
1.Die Herausforderung für einen modernen Blockchain-Datenstack
Es gibt mehrere Herausforderungen, denen sich ein modernes Blockchain-Indizierungs-Startup stellen kann, darunter:
- Massive Datenmengen. Wenn die Datenmenge auf der Blockchain zunimmt, muss der Datenindex skaliert werden, um die erhöhte Last zu bewältigen und einen effizienten Zugriff auf die Daten zu ermöglichen. Dies führt zu höheren Speicherkosten, einer langsamen Berechnung von Metriken und einer erhöhten Belastung des Datenbankservers.
- Komplexe Datenverarbeitungspipeline. Die Blockchain-Technologie ist komplex, und der Aufbau eines umfassenden und zuverlässigen Datenindexes erfordert ein tiefes Verständnis der zugrunde liegenden Datenstrukturen und Algorithmen. Die Vielfalt der Blockchain-Implementierungen bringt dies mit sich. Konkrete Beispiele: NFTs in Ethereum werden in der Regel innerhalb von Smart Contracts nach den Formaten ERC721 und ERC1155 erstellt. Im Gegensatz dazu wird die Implementierung von NFTs auf Polkadot in der Regel direkt in der Blockchain-Laufzeitumgebung erstellt. Diese sind als NFTs zu betrachten und sollten als solche gespeichert werden.
- Integrationsmöglichkeiten. Um den Nutzern einen maximalen Nutzen zu bieten, muss eine Blockchain-Indizierungslösung ihren Datenindex möglicherweise in andere Systeme integrieren, z. B. in Analyseplattformen oder APIs. Dies ist eine Herausforderung und erfordert einen erheblichen Aufwand bei der Entwicklung der Architektur.
Mit der zunehmenden Verbreitung der Blockchain-Technologie ist auch die Menge der in der Blockchain gespeicherten Daten gestiegen. Das liegt daran, dass immer mehr Menschen die Technologie nutzen und mit jeder Transaktion neue Daten zur Blockchain hinzugefügt werden. Darüber hinaus hat sich die Blockchain-Technologie von einfachen Geldüberweisungsanwendungen, wie z. B. der Verwendung von Bitcoin, zu komplexeren Anwendungen weiterentwickelt, die die Implementierung von Geschäftslogik in intelligenten Verträgen beinhalten. Diese intelligenten Verträge können große Datenmengen erzeugen, was zur zunehmenden Komplexität und Größe der Blockchain beiträgt. Mit der Zeit hat dies zu einer größeren und komplexeren Blockchain geführt.
In diesem Artikel betrachten wir die Entwicklung der Technologiearchitektur von Footprint Analytics in mehreren Schritten als Fallstudie, um zu untersuchen, wie der Iceberg-Trino-Technologie-Stack die Herausforderungen von On-Chain-Daten angeht.
Footprint Analytics hat etwa 22 öffentliche Blockchain-Daten, 17 NFT-Marktplätze, 1900 GameFi-Projekte und über 100.000 NFT-Sammlungen in einer semantischen Abstraktionsdatenschicht indexiert. Es ist die umfassendste Blockchain Data Warehouse-Lösung der Welt.
Unabhängig von den Blockchain-Daten, die mehr als 20 Milliarden Datensätze von Finanztransaktionen umfassen, die von Datenanalysten häufig abgefragt werden, unterscheidet sie sich von Ingressionsprotokollen in herkömmlichen Data Warehouses.
Wir haben in den letzten Monaten 3 große Upgrades durchgeführt, um den wachsenden Geschäftsanforderungen gerecht zu werden:
2. Architektur 1.0 Bigquery
Zu Beginn von Footprint Analytics haben wir Google Bigquery als Speicher- und Abfrage-Engine verwendet; Bigquery ist ein großartiges Produkt. Bigquery ist ein großartiges Produkt. Es ist rasend schnell, einfach zu bedienen und bietet dynamische Rechenleistung und eine flexible UDF-Syntax, die uns hilft, unsere Aufgaben schnell zu erledigen.
