
1.Výzva pro moderní datový stack pro blockchain
Moderní startup pro indexování blockchainu může čelit několika výzvám, mezi které patří:
- Masivní množství dat. S rostoucím množstvím dat v blockchainu bude muset datový index škálovat, aby zvládl zvýšenou zátěž a zajistil efektivní přístup k datům. V důsledku toho dochází k vyšším nákladům na ukládání dat, pomalému výpočtu metrik a zvýšenému zatížení databázového serveru.
- Komplexní potrubí pro zpracování dat. Technologie blockchainu je složitá a vytvoření komplexního a spolehlivého datového indexu vyžaduje hluboké pochopení základních datových struktur a algoritmů. Dědí se to z rozmanitosti implementací blockchainu. Vzhledem ke konkrétním příkladům jsou NFT v Ethereu obvykle vytvářeny v rámci chytrých kontraktů podle formátů ERC721 a ERC1155. Oproti tomu například implementace těch na Polkadotu je obvykle vytvořena přímo v rámci runtime blockchainu. Ty by měly být považovány za NFT a měly by být jako takové uloženy.
- Možnosti integrace. Aby řešení pro indexování blockchainu poskytovalo uživatelům maximální hodnotu, může být nutné integrovat jeho datový index s jinými systémy, jako jsou analytické platformy nebo rozhraní API. To je náročné a vyžaduje to značné úsilí vložené do návrhu architektury.
S rozšířením technologie blockchain se zvýšilo množství dat uložených v blockchainu. Je to proto, že tuto technologii používá stále více lidí a každá transakce přidává do blockchainu nová data. Kromě toho se technologie blockchain vyvinula z jednoduchých aplikací pro převod peněz, jako je například použití Bitcoinu, na složitější aplikace zahrnující implementaci obchodní logiky v rámci inteligentních smluv. Tyto inteligentní smlouvy mohou generovat velké množství dat, což přispívá k větší složitosti a velikosti blockchainu. Postupem času to vedlo ke vzniku většího a složitějšího blockchainu.
V tomto článku přezkoumáme vývoj technologické architektury společnosti Footprint Analytics v jednotlivých fázích jako případovou studii, abychom zjistili, jak technologický stack Iceberg-Trino řeší problémy s daty v řetězci.
Společnost Footprint Analytics indexovala přibližně 22 veřejných dat blockchainu a 17 tržišť NFT, 1900 projektů GameFi a více než 100 000 sbírek NFT do sémantické abstrakční datové vrstvy. Jedná se o nejkomplexnější řešení blockchainového datového skladu na světě.
Bez ohledu na blockchainová data, která zahrnují více než 20 miliard řádků záznamů o finančních transakcích, na které se datoví analytici často dotazují. to je rozdíl oproti ingresním záznamům v tradičních datových skladech.
V posledních několika měsících jsme prošli třemi zásadními upgrady, abychom vyhověli rostoucím požadavkům byznysu:
2. Architektura 1.0 Bigquery
Na začátku služby Footprint Analytics jsme jako úložný a dotazovací engine používali Google Bigquery; Bigquery je skvělý produkt. Je bleskově rychlý, snadno se používá a poskytuje dynamickou aritmetickou sílu a flexibilní syntaxi UDF, která nám pomáhá rychle zpracovávat úlohy.
Bigquery má však také několik problémů.
- Data nejsou komprimována, což vede k vysokým nákladům, zejména při ukládání surových dat více než 22 blokových řetězců Footprint Analytics.
- Nedostatečná souběžnost: Bigquery podporuje pouze 100 současných dotazů, což je nevhodné pro scénáře s vysokou souběžností pro Footprint Analytics při obsluze mnoha analytiků a uživatelů.
- Závislost na službě Google Bigquery, která je produktem s uzavřeným zdrojovým kódem。
Proto jsme se rozhodli prozkoumat další alternativní architektury.
3. Architektura 2.0 OLAP
Velmi nás zaujaly některé produkty OLAP, které se staly velmi populárními. Nejatraktivnější výhodou OLAP je doba odezvy dotazu, která u obrovského množství dat obvykle trvá pod sekundami a může také podporovat tisíce souběžných dotazů.
Vybrali jsme jednu z nejlepších databází OLAP, Doris, abychom ji vyzkoušeli. Tento engine si vede dobře. V určitém okamžiku jsme však brzy narazili na další problémy:
- Datové typy jako pole nebo JSON zatím nejsou podporovány (listopad, 2022). Pole jsou běžným typem dat v některých blockchainech. Například pole topic v logách evm. Nemožnost počítat na poli Array přímo ovlivňuje naši schopnost počítat mnoho obchodních metrik.
