
1.モダンなブロックチェーンデータスタックへの挑戦
。
モダンなブロックチェーンインデックススタートアップが直面する可能性のある課題は、以下の通りです:
。
- 膨大な量のデータ。ブロックチェーン上のデータ量が増加すると、データインデックスは、増加した負荷を処理し、データへの効率的なアクセスを提供するためにスケールアップする必要があります。その結果、ストレージコストの上昇、メトリクス計算の遅延、データベースサーバーの負荷上昇を招きます。
- 複雑なデータ処理パイプライン。ブロックチェーン技術は複雑であり、包括的で信頼性の高いデータインデックスを構築するには、基盤となるデータ構造とアルゴリズムについて深く理解する必要があります。ブロックチェーンの実装の多様性はそれを受け継いでいます。具体例を挙げると、イーサリアムにおけるNFTは通常、ERC721およびERC1155の形式に従ってスマートコントラクト内で作成されます。一方、例えばPolkadotでのそれらの実装は、通常ブロックチェーンランタイム内で直接構築されます。それらはNFTとみなされ、それらとして保存されるべきです。
- 統合能力。ユーザーに最大限の価値を提供するために、ブロックチェーンインデックスソリューションは、そのデータインデックスを分析プラットフォームやAPIなどの他のシステムと統合する必要がある場合があります。これは困難なことであり、アーキテクチャ設計に大きな労力をかける必要があります。
のように。
ブロックチェーン技術が普及するにつれ、ブロックチェーンに保存されるデータの量も増えてきました。これは、より多くの人々がこの技術を利用し、取引のたびにブロックチェーンに新しいデータが追加されるためです。さらに、ブロックチェーン技術は、ビットコインを使用するような単純な送金用途から、スマートコントラクト内のビジネスロジックの実装を含むより複雑な用途へと発展してきました。これらのスマートコントラクトは大量のデータを生成する可能性があり、ブロックチェーンの複雑化とサイズアップに寄与しています。時間の経過とともに、これはより大きく、より複雑なブロックチェーンにつながりました。
この記事では、Footprint Analyticsの技術アーキテクチャの進化をケーススタディとして段階的にレビューし、Iceberg-Trinoの技術スタックがどのようにオンチェーンデータの課題に対処しているのかを探ります。
Footprint Analyticsは、約22のパブリックブロックチェーンデータと、17のNFTマーケットプレイス、1900のGameFiプロジェクト、そして10万以上のNFTコレクションを意味的に抽象化したデータレイヤーに索引付けしています。これは、世界で最も包括的なブロックチェーンデータウェアハウスソリューションです。
データアナリストが頻繁にクエリーを行う200億行以上の金融取引の記録を含むブロックチェーンデータにかかわらず、従来のデータウェアハウスにおけるイングレッションログとは異なるものです。
増大するビジネス要件に対応するため、過去数カ月の間に3回のメジャーアップグレードを経験しました:
。
2. アーキテクチャ 1.0 Bigquery
フットプリントアナリティクスの設立当初は、Google Bigqueryをストレージとクエリエンジンとして使用していました。Bigqueryは非常に高速で使いやすく、動的な演算能力と柔軟なUDF構文を備えているため、仕事を素早くこなすことができます。
しかし、Bigqueryにもいくつかの問題があります。
- データは圧縮されないため、特にFootprint Analyticsの22以上のブロックチェーンの生データを保存する場合、高いコストが発生します。
- 不十分な同時実行性。Bigqueryは100の同時クエリしかサポートしておらず、多数のアナリストやユーザーにサービスを提供するFootprint Analyticsの高連続性シナリオには不向きです。
- クローズドソース製品であるGoogle Bigqueryでロックインする。
そこで私たちは、他の代替アーキテクチャを検討することにしました。
3. アーキテクチャ 2.0 OLAP
私たちは、非常に人気のあるOLAP製品のいくつかに非常に興味を持ちました。OLAPの最大の魅力は、膨大なデータに対して通常数秒以下でクエリ結果を返すというクエリ応答時間であり、数千の同時クエリにも対応できることです。
