
OpenAI пусна нов бот за обхождане на уеб, GPTBot, за да разшири набора си от данни за обучение на следващото поколение системи за изкуствен интелект – и следващата итерация очевидно има официално име. Компанията е регистрирала като търговска марка термина „GPT-5“, с което намеква за предстоящото пускане на пазара, като в същото време предупреждава уеб издателите как да запазят съдържанието си извън огромния корпус.
Според OpenAI уеб обхождачът ще събира публично достъпни данни от уебсайтове, като избягва платено, чувствително и забранено съдържание. Подобно на други търсачки като Google, Bing и Yandex обаче, системата е opt out – по подразбиране GPTBot ще приема, че достъпната информация е честна игра. За да се предотврати поглъщането на даден уебсайт от уебпотърсачката на OpenAI, неговият собственик трябва да добави правило „disallow“ в стандартен файл на сървъра.
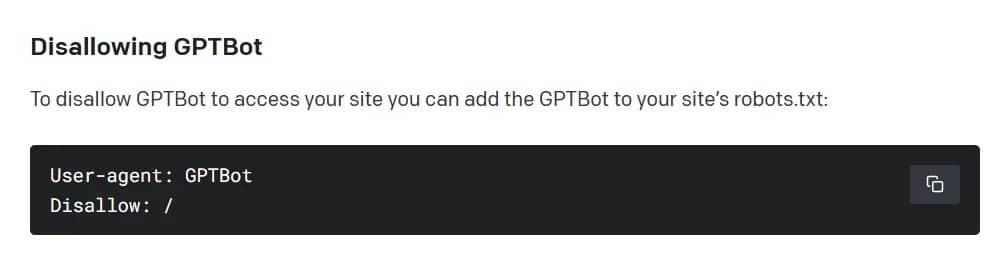
Как да забраним GPTBot на OpenAI. Изображение: OpenAI
ОpenAI също така казва, че GPTBot ще сканира предварително настърганите данни, за да премахне лична информация (PII) и текст, който нарушава нейните политики.
Според някои специалисти по технологична етика обаче подходът на отказ все още повдига въпроси, свързани със съгласието.
В сайта Hacker News някои потребители оправдаха стъпката на OpenAI, като заявиха, че тя трябва да събере всичко, което може, ако хората искат в бъдеще да имат способен инструмент за генеративен ИИ. „Те все още се нуждаят от актуални данни, иначе техните GPT модели ще бъдат завинаги заклещени в септември 2021 г.“, каза един потребител. Друг по-загрижен за неприкосновеността на личния живот потребител твърди, че „OpenAI дори не се позовава на умереност. Тя прави производно произведение, без да го цитира, като по този начин го замъглява“.
Пускането на GPTBot следва неотдавнашните критики към OpenAI, че преди това е изстъргвала данни без разрешение, за да обучава големи езикови модели (LLM) като ChatGPT. За да отговори на тези опасения, компанията актуализира политиките си за поверителност през април.
Междувременно неотдавнашната заявка за търговска марка за GPT-5 изглежда потвърждава, че OpenAI тренира следващия си модел за бъдещо пускане. Много е вероятно новата система да включва широкомащабно изстъргване на данни от интернет, за да се актуализират и разширят данните за обучение.
Това би могло да представлява отклонение от ранния акцент на OpenAI върху прозрачността и безопасността на ИИ, но не е изненадващо, като се има предвид, че ChatGPT е най-използваният LLM в света, въпреки все по-пренаселения и мощен пазар. Звездният продукт на OpenAI – а и на всеки LLM – е толкова добър, колкото е качеството на данните, използвани за обучението му.
OpenAI се нуждае от повече и по-нови данни, и то от много такива.
От друга страна, има LLM с отворен код, създаден от гиганта в областта на социалните медии Meta. Технологичният гигант предлага модела си безплатно, стига да не сте конкурент, нито да сте твърде голям бизнес. Meta не е разкрила кои набори от данни е използвала за обучението на своя модел и каква информация е събрала. Подходът обаче дава възможност на потребителите да настройват модела, като използват свои собствени набори от данни.
Докато OpenAI разчита на всичките си обходени данни, за да обучава моделите си и да изгради печеливша екосистема около инструментите си за изкуствен интелект, Meta се бори да изгради печеливш бизнес около данните си. По този начин Meta не само ги използва, за да създава по-добри модели, но и ги споделя с трети страни, за да могат те да ги използват.
„Ние не продаваме вашата информация. Вместо това, въз основа на информацията, с която разполагаме, рекламодатели и други партньори ни плащат, за да ви показваме персонализирани реклами“, обяснява Meta. Според стандартните оповестявания за поверителност на Meta някои от данните, които компанията събира, включват покупки, история на браузъра, идентификационни номера, финансова информация, контакти и неразкрита чувствителна информация, наред с други.
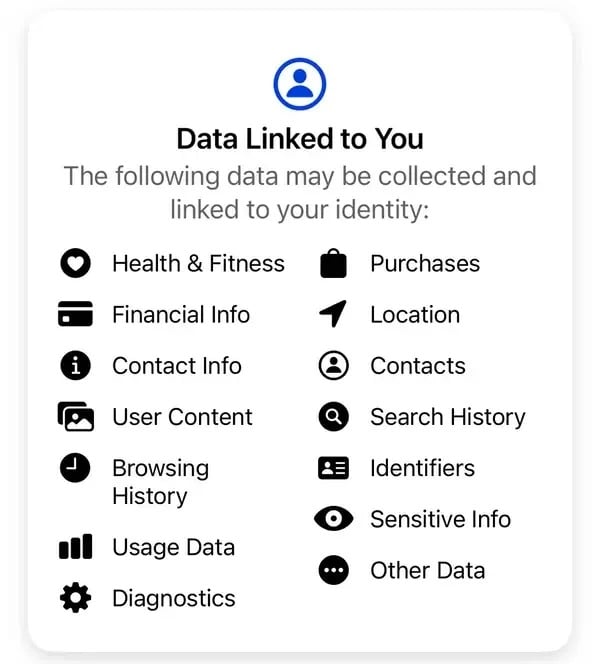
Някои от данните, събирани от Meta от потребителите на нейното приложение Thread. Снимка: Meta
ChatGPT вече привлича над 1,5 милиарда активни потребители месечно. А инвестицията на Microsoft в размер на 10 млрд. долара в OpenAI изглежда предвидлива, тъй като интеграцията на ChatGPT увеличи възможностите на Bing.
Засега OpenAI е лидер в горещото пространство на изкуствения интелект, а технологичните гиганти се надпреварват да я догонят. Новият уебпотърсач на компанията може да подобри още повече възможностите на нейните модели. Но разширяването на събирането на интернет данни повдига и етични въпроси, свързани с авторските права и съгласието.
Тъй като системите за ИИ стават все по-усъвършенствани, балансирането между прозрачност, етика и възможности ще остане сложен акт на равновесие.