
1.o desafio para a moderna pilha de dados da cadeia de blocos
Há vários desafios que um arranque moderno de indexação em cadeia de blocos pode enfrentar, incluindo:
- Mensor quantidade de dados. À medida que a quantidade de dados na cadeia de bloqueio aumenta, o índice de dados terá de ser aumentado para lidar com o aumento da carga e proporcionar um acesso eficiente aos dados. Consequentemente, conduz a custos de armazenamento mais elevados, cálculo lento da métrica, e aumento da carga no servidor da base de dados.
- Conjunto completo de processamento de dados. A tecnologia Blockchain é complexa, e a construção de um índice de dados abrangente e fiável requer uma compreensão profunda das estruturas e algoritmos de dados subjacentes. A diversidade de implementações da blockchain herda-a. Dados exemplos específicos, as NFT no Ethereum são normalmente criadas no âmbito de contratos inteligentes seguindo os formatos ERC721 e ERC1155. Em contraste, a implementação das que se encontram no Polkadot, por exemplo, é normalmente construída directamente dentro do tempo de execução da cadeia de blocos. Estes devem ser considerados NFT e devem ser guardados como tal.
- Capacidades de integração. Para proporcionar o máximo valor aos utilizadores, uma solução de indexação em cadeia de blocos pode necessitar de integrar o seu índice de dados com outros sistemas, tais como plataformas analíticas ou APIs. Isto é um desafio e requer um esforço significativo colocado na concepção da arquitectura.
Como a tecnologia da cadeia de bloqueio se tornou mais difundida, a quantidade de dados armazenados na cadeia de bloqueio aumentou. Isto acontece porque mais pessoas estão a utilizar a tecnologia, e cada transacção acrescenta novos dados à cadeia de bloqueio. Além disso, a tecnologia blockchain evoluiu de aplicações simples de transferência de dinheiro, tais como as que envolvem a utilização de Bitcoin, para aplicações mais complexas envolvendo a implementação de lógica empresarial no âmbito de contratos inteligentes. Estes contratos inteligentes podem gerar grandes quantidades de dados, contribuindo para o aumento da complexidade e da dimensão da cadeia de blocos. Ao longo do tempo, isto conduziu a uma cadeia de bloqueio maior e mais complexa.
Neste artigo, analisamos a evolução da arquitectura tecnológica da Footprint Analytics por fases como um estudo de caso para explorar como a pilha tecnológica Iceberg-Trino aborda os desafios dos dados na cadeia.
Footprint Analytics indexou cerca de 22 dados públicos da cadeia de bloqueio, e 17 do mercado NFT, 1900 do projecto GameFi, e mais de 100.000 colecções NFT numa camada de dados de abstracção semântica. É a solução de armazenamento de dados em cadeia de blocos mais abrangente do mundo.
Independentemente dos dados da cadeia de bloqueio, que inclui mais de 20 biliões de linhas de registos de transacções financeiras, que os analistas de dados consultam frequentemente. é diferente dos registos de ingressão nos armazéns de dados tradicionais.
Nos últimos meses, assistimos a 3 grandes actualizações para satisfazer as crescentes exigências do negócio:
2. Arquitectura 1.0 Bigquery
No início da Footprint Analytics, utilizámos o Google Bigquery como motor de armazenamento e consulta; Bigquery é um grande produto. É incrivelmente rápido, fácil de usar, e fornece potência aritmética dinâmica e uma sintaxe UDF flexível que nos ajuda a fazer o trabalho rapidamente.
No entanto, Bigquery também tem vários problemas.
- Os dados não são comprimidos, resultando em custos elevados, especialmente no armazenamento de dados brutos de mais de 22 cadeias de blocos da Footprint Analytics.
- Concurrency insuficiente: A Bigquery suporta apenas 100 consultas simultâneas, o que é inadequado para cenários de alta concorrência para Footprint Analytics quando serve muitos analistas e utilizadores.
- Travar no Google Bigquery, que é uma fonte fechada product。
Então decidimos explorar outras arquitecturas alternativas.
3. Arquitectura 2.0 OLAP
Estávamos muito interessados em alguns dos produtos OLAP que se tinham tornado muito populares. A vantagem mais atractiva da OLAP é o seu tempo de resposta à consulta, que normalmente leva subsegundos para devolver resultados de consulta para quantidades massivas de dados, e também pode suportar milhares de consultas simultâneas.
