
随着开源大型语言模型(LLM)”猎鹰 180B “的发布,人工智能界又多了一根新的 “羽毛”。”猎鹰 180B “在大量数据的基础上训练出了 1,800 亿个参数。这个强大的新成员在多个方面超越了之前的开源 LLM。
Hugging Face AI 社区在一篇博文中宣布,Falcon 180B 已在 Hugging Face Hub 上发布。最新的模型架构以之前的猎鹰系列开源 LLM 为基础,利用多查询关注等创新技术,在 3.5 万亿个代币上训练出 1,800 亿个参数。
这代表了迄今为止最长的开源模型单波段预训练。为了取得这样的成绩,使用亚马逊 SageMaker 进行训练和提炼时,同时使用了 4,096 个 GPU,耗时约 700 万 GPU 小时。
从 Falcon 180B 的大小来看,其参数测量值是 Meta 的 LLaMA 2 模型的 2.5 倍。LLaMA 2 在今年早些时候推出后,曾被认为是能力最强的开源 LLM,它拥有在 2 万亿代币上训练出来的 700 亿个参数。
在一系列自然语言处理(NLP)任务中,Falcon 180B 的规模和基准性能都超过了 LLaMA 2 和其他模型。它在开放存取模型排行榜上的得分是 68.74 分,在 HellaSwag 基准等评估中与谷歌 PaLM-2 等商业模型的得分接近。
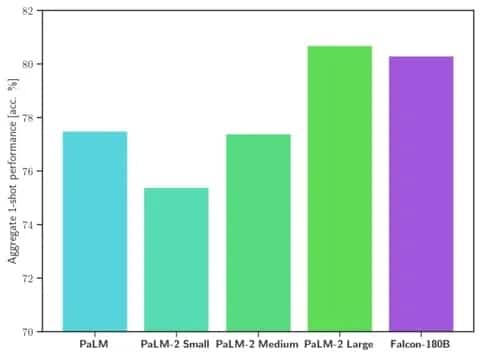
Image: 拥抱的脸
具体来说,Falcon 180B 在包括 HellaSwag、LAMBADA、WebQuestions、Winogrande 等在内的常用基准测试中均达到或超过 PaLM-2 Medium。它基本上与谷歌的 PaLM-2 Large 相当。即使与业内巨头开发的解决方案相比,这也代表了一个开源模型极强的性能。
与 ChatGPT 相比,该模型比免费版本更强大,但比付费的 “plus “服务稍逊一筹。
“博客中写道:”根据评估基准,Falcon 180B 通常介于 GPT 3.5 和 GPT4 之间,既然它已经公开发布,社区的进一步微调将非常值得关注。
Falcon 180B 的发布标志着 LLM 最近取得的飞速进步。除了扩大参数之外,LoRAs、权重随机化和 Nvidia 的 Perfusion 等技术还大大提高了大型人工智能模型的训练效率。
随着 Falcon 180B 现已在 Hugging Face 上免费提供,研究人员预计该模型将随着社区开发的进一步增强而获得更多收益。不过,它一开始就展示了先进的自然语言能力,标志着开源人工智能取得了令人振奋的发展。