Allerdings hat Bigquery auch einige Probleme:
- Daten werden nicht komprimiert, was zu hohen Kosten führt, insbesondere bei der Speicherung der Rohdaten von über 22 Blockchains von Footprint Analytics.
- Unzureichende Gleichzeitigkeit: Bigquery unterstützt nur 100 gleichzeitige Abfragen, was für Szenarien mit hoher Gleichzeitigkeit für Footprint Analytics ungeeignet ist, wenn viele Analysten und Benutzer bedient werden.
- Lock in with Google Bigquery, which is a closed-source product。
So beschlossen wir, andere alternative Architekturen zu erforschen.
3. Architektur 2.0 OLAP
Wir waren sehr an einigen OLAP-Produkten interessiert, die sehr populär geworden waren. Der attraktivste Vorteil von OLAP ist die Antwortzeit auf Abfragen, die in der Regel weniger als eine Sekunde beträgt, um Abfrageergebnisse für riesige Datenmengen zu liefern, und es können auch Tausende von gleichzeitigen Abfragen unterstützt werden.
Wir haben eine der besten OLAP-Datenbanken, Doris, ausgewählt, um sie auszuprobieren. Dieses System ist sehr leistungsfähig. Irgendwann stießen wir jedoch auf einige andere Probleme:
- Datentypen wie Array oder JSON werden noch nicht unterstützt (Nov, 2022). Arrays sind ein häufiger Datentyp in einigen Blockchains. Zum Beispiel das Themenfeld in evm-Protokollen. Die Tatsache, dass Arrays nicht verarbeitet werden können, wirkt sich direkt auf unsere Fähigkeit aus, viele Geschäftskennzahlen zu berechnen.
- Beschränkte Unterstützung für DBT und für Merge-Anweisungen. Dies sind häufige Anforderungen von Dateningenieuren für ETL/ELT-Szenarien, in denen wir einige neu indizierte Daten aktualisieren müssen.
Deshalb haben wir versucht, Doris als OLAP-Datenbank einzusetzen, um einen Teil unseres Problems in der Datenproduktionspipeline zu lösen, indem es als Abfrage-Engine fungiert und schnelle und hochgradig gleichzeitige Abfragen ermöglicht.
Leider konnten wir Bigquery nicht durch Doris ersetzen, so dass wir in regelmäßigen Abständen Daten von Bigquery mit Doris synchronisieren mussten, indem wir es als Abfragemaschine verwendeten. Dieser Synchronisationsprozess hatte mehrere Probleme, von denen eines darin bestand, dass sich die Aktualisierungsschreibvorgänge schnell stapelten, wenn die OLAP-Engine damit beschäftigt war, Abfragen an die Front-End-Clients zu liefern. Dadurch wurde die Geschwindigkeit des Schreibvorgangs beeinträchtigt, und die Synchronisierung dauerte viel länger und konnte manchmal sogar nicht abgeschlossen werden.
Wir erkannten, dass OLAP zwar einige unserer Probleme lösen konnte, aber nicht die schlüsselfertige Lösung von Footprint Analytics sein konnte, insbesondere nicht für die Datenverarbeitungspipeline. Unser Problem ist größer und komplexer, und wir können sagen, dass OLAP als Abfrage-Engine allein für uns nicht ausreicht.
4. Architektur 3.0 Iceberg + Trino
Willkommen zur Footprint Analytics Architektur 3.0, einer kompletten Überarbeitung der zugrunde liegenden Architektur. Wir haben die gesamte Architektur von Grund auf neu gestaltet, um die Speicherung, Berechnung und Abfrage von Daten in drei verschiedene Teile zu trennen. Wir haben die Lehren aus den beiden früheren Architekturen von Footprint Analytics gezogen und von den Erfahrungen anderer erfolgreicher Big-Data-Projekte wie Uber, Netflix und Databricks gelernt.
