
1.Предизвикателството пред модерния стек за данни за блокчейн
Съществуват няколко предизвикателства, с които може да се сблъска един модерен стартъп за индексиране на блокчейн, включително:
- Масивни количества данни. С увеличаването на обема на данните в блокчейн индексът на данните ще трябва да се мащабира, за да се справи с повишеното натоварване и да осигури ефективен достъп до данните. Следователно това води до по-високи разходи за съхранение, бавно изчисляване на метриките и повишено натоварване на сървъра за бази данни.
- Сложен конвейер за обработка на данни. Блокчейн технологията е сложна и изграждането на цялостен и надежден индекс на данните изисква дълбоко разбиране на основните структури и алгоритми за данни. Разнообразието на блокчейн реализациите го наследява. Като се имат предвид конкретни примери, NFT в Ethereum обикновено се създават в рамките на интелигентни договори, следвайки форматите ERC721 и ERC1155. За разлика от тях, реализацията на тези в Polkadot, например, обикновено се изгражда директно в рамките на блокчейн runtime. Те трябва да се считат за НФТ и да се запазват като такива.
- Възможности за интеграция. За да осигури максимална стойност за потребителите, решението за индексиране на блокчейн може да се наложи да интегрира своя индекс на данни с други системи, като например платформи за анализ или API. Това е предизвикателство и изисква значителни усилия, вложени в проектирането на архитектурата.
С все по-широкото разпространение на блокчейн технологията се увеличава и количеството данни, съхранявани в блокчейн. Това е така, защото все повече хора използват технологията и всяка транзакция добавя нови данни към блокчейна. Освен това блокчейн технологията еволюира от прости приложения за прехвърляне на пари, като например тези, включващи използването на биткойн, до по-сложни приложения, включващи прилагането на бизнес логика в рамките на интелигентни договори. Тези интелигентни договори могат да генерират големи количества данни, което допринася за по-голямата сложност и размер на блокчейна. С течение на времето това доведе до по-голяма и по-сложна блокчейн.
В тази статия разглеждаме еволюцията на технологичната архитектура на Footprint Analytics на етапи като казус, за да проучим как технологичният стек Iceberg-Trino се справя с предизвикателствата на данните във веригата.
Footprint Analytics е индексирал около 22 публични блокчейн данни и 17 пазара на НФТ, 1900 проекта GameFi и над 100 000 колекции на НФТ в семантичен абстрактен слой от данни. Това е най-изчерпателното решение за склад за блокчейн данни в света.
Независимо от блокчейн данните, които включват над 20 милиарда реда записи на финансови транзакции, които анализаторите на данни често правят справки. това е различно от логовете за ингресия в традиционните складове за данни.
През последните няколко месеца претърпяхме 3 големи подобрения, за да отговорим на нарастващите бизнес изисквания:
2. Архитектура 1.0 Bigquery
В началото на Footprint Analytics използвахме Google Bigquery като двигател за съхранение и заявки; Bigquery е чудесен продукт. Той е светкавично бърз, лесен за използване и предоставя динамична аритметична мощ и гъвкав синтаксис на UDF, които ни помагат бързо да свършим работата си.
Въпреки това Bigquery има и няколко проблема.
- Данните не се компресират, което води до високи разходи, особено при съхраняването на необработени данни от над 22 блокчейна на Footprint Analytics.
- Недостатъчна едновременност: Bigquery поддържа само 100 едновременни заявки, което е неподходящо за сценарии с висока едновременност за Footprint Analytics, когато обслужва много анализатори и потребители.
- Включване с Google Bigquery, който е продукт със затворен код。
Затова решихме да проучим други алтернативни архитектури.
3. Архитектура 2.0 OLAP
Много се интересувахме от някои от продуктите OLAP, които бяха станали много популярни. Най-привлекателното предимство на OLAP е времето за отговор на заявката, което обикновено отнема под секунди за връщане на резултатите от заявката за огромни количества данни, а освен това може да поддържа хиляди едновременни заявки.
Избрахме една от най-добрите OLAP бази данни, Doris, за да я изпробваме. Този двигател се представя добре. В някакъв момент обаче скоро се сблъскахме с някои други проблеми:
- Типове данни като Array или JSON все още не се поддържат (ноември, 2022 г.). Масивите са често срещан тип данни в някои блокови вериги. Например полето за тема в логовете на evm. Невъзможността за изчисляване върху Array пряко засяга способността ни да изчисляваме много бизнес показатели.