Escolhemos uma das melhores bases de dados OLAP, Doris, para lhe dar uma tentativa. Este motor tem um bom desempenho. No entanto, a dada altura, deparámo-nos com outros problemas:
- Os tipos de dados como Array ou JSON ainda não são suportados (Nov, 2022). Os Arrays são um tipo comum de dados em algumas cadeias de bloqueio. Por exemplo, o campo do tópico em registos evm. A impossibilidade de calcular no Array afecta directamente a nossa capacidade de calcular muitas métricas de negócio.
- Suporte limitado para DBT, e para declarações de fusão. Estes são requisitos comuns para engenheiros de dados para cenários ETL/ELT, onde precisamos de actualizar alguns dados recentemente indexados.
Dito isto, não podíamos utilizar a Doris para todo o nosso pipeline de dados sobre produção, pelo que tentámos utilizar a Doris como base de dados OLAP para resolver parte do nosso problema no pipeline de produção de dados, actuando como motor de consulta e fornecendo capacidades de consulta rápidas e altamente simultâneas.
Infelizmente, não pudemos substituir Bigquery por Doris, pelo que tivemos de sincronizar periodicamente os dados de Bigquery para Doris, utilizando-os como motor de consulta. Este processo de sincronização teve vários problemas, um dos quais foi o facto de as actualizações terem sido rapidamente acumuladas quando o motor OLAP estava ocupado a servir consultas aos clientes front-end. Subsequentemente, a velocidade do processo de escrita foi afectada, e a sincronização demorou muito mais tempo e por vezes tornou-se até impossível de terminar.
Percebemos que a OLAP podia resolver vários problemas que enfrentávamos e não podia tornar-se a solução chave na mão da Footprint Analytics, especialmente para o gasoduto de processamento de dados. O nosso problema é maior e mais complexo, e poderíamos dizer que OLAP como motor de consulta por si só não era suficiente para nós.
4. Arquitectura 3.0 Iceberg + Trino
Welcome to Footprint Analytics architecture 3.0, uma revisão completa da arquitectura subjacente. Redefinimos toda a arquitectura a partir do solo para separar o armazenamento, cálculo e consulta de dados em três partes diferentes. Tirando lições das duas arquitecturas anteriores da Footprint Analytics e aprendendo com a experiência de outros grandes projectos de dados de sucesso como Uber, Netflix, e Databricks.
4.1. Introdução do lago de dados
Devolvemos pela primeira vez a nossa atenção para o lago de dados, um novo tipo de armazenamento de dados tanto para dados estruturados como não estruturados. Data lake é perfeito para o armazenamento de dados na cadeia, uma vez que os formatos de dados na cadeia variam amplamente desde dados brutos não estruturados a dados estruturados de abstracção Footprint Analytics é bem conhecida por. Esperávamos utilizar o data lake para resolver o problema do armazenamento de dados, e idealmente também suportaria os principais motores de computação, tais como Spark e Flink, para que não fosse uma dor de cabeça integrar com diferentes tipos de motores de processamento à medida que a Footprint Analytics evolui.
O Iceberg integra-se muito bem com Spark, Flink, Trino e outros motores computacionais, e podemos escolher o cálculo mais apropriado para cada uma das nossas métricas. Para example:
- Para aqueles que requerem uma lógica computacional complexa, Spark será a escolha.
- Flink para cálculo em tempo real.
- Para tarefas ETL simples que podem ser executadas usando SQL, usamos Trino.
4.2. Motor de consulta
Com a Iceberg a resolver os problemas de armazenamento e computação, tivemos de pensar em escolher um motor de consulta. Não há muitas opções disponíveis. As alternativas que considerámos foram
- Trino: Motor de Consulta SQL
- Presto: Motor de Consulta SQL
- Kyuubi: SQL sem Servidor
A coisa mais importante que considerámos antes de ir mais fundo foi que o futuro motor de consulta tinha de ser compatível com a nossa arquitectura actual.
- Para apoiar a Bigquery como fonte de dados
- Para apoiar a DBT, na qual dependemos para a produção de muitas métricas
- Para suportar a metabase de ferramentas BI
Baseado no acima exposto, escolhemos o Trino, que tem muito bom suporte para o Iceberg e a equipa foi tão receptiva que levantamos um bug, que foi corrigido no dia seguinte e lançado para a última versão na semana seguinte. Esta foi a melhor escolha para a equipa Footprint, que também requer uma elevada capacidade de resposta de implementação.
4.3. Teste de desempenho
Após termos decidido a nossa direcção, fizemos um teste de desempenho sobre a combinação Trino + Iceberg para ver se conseguia satisfazer as nossas necessidades e, para nossa surpresa, as perguntas foram incrivelmente rápidas.
