
OpenAI heeft een nieuwe webcrawler, GPTBot, uitgebracht om de dataset voor het trainen van de volgende generatie AI-systemen uit te breiden – en de volgende iteratie heeft blijkbaar al een officiële naam. Het bedrijf heeft de term “GPT-5” als handelsmerk geregistreerd, waarmee het zinspeelt op een aanstaande release en tegelijkertijd webuitgevers laat weten hoe ze hun content uit het enorme corpus kunnen houden.
De webcrawler zal openbaar beschikbare gegevens van websites verzamelen en tegelijkertijd paywalled, gevoelige en verboden inhoud vermijden, aldus OpenAI. Net als bij andere zoekmachines zoals Google, Bing en Yandex is het systeem echter opt-out: GPTBot gaat er standaard van uit dat toegankelijke informatie eerlijk spel is. Om te voorkomen dat de OpenAI webcrawler een website binnenhaalt, moet de eigenaar een “disallow” regel toevoegen aan een standaard bestand op de server.
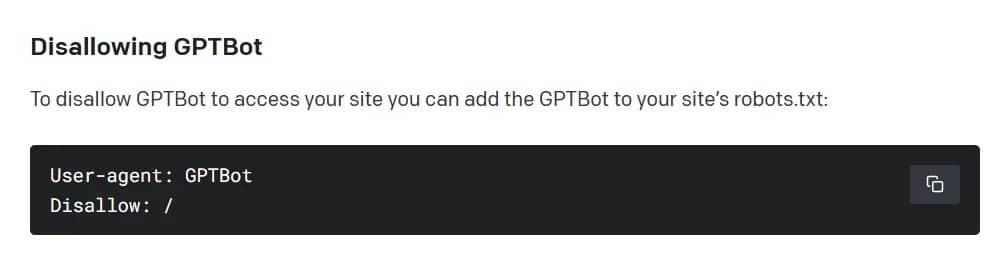
Hoe de GPTBot van OpenAI te verbieden. Afbeelding: OpenAI
OpenAI zegt ook dat GPTBot de geschraapte gegevens preventief zal scannen om persoonlijk identificeerbare informatie (PII) en tekst die in strijd is met het beleid te verwijderen.
Volgens sommige technologie-ethici roept de opt-out benadering echter nog steeds toestemmingsproblemen op.
Op Hacker News rechtvaardigden sommige gebruikers de stap van OpenAI door te zeggen dat het alles moet verzamelen wat het kan als mensen in de toekomst een capabele generatieve AI tool willen hebben. “Ze hebben nog steeds actuele gegevens nodig of hun GPT-modellen blijven voor altijd steken op september 2021,” zei een gebruiker. Een andere, meer privacy-bewuste gebruiker stelde dat “OpenAI niet eens met mate citeert. Het maakt een afgeleid werk zonder te citeren en verduistert het dus.”
De release van GPTBot volgt op recente kritiek op OpenAI dat eerder zonder toestemming gegevens schraapte om Large Language Models (LLM’s) zoals ChatGPT te trainen. Om aan deze bezorgdheid tegemoet te komen, heeft het bedrijf in april zijn privacybeleid aangepast.
Ondertussen lijkt een recente handelsmerkaanvraag voor GPT-5 te bevestigen dat OpenAI zijn volgende model aan het trainen is voor een toekomstige lancering. Het nieuwe systeem zou hoogstwaarschijnlijk op grote schaal web scraping gebruiken om de trainingsgegevens bij te werken en uit te breiden.
Dit zou een verschuiving kunnen betekenen ten opzichte van OpenAI’s vroege nadruk op transparantie en AI-veiligheid, maar het is niet verrassend als je bedenkt dat ChatGPT de meest gebruikte LLM ter wereld is, ondanks een steeds drukkere en krachtiger wordende markt. OpenAI’s sterproduct – en dat van elke LLM – is slechts zo goed als de kwaliteit van de gegevens die worden gebruikt om het te trainen.
OpenAI heeft meer en nieuwere data nodig, en het heeft er veel nodig.
Aan de andere kant is er een open-source LLM, gemaakt door social media gigant Meta. De techreus heeft zijn model gratis ter beschikking gesteld, zolang je geen concurrent bent of een te groot bedrijf hebt. Meta heeft niet bekendgemaakt welke datasets het heeft gebruikt om het model te trainen en welke informatie het heeft verzameld. De aanpak maakt het echter mogelijk voor gebruikers om het model te verfijnen met behulp van hun eigen datasets.
Terwijl OpenAI vertrouwt op al zijn crawledata om zijn modellen te trainen en een winstgevend ecosysteem rond zijn AI-tools op te bouwen, probeert Meta een winstgevende business rond zijn data op te bouwen. Meta gebruikt het dus niet alleen om betere modellen te maken, maar deelt het ook met derden zodat zij het kunnen gebruiken.
“We verkopen je informatie niet. In plaats daarvan betalen adverteerders en andere partners ons, op basis van de informatie die we hebben, om je gepersonaliseerde advertenties te tonen”, legt Meta uit. Volgens de standaard privacyverklaringen van Meta omvatten sommige gegevens die het bedrijf verzamelt onder andere aankopen, browsergeschiedenis, ID’s, financiële info, contacten en niet-openbaar gemaakte gevoelige informatie.
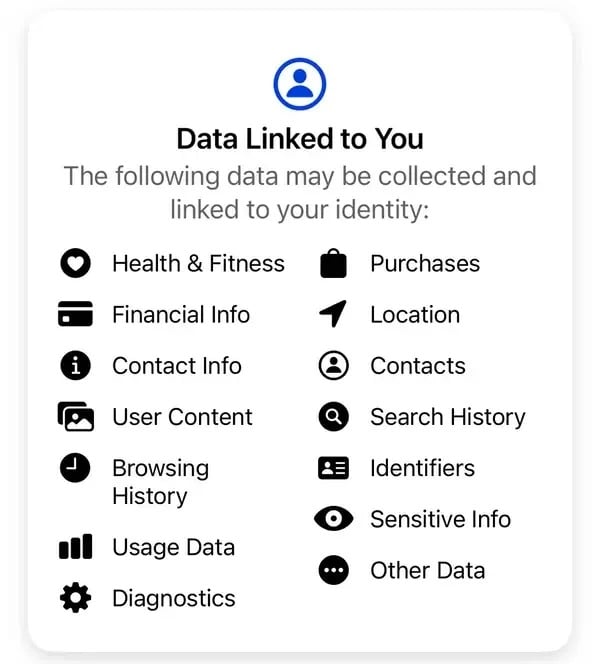
Enkele gegevens die Meta verzamelt van gebruikers van haar Thread App. Afbeelding: Meta
ChatGPT trekt nu meer dan 1,5 miljard maandelijkse actieve gebruikers. En Microsofts investering van $10 miljard in OpenAI lijkt vooruitziend, aangezien de integratie van ChatGPT de mogelijkheden van Bing een boost heeft gegeven.
Op dit moment leidt OpenAI de roodgloeiende AI-ruimte en techgiganten zijn aan het racen om ze in te halen. De nieuwe webcrawler van het bedrijf kan de capaciteiten van de modellen verder vergroten. Maar het steeds meer verzamelen van internetgegevens roept ook ethische vragen op over auteursrecht en toestemming.
Naarmate AI-systemen geavanceerder worden, zal het een complexe evenwichtsoefening blijven om transparantie, ethiek en mogelijkheden in evenwicht te houden.