- Ограничена поддръжка за DBT и за изявления за сливане. Това са често срещани изисквания на инженерите по данни за ETL/ELT сценарии, при които трябва да актуализираме някои новоиндексирани данни.
При това не можахме да използваме Doris за целия си производствен конвейер за данни, затова се опитахме да използваме Doris като OLAP база данни, за да решим част от проблема си в производствения конвейер за данни, действайки като двигател за заявки и осигурявайки бързи и високосъвременни възможности за заявки.
За съжаление не можехме да заменим Bigquery с Doris, така че трябваше периодично да синхронизираме данните от Bigquery към Doris, използвайки го като двигател за заявки. Този процес на синхронизация имаше няколко проблема, един от които беше, че записите на актуализации се натрупваха бързо, когато OLAP двигателят беше зает с обслужването на заявки към клиентите от предния край. Впоследствие това се отразяваше на скоростта на процеса на запис и синхронизацията отнемаше много повече време, а понякога дори ставаше невъзможно да бъде завършена.
Осъзнахме, че OLAP може да реши няколко проблема, пред които сме изправени, и не може да се превърне в готово решение на Footprint Analytics, особено за конвейера за обработка на данни. Нашият проблем е по-голям и по-сложен и можем да кажем, че OLAP само като двигател за заявки не е достатъчен за нас.
4. Архитектура 3.0 Iceberg + Trino
Добре дошли в Архитектура 3.0 на Footprint Analytics, пълна промяна на основната архитектура. Преработихме цялата архитектура из основи, за да разделим съхранението, изчисленията и търсенето на данни на три различни части. Вземайки поуки от двете предишни архитектури на Footprint Analytics и учейки се от опита на други успешни проекти за големи данни като Uber, Netflix и Databricks.
4.1. Въвеждане на езерото от данни
На първо място обърнахме внимание на езерото от данни – нов тип съхранение на данни за структурирани и неструктурирани данни. Езерото от данни е идеално за съхранение на данни във веригата, тъй като форматите на данните във веригата варират в широки граници – от неструктурирани необработени данни до структурирани абстрактни данни, с които Footprint Analytics е добре известен. Очаквахме да използваме езерото от данни, за да решим проблема със съхранението на данни, а в идеалния случай то би поддържало и основните изчислителни двигатели като Spark и Flink, така че да не е мъчително да се интегрира с различни видове двигатели за обработка, докато Footprint Analytics се развива.
Iceberg се интегрира много добре със Spark, Flink, Trino и други изчислителни двигатели и ние можем да изберем най-подходящото изчисление за всяка от нашите метрики. Например:
- За тези, които изискват сложна изчислителна логика, изборът ще бъде Spark.
- Flink за изчисления в реално време.
- За прости ETL задачи, които могат да се изпълняват с помощта на SQL, използваме Trino.
4.2. Механизъм за заявки
След като Iceberg реши проблемите със съхранението и изчисленията, трябваше да помислим за избора на двигател за заявки. Не са налични много възможности. Алтернативите, които разгледахме, бяха
- Trino: Запитване за SQL
- Presto: SQL Query Engine
- Kyuubi: Безсървърна Spark SQL
Най-важното нещо, което взехме предвид, преди да се задълбочим, беше, че бъдещият двигател за заявки трябва да бъде съвместим с настоящата ни архитектура.
- За да поддържаме Bigquery като източник на данни
- Да поддържа DBT, на който разчитаме за изготвянето на много метрики
- За поддръжка на метабазата на BI инструмента
Възоснова на гореизложеното избрахме Trino, който има много добра поддръжка за Iceberg, а екипът беше толкова отзивчив, че повдигнахме въпрос за грешка, която беше отстранена на следващия ден и пусната в най-новата версия през следващата седмица. Това беше най-добрият избор за екипа на Footprint, който също изисква висока отзивчивост на внедряването.
4.3. Тестване на производителността
След като взехме решение за нашата посока, направихме тест за производителност на комбинацията Trino + Iceberg, за да видим дали тя може да отговори на нашите нужди, и за наша изненада заявките бяха невероятно бързи.
