
Die Gemeinschaft der künstlichen Intelligenz hat mit der Veröffentlichung von Falcon 180B, einem quelloffenen großen Sprachmodell (LLM) mit 180 Milliarden Parametern, das mit einem Berg von Daten trainiert wurde, einen neuen Trumpf im Ärmel. Dieser leistungsstarke Neuling übertrifft frühere Open-Source-LLMs an mehreren Fronten.
Wie die Hugging Face AI-Community in einem Blog-Beitrag bekannt gab, wurde Falcon 180B auf Hugging Face Hub veröffentlicht. Die neueste Modellarchitektur baut auf der vorherigen Falcon-Serie von Open-Source-LLMs auf und nutzt Innovationen wie Multiquery-Attention, um bis zu 180 Milliarden Parameter zu skalieren, die auf 3,5 Billionen Token trainiert wurden.
Dies ist das bisher längste Pretraining eines Open-Source-Modells mit nur einer Epoche. Um diese Werte zu erreichen, wurden 4.096 GPUs gleichzeitig für rund 7 Millionen GPU-Stunden verwendet, wobei Amazon SageMaker für Training und Verfeinerung eingesetzt wurde.
Um die Größe von Falcon 180B ins rechte Licht zu rücken, sind seine Parameter 2,5 Mal größer als die des LLaMA 2-Modells von Meta. LLaMA 2 galt nach seiner Einführung Anfang des Jahres als das leistungsfähigste Open-Source-LLM-Modell mit 70 Milliarden Parametern, die auf 2 Billionen Token trainiert wurden.
Falcon 180B übertrifft LLaMA 2 und andere Modelle sowohl im Umfang als auch in der Benchmark-Leistung bei einer Reihe von Aufgaben der natürlichen Sprachverarbeitung (NLP). Mit 68,74 Punkten rangiert es in der Rangliste der Open-Access-Modelle und erreicht bei Evaluierungen wie dem HellaSwag-Benchmark nahezu Parität mit kommerziellen Modellen wie Googles PaLM-2.
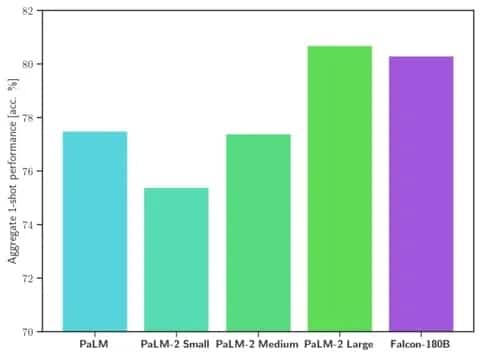
Bild: Hugging Face
Insbesondere erreicht oder übertrifft der Falcon 180B den PaLM-2 Medium bei gängigen Benchmarks wie HellaSwag, LAMBADA, WebQuestions, Winogrande und anderen. Er ist im Grunde gleichauf mit Googles PaLM-2 Large. Dies stellt eine extrem starke Leistung für ein Open-Source-Modell dar, selbst im Vergleich zu Lösungen, die von Branchenriesen entwickelt wurden.
Im Vergleich zu ChatGPT ist das Modell leistungsfähiger als die kostenlose Version, aber etwas weniger leistungsfähig als der kostenpflichtige „Plus“-Dienst.
„Falcon 180B liegt typischerweise irgendwo zwischen GPT 3.5 und GPT4, je nach Bewertungsbenchmark, und es wird sehr interessant sein, die weitere Feinabstimmung durch die Community zu verfolgen, jetzt, wo es öffentlich zugänglich ist“, heißt es im Blog.
Die Veröffentlichung von Falcon 180B ist der jüngste Schritt im Rahmen der rasanten Fortschritte, die in letzter Zeit mit LLMs gemacht wurden. Über die bloße Skalierung der Parameter hinaus haben Techniken wie LoRAs, Gewichtsrandomisierung und Nvidias Perfusion ein wesentlich effizienteres Training großer KI-Modelle ermöglicht.
Da Falcon 180B nun auf Hugging Face frei verfügbar ist, gehen die Forscher davon aus, dass das Modell durch weitere Verbesserungen, die von der Community entwickelt werden, weitere Fortschritte machen wird. Die Demonstration fortgeschrittener Fähigkeiten im Bereich der natürlichen Sprache ist jedoch eine aufregende Entwicklung für die Open-Source-KI