- Omezená podpora pro DBT a pro příkazy sloučení. Jedná se o běžné požadavky datových inženýrů pro scénáře ETL/ELT, kdy potřebujeme aktualizovat některá nově indexovaná data.
Také jsme nemohli použít Doris pro celý náš produkční datový tok, a proto jsme se pokusili použít Doris jako databázi OLAP, abychom vyřešili část našeho problému v produkčním datovém toku, fungující jako dotazovací stroj a poskytující rychlé a vysoce souběžné možnosti dotazování.
Bohužel jsme nemohli nahradit databázi Bigquery databází Doris, takže jsme museli pravidelně synchronizovat data z databáze Bigquery do databáze Doris a používat ji jako dotazovací stroj. Tento synchronizační proces měl několik problémů, z nichž jeden spočíval v tom, že se zápisy aktualizací rychle hromadily, když byl engine OLAP zaneprázdněn obsluhou dotazů pro klienty front-endu. Následně to ovlivnilo rychlost procesu zápisu a synchronizace trvala mnohem déle a někdy ji dokonce nebylo možné dokončit.
Uvědomili jsme si, že OLAP by mohl vyřešit několik problémů, se kterými se potýkáme, a nemohl by se stát řešením Footprint Analytics na klíč, zejména pro konjunkturu zpracování dat. Náš problém je větší a složitější a dá se říci, že OLAP jako samotný dotazovací engine nám nestačil.
4. Architektura 3.0 Iceberg + Trino
Vítejte v architektuře Footprint Analytics 3.0, která představuje kompletní přepracování základní architektury. Celou architekturu jsme od základu přepracovali, abychom oddělili ukládání, výpočty a dotazování dat do tří různých částí. Vycházíme ze zkušeností dvou předchozích architektur Footprint Analytics a ze zkušeností dalších úspěšných projektů v oblasti velkých dat, jako jsou Uber, Netflix a Databricks.
4.1. Představení datového jezera
Nejprve jsme se zaměřili na datové jezero, nový typ datového úložiště pro strukturovaná i nestrukturovaná data. Datové jezero je ideální pro ukládání dat v řetězci, protože formáty dat v řetězci se pohybují v širokém rozmezí od nestrukturovaných surových dat až po strukturovaná abstraktní data, kterými je společnost Footprint Analytics dobře známá. Očekávali jsme, že datové jezero vyřeší problém s ukládáním dat a v ideálním případě bude také podporovat běžné výpočetní enginy, jako jsou Spark a Flink, aby nebylo obtížné integrovat je s různými typy zpracovatelských enginů v průběhu vývoje služby Footprint Analytics.
Iceberg se velmi dobře integruje se Sparkem, Flinkem, Trinem a dalšími výpočetními enginy a my si můžeme vybrat nejvhodnější výpočet pro každou z našich metrik. Například:
- Pro ty, které vyžadují složitou výpočetní logiku, bude volbou Spark.
- Flink pro výpočty v reálném čase.
- Pro jednoduché úlohy ETL, které lze provádět pomocí jazyka SQL, použijeme Trino.
4.2. Query engine
Když Iceberg řeší problémy s ukládáním a výpočty, museli jsme se zamyslet nad výběrem dotazovacího stroje. K dispozici není mnoho možností. Alternativy, které jsme zvažovali, byly
- Trino: SQL Query Engine
- Presto: SQL Query Engine
- Kyuubi: SQL bez serveru Spark
Nejdůležitější věc, kterou jsme zvažovali předtím, než jsme šli hlouběji, byla, že budoucí dotazovací engine musí být kompatibilní s naší současnou architekturou.
- Aby bylo možné podporovat Bigquery jako zdroj dat.
- Aby podporoval DBT, na kterém se spoléháme při vytváření mnoha metrik.
- Pro podporu metabáze nástrojů BI
Na základě výše uvedeného jsme si vybrali společnost Trino, která má velmi dobrou podporu pro Iceberg a její tým reagoval tak vstřícně, že jsme upozornili na chybu, která byla následující den opravena a následující týden uvolněna do nejnovější verze. To byla nejlepší volba pro tým Footprint, který také vyžaduje vysokou odezvu implementace.
4.3. Testování výkonu
Když jsme se rozhodli pro náš směr, provedli jsme výkonnostní test kombinace Trino + Iceberg, abychom zjistili, zda může splnit naše potřeby, a k našemu překvapení byly dotazy neuvěřitelně rychlé.