Знаейки, че Presto + Hive от години е най-лошият сравнител в цялата шумотевица около OLAP, комбинацията Trino + Iceberg напълно ни взриви.
Ето и резултатите от нашите тестове.
случай 1: обединяване на голямо множество от данни
Таблица1 с обем 800 GB се присъединява към друга таблица2 с обем 50 GB и извършва сложни бизнес изчисления
случай2: използване на голяма единична таблица за извършване на различно запитване
Тестово sql: select distinct(address) from the table group by day

Комбинацията Trino+Iceberg е около 3 пъти по-бърза от Doris в същата конфигурация.
Освен това има и друга изненада, защото Iceberg може да използва формати за данни като Parquet, ORC и т.н., които ще компресират и съхраняват данните. Съхранението на таблиците на Iceberg заема само около 1/5 от пространството на другите складове за данни Размерът на съхранението на една и съща таблица в трите бази данни е както следва:
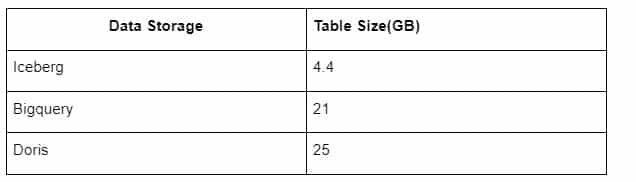
Забележка: Горните тестове са примери, с които сме се сблъскали в реалното производство, и са само за справка.
4.4. Ефект от обновяването
Докладите от тестовете за производителност ни дадоха достатъчна производителност, за да отнеме на екипа ни около 2 месеца да завърши миграцията, а това е диаграма на нашата архитектура след надграждането.
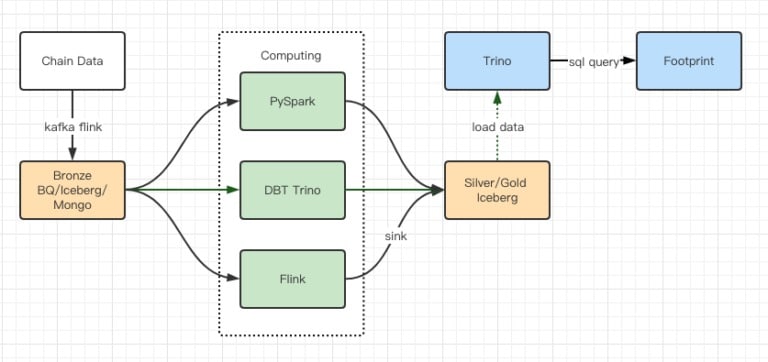
- Многобройни компютърни двигатели отговарят на различните ни нужди.
- Trino поддържа DBT и може да прави директни заявки към Iceberg, така че вече не е необходимо да се занимаваме със синхронизиране на данни.
- Удивителната производителност на Trino + Iceberg ни позволява да отворим всички данни от Бронза (необработени данни) за нашите потребители.
5. Обобщение
След стартирането си през август 2021 г. екипът на Footprint Analytics завърши три архитектурни обновявания за по-малко от година и половина, благодарение на силното си желание и решимост да предостави предимствата на най-добрата технология за бази данни на своите криптопотребители и солидното изпълнение на задачите по внедряване и обновяване на основната инфраструктура и архитектура.
Архитектурният ъпгрейд Footprint Analytics 3.0 купи ново изживяване на своите потребители, позволявайки на потребители от различни среди да получат прозрения при по-разнообразна употреба и приложения:
- Създаден с инструмента Metabase BI, Footprint улеснява анализаторите да получат достъп до декодирани данни по веригата, да изследват с пълна свобода на избор на инструменти (без код или с твърд код), да правят справки в цялата история и да правят кръстосани анализи на набори от данни, за да получат прозрения за нула време.
- Интегриране на данни от веригата и извън нея за анализ в web2 + web3;
- Създавайки/запитвайки метрики върху бизнес абстракцията на Footprint, анализаторите или разработчиците спестяват време за 80% от повтарящата се работа по обработка на данни и се фокусират върху значими метрики, изследвания и продуктови решения, базирани на техния бизнес.
- Безпроблемно преживяване от Footprint Web до REST API повиквания, всичко това на базата на SQL
Предупреждения в реално време и известия за действия по ключови сигнали в подкрепа на инвестиционните решения