
OpenAI vydala nového webového crawlingového bota GPTBot, aby rozšířila svůj datový soubor pro trénink další generace systémů umělé inteligence – a další iterace má zřejmě oficiální jméno. Společnost si nechala zaregistrovat ochrannou známku „GPT-5“, čímž naznačuje nadcházející vydání a zároveň dává webovým vydavatelům na vědomí, jak udržet svůj obsah mimo jeho masivní korpus.
Podle OpenAI bude webový crawler shromažďovat veřejně dostupná data z webových stránek, přičemž se vyhne placenému, citlivému a zakázanému obsahu. Podobně jako u jiných vyhledávačů, jako jsou Google, Bing a Yandex, je však systém opt-out – ve výchozím nastavení bude GPTBot předpokládat, že dostupné informace jsou férovou hrou. Aby webový crawler OpenAI nemohl webovou stránku načíst, musí její majitel přidat pravidlo „disallow“ do standardního souboru na serveru.
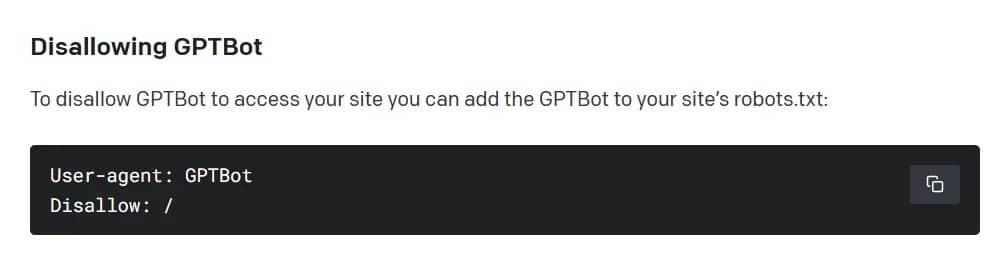
Jak zakázat GPTBot společnosti OpenAI. Obrázek: V případě, že se jedná o aplikaci GPTB, je nutné použít tzv: OpenAI
OpenAI také uvádí, že GPTBot preventivně skenuje seškrábaná data, aby odstranil osobní údaje a text, který porušuje její zásady.
Podle některých odborníků na technologickou etiku však přístup opt-out stále vyvolává otázky týkající se souhlasu.
Na serveru Hacker News někteří uživatelé zdůvodnili krok OpenAI tím, že musí shromáždit vše, co je možné, pokud lidé chtějí mít v budoucnu schopný nástroj generativní umělé inteligence. „Stále potřebují aktuální data, jinak se jejich modely GPT zaseknou na září 2021 navždy,“ uvedl jeden z uživatelů. Jiný uživatel, který se více zajímá o soukromí, tvrdil, že „OpenAI ani neuvádí moderování. Vytváří odvozené dílo bez citování, čímž ho zatemňuje.“
Zveřejnění GPTBot následuje po nedávné kritice, která se týkala toho, že OpenAI dříve bez povolení shromažďovala data pro trénování velkých jazykových modelů (LLM), jako je ChatGPT. V reakci na tyto obavy společnost v dubnu aktualizovala své zásady ochrany osobních údajů.
Mezitím se zdá, že nedávná žádost o ochrannou známku pro GPT-5 potvrzuje, že OpenAI trénuje svůj další model pro budoucí uvedení na trh. Nový systém by velmi pravděpodobně zahrnoval rozsáhlé škrabání webových stránek za účelem aktualizace a rozšíření tréninkových dat.
To by mohlo představovat odklon od počátečního důrazu OpenAI na transparentnost a bezpečnost AI, ale není to překvapivé vzhledem k tomu, že ChatGPT je nejpoužívanějším LLM na světě, a to navzdory stále přeplněnějšímu a výkonnějšímu trhu. Hvězdný produkt společnosti OpenAI – a jakéhokoli LLM – je jen tak dobrý, jak kvalitní jsou data použitá k jeho tréninku.
OpenAI potřebuje více a novějších dat a potřebuje jich hodně.
Na druhé straně existuje open-source LLM, který sestavil gigant sociálních médií Meta. Tento technologický gigant nabídl svůj model zdarma, pokud nejste konkurentem ani příliš velkou firmou. Společnost Meta nezveřejnila, jaké datové soubory použila k trénování svého modelu a jaké informace shromáždila. Tento přístup však umožňuje uživatelům model doladit pomocí vlastních datových sad.
Zatímco společnost OpenAI spoléhá na všechna procházená data, aby mohla trénovat své modely a vybudovat kolem svých nástrojů umělé inteligence ziskový ekosystém, společnost Meta usiluje o to, aby kolem svých dat vybudovala ziskový byznys. Meta je tedy nejen využívá k vytváření lepších modelů, ale také je sdílí s třetími stranami, aby je mohly využívat.
„Vaše údaje neprodáváme. Místo toho nám na základě informací, které máme, inzerenti a další partneři platí za to, že vám zobrazujeme personalizované reklamy,“ vysvětluje společnost Meta. Podle standardních informací o ochraně osobních údajů společnosti Meta zahrnují některé údaje, které společnost shromažďuje, mimo jiné nákupy, historii prohlížeče, identifikační údaje, finanční informace, kontakty a nezveřejněné citlivé informace.
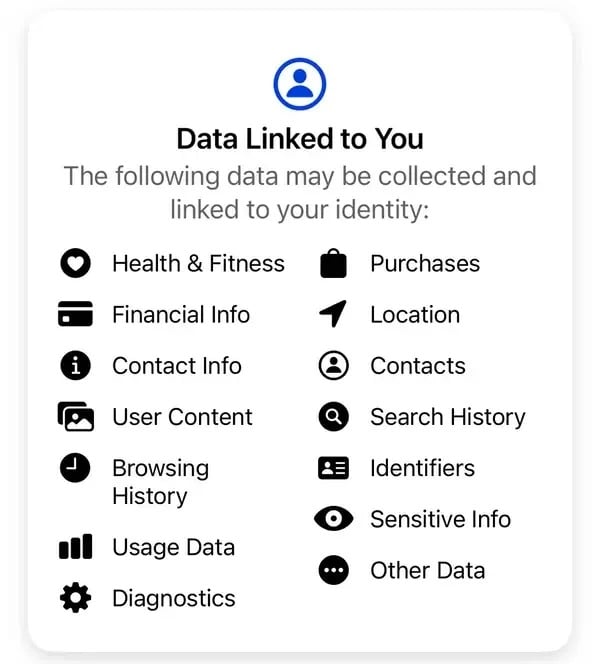
Některé údaje, které společnost Meta shromažďuje od uživatelů své aplikace Thread. Obrázek: Meta
ChatGPT nyní využívá více než 1,5 miliardy aktivních uživatelů měsíčně. A investice společnosti Microsoft ve výši 10 miliard dolarů do OpenAI se zdá být prozíravá, protože integrace ChatGPT posílila možnosti služby Bing.
Prozatím OpenAI vede v oblasti umělé inteligence a technologičtí giganti se ji snaží dohnat. Nový webový crawler společnosti může schopnosti jejích modelů dále rozvíjet. Rozšiřování sběru internetových dat však také vyvolává etické otázky týkající se autorských práv a souhlasu.
S tím, jak se systémy umělé inteligence stávají stále sofistikovanějšími, zůstane vyvažování transparentnosti, etiky a schopností složitým balancem.