Sabendo que o Presto + Colmeia tem sido o pior comparador durante anos em todo o hype OLAP, a combinação de Trino + Iceberg deu-nos cabo da cabeça.
Aqui estão os resultados dos nossos testes.
caso 1: junte-se a um grande conjunto de dados
Uma tabela de 800 GB1 junta-se a outra tabela de 50 GB2 e faz cálculos comerciais complexos
case2: utilizar uma grande mesa única para fazer uma consulta distinta
Teste sql: seleccionar distinto(endereço) do grupo da tabela por dia

A combinação Trino+Iceberg é cerca de 3 vezes mais rápida do que Doris na mesma configuração.
Além disso, há outra surpresa porque o Iceberg pode utilizar formatos de dados como Parquet, ORC, etc., que irão comprimir e armazenar os dados. O armazenamento da tabela do Iceberg ocupa apenas cerca de 1/5 do espaço de outros armazéns de dados O tamanho do armazenamento da mesma tabela nas três bases de dados é o seguinte:
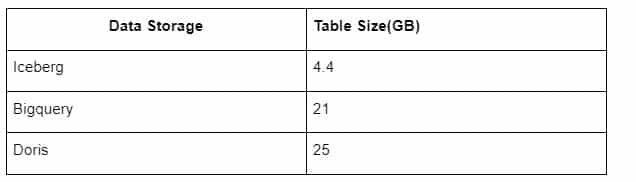
Nota: Os testes acima são exemplos que encontramos na produção real e são apenas para referência.
4.4. Efeito de actualização
Os relatórios dos testes de desempenho deram-nos desempenho suficiente para que a nossa equipa levasse cerca de 2 meses a completar a migração, e este é um diagrama da nossa arquitectura após a actualização.
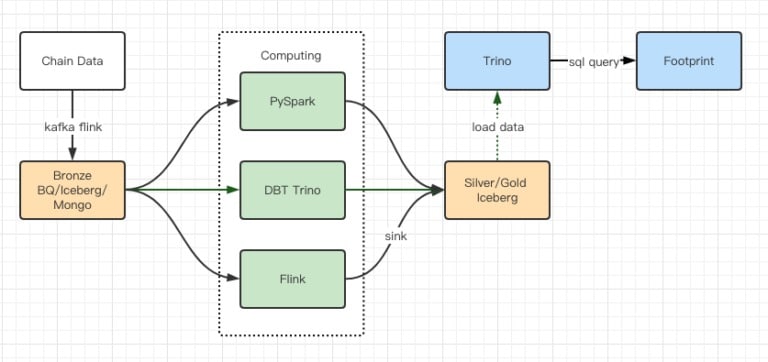
- Múltiplos motores de computador correspondem às nossas várias necessidades.
- Trino suporta DBT, e pode consultar directamente o Iceberg, pelo que já não temos de lidar com a sincronização de dados.
- A incrível performance do Trino + Iceberg permite-nos abrir todos os dados de Bronze (dados brutos) aos nossos utilizadores.
5. Sumário
Desde o seu lançamento em Agosto de 2021, a equipa Footprint Analytics completou três actualizações de arquitectura em menos de um ano e meio, graças ao seu forte desejo e determinação de trazer os benefícios da melhor tecnologia de base de dados aos seus utilizadores de criptografia e sólida execução na implementação e actualização das suas infra-estruturas e arquitectura subjacentes.
A actualização da arquitectura Footprint Analytics 3.0 comprou uma nova experiência para os seus utilizadores, permitindo a utilizadores de diferentes origens obterem conhecimentos em utilizações e aplicações mais diversas:
- Built com a ferramenta Metabase BI, Footprint facilita aos analistas o acesso a dados descodificados na cadeia, explorar com total liberdade de escolha de ferramentas (sem código ou hardcord), consultar todo o histórico, e contra-interrogar conjuntos de dados, para obter conhecimentos em tempo nenhum.
- Integra os dados na cadeia e fora da cadeia para análise across web2 + web3;
- Ao construir / consultar métricas no topo da abstracção comercial da Pegada Ecológica, os analistas ou programadores poupam tempo em 80% do trabalho repetitivo de processamento de dados e concentram-se em métricas significativas, pesquisa, e soluções de produto baseadas no seu negócio.
- Experiência sem igual da Web de Pegada Ecológica a chamadas API REST, todas baseadas em SQL
Alertas em tempo real e notificações acionáveis sobre sinais-chave para apoiar decisões de investimento