
1.La sfida per un moderno stack di dati blockchain
Ci sono diverse sfide che una moderna startup di indicizzazione blockchain può affrontare, tra cui:
- Massime quantità di dati. Con l’aumento della quantità di dati sulla blockchain, l’indice dei dati dovrà scalare per gestire l’aumento del carico e fornire un accesso efficiente ai dati. Di conseguenza, ciò comporta costi di archiviazione più elevati, lentezza nel calcolo delle metriche e aumento del carico sul server del database.
- Complessa pipeline di elaborazione dei dati. La tecnologia blockchain è complessa e la costruzione di un indice di dati completo e affidabile richiede una profonda comprensione delle strutture di dati e degli algoritmi sottostanti. La diversità delle implementazioni blockchain lo eredita. Per fare degli esempi specifici, le NFT in Ethereum sono solitamente create all’interno di smart contract secondo i formati ERC721 e ERC1155. Al contrario, l’implementazione di questi ultimi su Polkadot, ad esempio, è di solito costruita direttamente all’interno del runtime della blockchain. Questi dovrebbero essere considerati NFT e dovrebbero essere salvati come tali.
- Capacità di integrazione. Per fornire il massimo valore agli utenti, una soluzione di indicizzazione blockchain può avere bisogno di integrare il suo indice di dati con altri sistemi, come piattaforme di analisi o API. Si tratta di una sfida che richiede uno sforzo significativo nella progettazione dell’architettura.
Con la diffusione della tecnologia blockchain, la quantità di dati memorizzati sulla blockchain è aumentata. Questo perché sempre più persone utilizzano questa tecnologia e ogni transazione aggiunge nuovi dati alla blockchain. Inoltre, la tecnologia blockchain si è evoluta da semplici applicazioni di trasferimento di denaro, come quelle che prevedono l’uso di Bitcoin, ad applicazioni più complesse che prevedono l’implementazione della logica aziendale all’interno di contratti intelligenti. Questi contratti intelligenti possono generare grandi quantità di dati, contribuendo ad aumentare la complessità e le dimensioni della blockchain. Nel tempo, ciò ha portato a una blockchain più grande e più complessa.
In questo articolo, esaminiamo l’evoluzione dell’architettura tecnologica di Footprint Analytics in più fasi come caso di studio per esplorare come lo stack tecnologico Iceberg-Trino affronta le sfide dei dati sulla catena.
Footprint Analytics ha indicizzato circa 22 blockchain pubbliche, 17 mercati NFT, 1900 progetti GameFi e oltre 100.000 collezioni NFT in un livello di dati di astrazione semantica. Si tratta della soluzione di data warehouse blockchain più completa al mondo.
A prescindere dai dati della blockchain, che comprendono oltre 20 miliardi di righe di record di transazioni finanziarie, che gli analisti di dati interrogano frequentemente, è diversa dai log di ingressione dei data warehouse tradizionali.
Negli ultimi mesi abbiamo effettuato 3 importanti aggiornamenti per soddisfare i crescenti requisiti aziendali:
2. Architettura 1.0 Bigquery
All’inizio di Footprint Analytics, abbiamo utilizzato Google Bigquery come motore di archiviazione e di interrogazione; Bigquery è un ottimo prodotto. È velocissimo, facile da usare e offre una potenza aritmetica dinamica e una sintassi UDF flessibile che ci aiuta a svolgere rapidamente il lavoro.
Tuttavia, Bigquery presenta anche diversi problemi:
- I dati non sono compressi, il che comporta costi elevati, soprattutto quando si memorizzano i dati grezzi di oltre 22 blockchain di Footprint Analytics.
- Concorrenza insufficiente: Bigquery supporta solo 100 query simultanee, il che non è adatto a scenari di elevata concurrency per Footprint Analytics quando si servono molti analisti e utenti.
- Si è agganciato a Google Bigquery, che è un prodotto closed-source。
Quindi abbiamo deciso di esplorare altre architetture alternative.
3. Architettura 2.0 OLAP
Eravamo molto interessati ad alcuni prodotti OLAP che erano diventati molto popolari. Il vantaggio più interessante di OLAP è il suo tempo di risposta alle query, che in genere richiede meno di un secondo per restituire i risultati di query per enormi quantità di dati, e può anche supportare migliaia di query simultanee.
Abbiamo scelto uno dei migliori database OLAP, Doris, per provarlo. Questo motore si comporta bene. Tuttavia, a un certo punto ci siamo imbattuti in altri problemi:
- I tipi di dati come Array o JSON non sono ancora supportati (novembre 2022). Gli array sono un tipo di dati comune in alcune blockchain. Ad esempio, il campo topic nei log evm. L’impossibilità di calcolare su array influisce direttamente sulla nostra capacità di calcolare molte metriche aziendali.