S vědomím toho, že Presto + Hive je ve všem tom OLAPovém humbuku už léta nejhorším srovnávačem, nám kombinace Trino + Iceberg úplně vyrazila dech.
Zde jsou výsledky našich testů.
Případ 1: spojení velké datové sady
Tabulka1 o velikosti 800 GB se připojuje k jiné tabulce2 o velikosti 50 GB a provádí složité obchodní výpočty.
Případ2: použití velké jediné tabulky k provedení odlišného dotazu
Testovací sql: select distinct(address) from the table group by day

Kombinace Trino+Iceberg je ve stejné konfiguraci asi třikrát rychlejší než Doris.
Navíc je tu další překvapení, protože Iceberg umí používat datové formáty jako Parquet, ORC atd. a data komprimuje a ukládá. Uložení tabulky Iceberg zabírá jen asi 1/5 místa ostatních datových skladů Velikost uložení stejné tabulky ve třech databázích je následující:
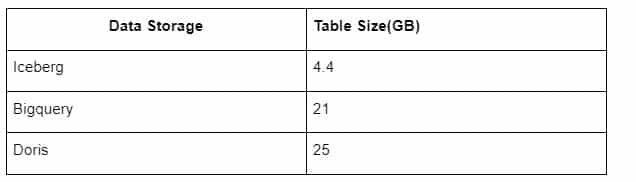
Poznámka: Výše uvedené testy jsou příklady, se kterými jsme se setkali ve skutečné produkci, a slouží pouze jako reference.
4.4. Efekt aktualizace
Zprávy z testů výkonu nám poskytly dostatečný výkon, takže našemu týmu trvalo dokončení migrace asi 2 měsíce, a toto je schéma naší architektury po upgradu.
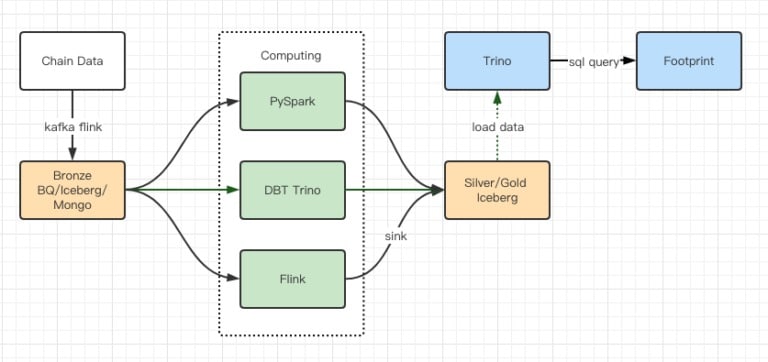
- Více počítačových motorů odpovídá našim různým potřebám.
- Trino podporuje DBT a může se přímo dotazovat na Iceberg, takže už nemusíme řešit synchronizaci dat.
- Úžasný výkon systému Trino + Iceberg nám umožňuje zpřístupnit všechna data z Bronzu (surová data) našim uživatelům.
5. Shrnutí
Od svého spuštění v srpnu 2021 dokončil tým Footprint Analytics tři architektonické upgrady za méně než rok a půl, a to díky své silné touze a odhodlání přinést výhody nejlepší databázové technologie svým uživatelům kryptografických služeb a solidnímu provedení implementace a upgradu základní infrastruktury a architektury.
Upgrade architektury Footprint Analytics 3.0 koupil svým uživatelům nové zkušenosti, které umožňují uživatelům z různých prostředí získat přehled o rozmanitějším využití a aplikacích:
- Připravená s nástrojem Metabase BI, Footprint usnadňuje analytikům získat přístup k dekódovaným datům v řetězci, zkoumat s naprostou svobodou volby nástrojů (bez kódu nebo s pevným kódem), dotazovat se na celou historii a křížově zkoumat datové soubory, aby získali poznatky během okamžiku.
- Integrujte data na řetězci i mimo něj k analýze napříč webem2 + webem3;
- Vytvářením / dotazováním metrik nad obchodní abstrakcí Footprint ušetří analytici nebo vývojáři čas na 80 % opakující se práce se zpracováním dat a mohou se soustředit na smysluplné metriky, výzkum a produktová řešení založená na jejich podnikání.
- Bezproblémové prostředí od webu Footprint po volání REST API, vše na bázi SQL
Upozornění v reálném čase a akční oznámení na klíčové signály na podporu investičních rozhodnutí