私たちは、最高のOLAPデータベースの1つであるDorisを選び、試してみることにしました。このエンジンの性能は上々です。しかし、ある時点から別の問題に直面するようになりました。
- ArrayやJSONのようなデータ型はまだサポートされていません(2022年11月)。Arrayは一部のブロックチェーンでよく使われるデータ型です。例えば、evm logsのtopicフィールドなど。Arrayで計算できないことは、多くのビジネスメトリクスを計算する能力に直接影響します。
- DBT、およびマージステートメントのサポートが制限されています。これらは、新しくインデックスされたデータを更新する必要がある ETL/ELT シナリオのデータエンジニアの一般的な要件です。
。
そうは言っても、本番のデータパイプライン全体にDorisを使うわけにはいかないので、データ制作パイプラインの問題の一部を解決するために、DorisをOLAPデータベースとして使い、クエリーエンジンとして機能させて高速かつ高度な並列クエリー機能を提供しようと試みました。
残念ながらBigqueryをDorisに置き換えることはできなかったので、Bigqueryをクエリエンジンとして使って定期的にDorisにデータを同期させる必要がありました。この同期処理にはいくつかの問題があり、その一つが、OLAPエンジンがフロントエンドクライアントへのクエリ提供に忙しくなると、更新の書き込みがすぐに溜まってしまうことでした。その結果、書き込み速度が低下し、同期処理に時間がかかり、終了できなくなることもありました。
OLAPは、私たちが直面しているいくつかの問題を解決することができますが、Footprint Analyticsのターンキーソリューション、特にデータ処理パイプラインにはなり得ないことに気づきました。私たちの問題はより大きく、より複雑であり、クエリエンジンとしてのOLAPだけでは十分でないと言えるでしょう。
4. アーキテクチャ3.0 Iceberg + Trino
フットプリントアナリティクスアーキテクチャ3.0へようこそ!基本アーキテクチャの完全なオーバーホールを行いました。データの保存、計算、クエリーを3つに分離するために、アーキテクチャ全体を一から設計し直しました。Footprint Analyticsの以前の2つのアーキテクチャから教訓を得るとともに、Uber、Netflix、Databricksといった他のビッグデータプロジェクトの成功例から学びました。
4.1. データレイクの導入
。
私たちはまず、構造化データと非構造化データの両方に対応する新しいタイプのデータストレージであるデータレイクに注目しました。オンチェーンデータの形式は、非構造化ローデータからフットプリント・アナリティクスがよく知る構造化抽象化データまで幅広いため、データレイクはオンチェーンデータストレージに最適なのです。データレイクを使ってデータストレージの問題を解決することを期待しましたが、SparkやFlinkといった主流の計算エンジンもサポートし、Footprint Analyticsが進化しても異なる種類の処理エンジンと統合することが苦にならないようにすることが理想的です。
IcebergはSpark、Flink、Trinoなどの計算エンジンと非常によく統合されており、各メトリクスに最適な計算を選択することができます。例えば:
- 複雑な計算ロジックを必要とするものにはSparkを選択することになります。
- リアルタイムな計算が必要な場合はFlink。
- SQLで実行できる簡単なETLタスクには、Trinoを使用します。
を使用します。
4.2. クエリエンジン
Icebergがストレージと計算の問題を解決したことで、私たちはクエリーエンジンの選定を考える必要がありました。選択肢はそれほど多くありません。私たちが考えた選択肢は
です。
- Trinoです。SQLクエリエンジン
- Prestoです。SQLクエリエンジン
- Kyuubi。サーバーレスSpark SQL
深化する前に考慮した最も重要なことは、将来のクエリーエンジンが現在のアーキテクチャと互換性がなければならないということでした
。
