpenAI, его владелец должен добавить правило «disallow» в стандартный файл на сервере.
OpenAI также утверждает, что GPTBot будет предварительно сканировать полученные данные, чтобы удалить персональную информацию (PII) и текст, нарушающий политику компании.
Однако, по мнению некоторых специалистов по технологической этике, подход, основанный на отказе от использования данных, все же поднимает вопрос о согласии.
На сайте Hacker News некоторые пользователи оправдывали действия OpenAI, говоря о том, что для того, чтобы в будущем у людей был способный инструмент генеративного ИИ, необходимо собрать все возможное. «Им все равно нужны актуальные данные, иначе их GPT-модели навсегда застрянут в сентябре 2021 года», — сказал один из пользователей. Другой пользователь, более заботящийся о конфиденциальности, утверждал, что «OpenAI даже не цитирует в порядке модерации. Он делает производную работу без цитирования, тем самым затушевывая ее».
Выпуск GPTBot последовал за недавней критикой в адрес компании OpenAI, которая ранее без разрешения занималась сбором данных для обучения больших языковых моделей (LLM), таких как ChatGPT. Чтобы снять эти опасения, компания в апреле обновила свою политику конфиденциальности.
Между тем, недавняя заявка на торговую марку GPT-5, похоже, подтверждает, что OpenAI готовит свою следующую модель для будущего запуска. Вполне вероятно, что новая система будет включать в себя крупномасштабный веб-скреппинг для обновления и расширения обучающих данных.
Это может свидетельствовать об отходе OpenAI от своего раннего акцента на прозрачность и безопасность ИИ, но это неудивительно, учитывая, что ChatGPT является самым используемым LLM в мире, несмотря на все более переполненный и мощный рынок. Звездный продукт OpenAI — как и любой другой LLM — хорош лишь настолько, насколько качественны данные, используемые для его обучения.
OpenAI нужны все новые и новые данные, и их нужно много.
С другой стороны, существует LLM с открытым исходным кодом, собранный гигантом социальных сетей Meta. Этот технологический гигант предложил свою модель бесплатно, если вы не являетесь конкурентом или слишком крупным предприятием. Meta не раскрывает, какие наборы данных она использовала для обучения своей модели и какую информацию собрала. Однако такой подход позволяет пользователям проводить тонкую настройку модели на собственных наборах данных.
Если OpenAI использует все полученные данные для обучения своих моделей и создания прибыльной экосистемы вокруг своих инструментов искусственного интеллекта, то Meta стремится построить прибыльный бизнес на основе своих данных. Таким образом, Meta не только использует данные для создания более совершенных моделей, но и делится ими с третьими сторонами, чтобы они могли их использовать.
«Мы не продаем ваши данные. Вместо этого, основываясь на имеющейся у нас информации, рекламодатели и другие партнеры платят нам за показ персонализированных объявлений», — поясняет Meta. В соответствии со стандартной информацией о конфиденциальности Meta, некоторые из собираемых компанией данных включают покупки, историю браузера, идентификационные данные, финансовую информацию, контакты и нераскрытую конфиденциальную информацию, а также другие данные.
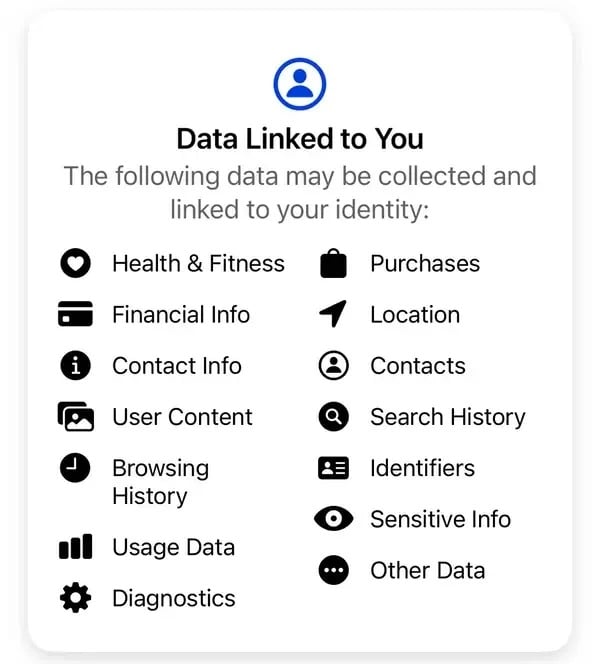
Некоторые из данных, собираемых компанией Meta у пользователей приложения Thread. Изображение: Meta
ChatGPT в настоящее время насчитывает более 1,5 млрд. ежемесячных активных пользователей. А инвестиции Microsoft в OpenAI в размере 10 млрд. долл. выглядят вполне оправданными, поскольку интеграция ChatGPT позволила расширить возможности Bing.
На данный момент OpenAI является лидером в области искусственного интеллекта, а технологические гиганты пытаются его догнать. Новый веб-краулер компании может еще больше расширить возможности ее моделей. Однако расширение сбора данных в Интернете также поднимает этические вопросы, связанные с авторским правом и согласием.
По мере того как системы искусственного интеллекта становятся все более совершенными, баланс между прозрачностью, этикой и возможностями будет оставаться сложной задачей.