- Supporto limitato per DBT e per le dichiarazioni di fusione. Si tratta di requisiti comuni per gli ingegneri dei dati in scenari ETL/ELT in cui è necessario aggiornare alcuni dati indicizzati di recente.
Detto questo, non potevamo usare Doris per l’intera pipeline di dati in produzione, quindi abbiamo cercato di usare Doris come database OLAP per risolvere parte del problema nella pipeline di produzione dei dati, agendo come motore di query e fornendo funzionalità di query veloci e altamente simultanee.
Purtroppo non potevamo sostituire Bigquery con Doris, quindi dovevamo sincronizzare periodicamente i dati da Bigquery a Doris utilizzando quest’ultimo come motore di query. Questo processo di sincronizzazione presentava diversi problemi, uno dei quali era che le scritture di aggiornamento si accumulavano rapidamente quando il motore OLAP era impegnato a servire le query ai client front-end. Di conseguenza, la velocità del processo di scrittura ne risentiva e la sincronizzazione richiedeva molto più tempo e a volte diventava impossibile da completare.
Ci siamo resi conto che l’OLAP poteva risolvere diversi problemi che stavamo affrontando e non poteva diventare la soluzione chiavi in mano di Footprint Analytics, soprattutto per quanto riguarda la pipeline di elaborazione dei dati. Il nostro problema è più grande e più complesso, e possiamo dire che l’OLAP come motore di query da solo non era sufficiente per noi.
4. Architettura 3.0 Iceberg + Trino
Benvenuta all’architettura 3.0 di Footprint Analytics, una revisione completa dell’architettura di base. Abbiamo riprogettato l’intera architettura da zero per separare l’archiviazione, il calcolo e l’interrogazione dei dati in tre parti diverse. Prendendo spunto dalle due precedenti architetture di Footprint Analytics e imparando dall’esperienza di altri progetti big data di successo come Uber, Netflix e Databricks.
4.1. Introduzione del data lake
Per prima cosa abbiamo rivolto la nostra attenzione al data lake, un nuovo tipo di archiviazione dei dati sia strutturati che non strutturati. Il data lake è perfetto per l’archiviazione dei dati on-chain, poiché i formati dei dati on-chain variano ampiamente dai dati grezzi non strutturati ai dati strutturati di astrazione per i quali Footprint Analytics è ben nota. Ci aspettavamo di utilizzare i data lake per risolvere il problema dell’archiviazione dei dati e, idealmente, di supportare anche i motori di calcolo mainstream come Spark e Flink, in modo da evitare l’integrazione con diversi tipi di motori di elaborazione man mano che Footprint Analytics si evolve.
Iceberg si integra molto bene con Spark, Flink, Trino e altri motori di calcolo e possiamo scegliere il calcolo più appropriato per ciascuna delle nostre metriche. Per esempio:
- Per chi richiede una logica di calcolo complessa, la scelta ricadrà su Spark.
- Flink per il calcolo in tempo reale.
- Per attività ETL semplici che possono essere eseguite con SQL, usiamo Trino.
4.2. Motore di interrogazione
Con Iceberg che risolve i problemi di archiviazione e calcolo, abbiamo dovuto pensare alla scelta di un motore di interrogazione. Le opzioni disponibili non sono molte. Le alternative che abbiamo considerato sono
- Trino: Motore di query SQL
- Presto: Motore di interrogazione SQL
- Kyuubi: SQL Spark senza server
La cosa più importante che abbiamo considerato prima di approfondire è che il futuro motore di query doveva essere compatibile con la nostra architettura attuale.
- Per supportare Bigquery come origine dati
- Per supportare DBT, su cui ci basiamo per produrre molte metriche
- Per supportare il metabase dello strumento di BI
In base a quanto detto sopra, abbiamo scelto Trino, che ha un ottimo supporto per Iceberg e il team è stato così reattivo da segnalarci un bug, che è stato risolto il giorno dopo e rilasciato all’ultima versione la settimana successiva. Questa è stata la scelta migliore per il team di Footprint, che richiede anche un’elevata reattività dell’implementazione.
4.3. Test delle prestazioni
Una volta decisa la direzione da seguire, abbiamo effettuato un test delle prestazioni sulla combinazione Trino + Iceberg per verificare se fosse in grado di soddisfare le nostre esigenze e, con nostra grande sorpresa, le query erano incredibilmente veloci.