- データソースとしてBigqueryをサポートするために
- 多くのメトリクスを生成するために依存しているDBTをサポートすること
- BIツールのメタベースをサポートするため
上記を踏まえ、Icebergのサポートが非常に充実しており、バグを指摘すると翌日には修正され、翌週には最新バージョンにリリースされるなど、チームの対応が非常に良かったトリノを選びました。同じく高い実装対応力が求められるFootprintチームにとっても、ベストな選択でしたね」
。
4.3. パフォーマンステスト
方向性が決まったところで、Trino + Icebergの組み合わせでニーズを満たせるかどうかパフォーマンステストを行ったところ、驚いたことにクエリが驚くほど高速になったのです。
Presto + Hiveは、OLAPの宣伝の中で何年も最悪の比較対象だったことを知っていたので、Trino + Icebergの組み合わせは完全に我々の度肝を抜いたのです。
以下はテスト結果です。
ケース1:大きなデータセットに結合する
800GBのテーブル1が50GBのテーブル2と結合し、複雑なビジネス計算を行います。
case2: 大きな単一テーブルを使ったdistinctクエリ
テストsql: select distinct(address) from the table group by day

トリノ+アイスバーグの組み合わせは、同じ構成のドリスと比べて約3倍の速さです。
さらに、IcebergはParquetやORCなどのデータ形式を使うことができるので、データを圧縮して保存してくれるからもう一つ驚きがあります。Icebergのテーブルストレージは、他のデータウェアハウスの約1/5のスペースしか必要としません 3つのデータベースにおける同じテーブルのストレージサイズは以下の通りです:
。
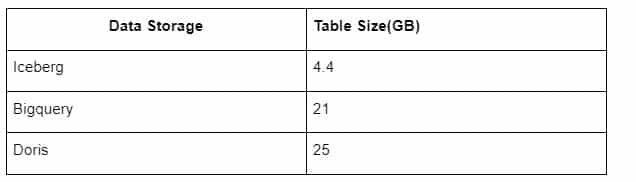
注:上記のテストは実際の制作現場で遭遇した例であり、あくまで参考です
4
4.4. アップグレードの効果
パフォーマンステストのレポートでは十分なパフォーマンスが得られたため、私たちのチームは移行を完了するのに約2カ月かかりました。これはアップグレード後のアーキテクチャの図です
。
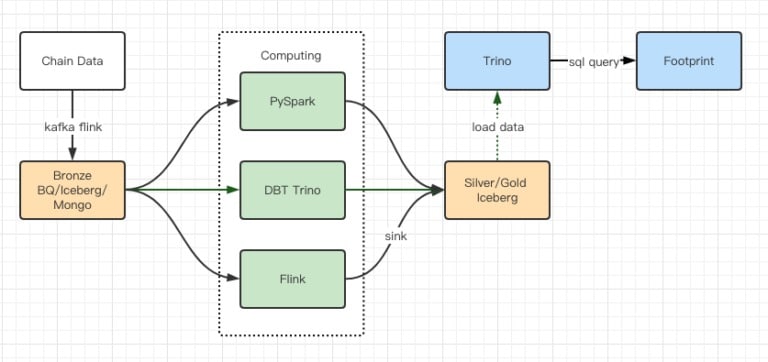
- 複数のコンピュータエンジンが、私たちのさまざまなニーズにマッチしています。
- TrinoはDBTをサポートしており、Icebergに直接問い合わせることができるので、データの同期に悩まされることがなくなりました。
- TrinoとIcebergの素晴らしいパフォーマンスにより、すべてのブロンズデータ(生データ)をユーザーに開放することができます。
5. まとめ
2021年8月の発売以来、Footprint Analyticsチームは、暗号ユーザーに最高のデータベース技術の恩恵をもたらすという強い願いと決意、そして基盤となるインフラとアーキテクチャの実装とアップグレードに関する堅実な実行により、1年半足らずで3回のアーキテクチャのアップグレードを完了させました。
Footprint Analyticsアーキテクチャーのアップグレード3.0は、ユーザーに新しい体験を提供し、さまざまなバックグラウンドを持つユーザーがより多様な使用法と用途で洞察を得ることを可能にしました。
- MetabaseBIツールで構築されたFootprintにより、アナリストはデコードされたオンチェーンデータにアクセスし、ツールを自由に選択して(ノーコードまたはハードコード)探索し、履歴全体を照会してデータセットを相互検証し、すぐに洞察を得ることができるようになりました。
- オンチェーンデータとオフチェーンデータを統合し、Web2+Web3で分析することができます。
- Footprintのビジネス抽象化の上に測定基準を構築/照会することで、アナリストや開発者は反復的なデータ処理作業の80%の時間を節約し、ビジネスに基づいた有意義な測定基準、調査、製品ソリューションに集中することができます。
- FootprintウェブからREST APIコールまで、すべてSQLをベースにしたシームレスなエクスペリエンス
投資判断をサポートする重要なシグナルに関するリアルタイムのアラートと実用的な通知
。