4.1. Einführung des Data Lake
Wir haben uns zunächst dem Data Lake zugewandt, einer neuen Art der Datenspeicherung sowohl für strukturierte als auch für unstrukturierte Daten. Data Lake eignet sich perfekt für die Speicherung von On-Chain-Daten, da die Formate der On-Chain-Daten von unstrukturierten Rohdaten bis hin zu strukturierten Abstraktionsdaten reichen, für die Footprint Analytics bekannt ist. Wir erwarteten, dass Data Lake das Problem der Datenspeicherung lösen würde, und idealerweise würde es auch Mainstream-Compute-Engines wie Spark und Flink unterstützen, so dass die Integration mit verschiedenen Arten von Verarbeitungs-Engines im Zuge der Weiterentwicklung von Footprint Analytics kein Problem darstellen würde.
Iceberg lässt sich sehr gut mit Spark, Flink, Trino und anderen Computing-Engines integrieren, und wir können für jede unserer Metriken die am besten geeignete Berechnung auswählen. Zum Beispiel:
- Für diejenigen, die eine komplexe Berechnungslogik benötigen, wird Spark die Wahl sein.
- Flink für Echtzeitberechnungen.
- Für einfache ETL-Aufgaben, die mit SQL durchgeführt werden können, verwenden wir Trino.
4.2. Abfragemaschine
Nachdem Iceberg die Speicher- und Berechnungsprobleme gelöst hat, mussten wir uns Gedanken über die Wahl einer Abfrage-Engine machen. Es sind nicht viele Optionen verfügbar. Die von uns in Betracht gezogenen Alternativen waren
- Trino: SQL Query Engine
- Presto: SQL-Query-Engine
- Kyuubi: Serverless Spark SQL
Das Wichtigste, was wir bedacht haben, bevor wir in die Tiefe gingen, war, dass die zukünftige Query Engine mit unserer aktuellen Architektur kompatibel sein musste
- Um Bigquery als Datenquelle zu unterstützen.
- Unterstützung von DBT, auf das wir für die Erstellung vieler Metriken angewiesen sind
- Unterstützung der Metabasis des BI-Tools
Auf der Grundlage der obigen Ausführungen haben wir uns für Trino entschieden, das einen sehr guten Support für Iceberg bietet. Das Team war so reaktionsschnell, dass wir einen Fehler gemeldet haben, der am nächsten Tag behoben und in der darauf folgenden Woche in der neuesten Version veröffentlicht wurde. Dies war die beste Wahl für das Footprint-Team, das ebenfalls eine hohe Reaktionsfähigkeit bei der Implementierung benötigt.
4.3. Leistungstests
Nachdem wir uns für eine Richtung entschieden hatten, führten wir einen Leistungstest mit der Kombination Trino + Iceberg durch, um zu sehen, ob sie unsere Anforderungen erfüllen konnte, und zu unserer Überraschung waren die Abfragen unglaublich schnell.
Da wir wissen, dass Presto + Hive in all dem OLAP-Hype seit Jahren die schlechteste Vergleichslösung ist, hat uns die Kombination von Trino + Iceberg völlig umgehauen.
Hier sind die Ergebnisse unserer Tests.
Fall 1: Join eines großen Datenbestands
Eine 800 GB große Tabelle1 wird mit einer anderen 50 GB großen Tabelle2 verbunden und führt komplexe Geschäftsberechnungen durch.
Fall 2: Verwendung einer großen Einzeltabelle für eine eindeutige Abfrage
Test sql: select distinct(address) from the table group by day

Die Kombination Trino+Iceberg ist etwa dreimal so schnell wie Doris in der gleichen Konfiguration.