Sapendo che Presto + Hive è stato per anni il peggior comparatore in tutto l’ambiente OLAP, la combinazione di Trino + Iceberg ci ha completamente spiazzati.
Ecco i risultati dei nostri test.
caso 1: unione di un grande insieme di dati
Una tabella1 da 800 GB si unisce a un’altra tabella2 da 50 GB ed esegue calcoli aziendali complessi.
caso2: utilizzare una singola tabella di grandi dimensioni per eseguire una query distinta
Test sql: select distinct(address) from the table group by day

La combinazione Trino+Iceberg è circa 3 volte più veloce di Doris nella stessa configurazione.
Inoltre, c’è un’altra sorpresa, perché Iceberg può utilizzare formati di dati come Parquet, ORC e così via, che comprimono e memorizzano i dati. L’archiviazione delle tabelle di Iceberg occupa solo circa 1/5 dello spazio di altri data warehouse Le dimensioni di archiviazione della stessa tabella nei tre database sono le seguenti:
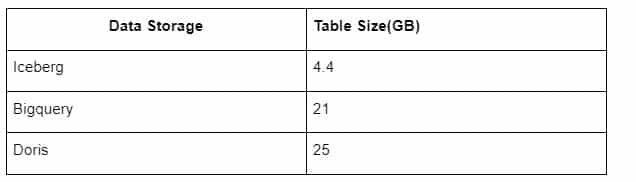
Nota: i test di cui sopra sono esempi che abbiamo incontrato nella produzione reale e sono solo di riferimento.
4.4. Effetto dell’aggiornamento
I rapporti dei test sulle prestazioni ci hanno fornito prestazioni sufficienti, tanto che il nostro team ha impiegato circa 2 mesi per completare la migrazione, e questo è un diagramma della nostra architettura dopo l’aggiornamento.
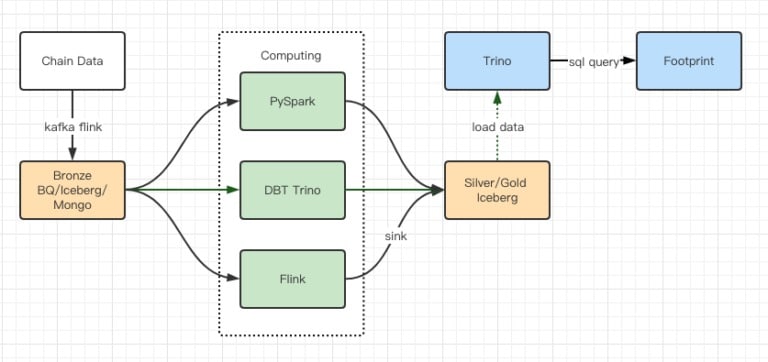
- Molteplici motori di computer rispondono alle nostre diverse esigenze.
- Trino supporta DBT e può interrogare direttamente Iceberg, così non dobbiamo più occuparci della sincronizzazione dei dati.
- Le straordinarie prestazioni di Trino + Iceberg ci permettono di aprire tutti i dati di bronzo (dati grezzi) ai nostri utenti.
5. Riepilogo
Dal suo lancio nell’agosto 2021, il team di Footprint Analytics ha completato tre aggiornamenti architetturali in meno di un anno e mezzo, grazie al forte desiderio e alla determinazione di portare i benefici della migliore tecnologia di database ai suoi utenti di criptovalute e alla solida esecuzione dell’implementazione e dell’aggiornamento dell’infrastruttura e dell’architettura sottostante.
L’aggiornamento 3.0 dell’architettura di Footprint Analytics ha offerto una nuova esperienza ai suoi utenti, consentendo a utenti di diversa estrazione di ottenere approfondimenti in usi e applicazioni più diversi:
- Costruito con lo strumento di BI Metabase, Footprint facilita l’accesso degli analisti ai dati decodificati sulla catena, l’esplorazione con la massima libertà di scelta degli strumenti (no-code o hardcord), l’interrogazione dell’intero storico e l’esame incrociato dei set di dati, per ottenere approfondimenti in pochissimo tempo.
- Integrare i dati on-chain e off-chain nell’analisiattraversoweb2 + web3;
- Costruendo/interrogando metriche sulla base dell’astrazione di business di Footprint, gli analisti o gli sviluppatori risparmiano l’80% del lavoro di elaborazione ripetitiva dei dati e si concentrano su metriche significative, ricerche e soluzioni di prodotto basate sul loro business.
- Esperienza senza soluzione di continuità dal Web Footprint alle chiamate API REST, tutte basate su SQL
Avvertenze in tempo reale e notifiche attivabili su segnali chiave per supportare le decisioni di investimento