Darüber hinaus gibt es eine weitere Überraschung, denn Iceberg kann Datenformate wie Parquet, ORC usw. verwenden, die die Daten komprimieren und speichern. Icebergs Tabellenspeicher benötigt nur etwa 1/5 des Platzes anderer Data Warehouses. Die Speichergröße der gleichen Tabelle in den drei Datenbanken ist wie folgt:
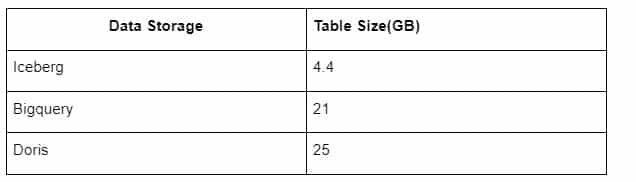
Hinweis: Die obigen Tests sind Beispiele, die wir in der tatsächlichen Produktion angetroffen haben und dienen nur als Referenz.
4.4. Upgrade-Effekt
Die Berichte der Leistungstests ergaben eine ausreichende Leistung, so dass unser Team etwa 2 Monate brauchte, um die Migration abzuschließen, und dies ist ein Diagramm unserer Architektur nach dem Upgrade
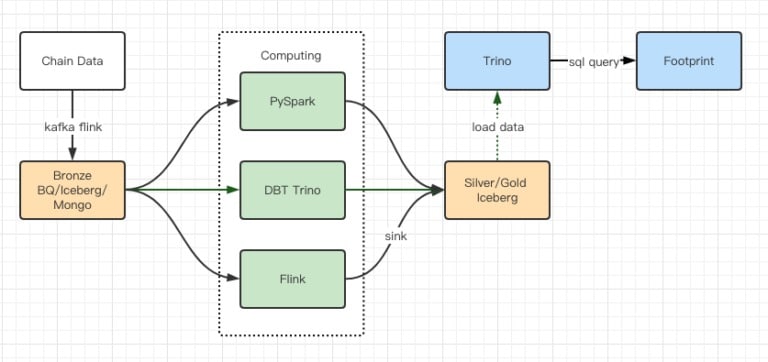
- Mehrere Computermotoren entsprechen unseren verschiedenen Bedürfnissen.
- Trino unterstützt DBT und kann Iceberg direkt abfragen, so dass wir uns nicht mehr um die Datensynchronisation kümmern müssen.
- Die erstaunliche Leistung von Trino + Iceberg ermöglicht es uns, alle Bronze-Daten (Rohdaten) für unsere Nutzer zu öffnen.
5. Zusammenfassung
Seit dem Start im August 2021 hat das Team von Footprint Analytics in weniger als anderthalb Jahren drei Architektur-Upgrades durchgeführt. Dies ist dem starken Wunsch und der Entschlossenheit zu verdanken, den Nutzern von Kryptowährungen die Vorteile der besten Datenbanktechnologie zur Verfügung zu stellen, sowie der soliden Ausführung bei der Implementierung und Verbesserung der zugrunde liegenden Infrastruktur und Architektur.
Das Upgrade 3.0 der Footprint-Analytics-Architektur hat seinen Nutzern eine neue Erfahrung beschert, die es Nutzern mit unterschiedlichem Hintergrund ermöglicht, Einblicke in vielfältigere Nutzungen und Anwendungen zu erhalten:
- Mit dem BI-Tool Metabase ermöglicht Footprint Analysten den Zugriff auf entschlüsselte On-Chain-Daten, die freie Wahl der Tools (No-Code oder Hardcord), die Abfrage der gesamten Historie und die Querprüfung von Datensätzen, um in kürzester Zeit Erkenntnisse zu gewinnen.
- Integrieren Sie sowohl On-Chain- als auch Off-Chain-Daten zur Analyse über web2 + web3;
- Durch den Aufbau / die Abfrage von Metriken auf Basis der Footprint Geschäftsabstraktion sparen Analysten oder Entwickler 80% der Zeit für sich wiederholende Datenverarbeitungsarbeiten und können sich auf aussagekräftige Metriken, Forschung und Produktlösungen für ihr Geschäft konzentrieren.
- Nahtlose Erfahrung von Footprint Web bis hin zu REST API-Aufrufen, alles basierend auf SQL
Echtzeitwarnungen und umsetzbare Benachrichtigungen über wichtige Signale zur Unterstützung von Investitionsentscheidungen