
1.Wyzwania dla nowoczesnego stosu danych dla blockchaina
Jest kilka wyzwań, z którymi może się zmierzyć nowoczesny startup indeksujący blockchain, w tym:
- Masywne ilości danych. Wraz ze wzrostem ilości danych na blockchainie, indeks danych będzie musiał się skalować, aby obsłużyć zwiększone obciążenie i zapewnić wydajny dostęp do danych. W konsekwencji prowadzi to do wyższych kosztów przechowywania, powolnego obliczania metryk i zwiększonego obciążenia serwera bazy danych.
- Kompleksowy potok przetwarzania danych. Technologia blockchain jest złożona, a zbudowanie kompleksowego i niezawodnego indeksu danych wymaga głębokiego zrozumienia bazowych struktur danych i algorytmów. Różnorodność implementacji blockchaina dziedziczy to. Biorąc pod uwagę konkretne przykłady, NFT w Ethereum są zwykle tworzone w ramach inteligentnych kontraktów podążających za formatami ERC721 i ERC1155. Z kolei implementacja tychże na przykład na Polkadot jest zazwyczaj budowana bezpośrednio w ramach blockchain runtime. Te powinny być uznane za NFT i powinny być zapisane jako.
- Możliwości integracyjne. Aby zapewnić maksymalną wartość dla użytkowników, rozwiązanie indeksujące blockchain może potrzebować zintegrować swój indeks danych z innymi systemami, takimi jak platformy analityczne lub interfejsy API. Jest to wyzwanie i wymaga znacznego wysiłku włożonego w projekt architektury.
Ponieważ technologia blockchain stała się bardziej powszechna, ilość danych przechowywanych na blockchainie wzrosła. Dzieje się tak, ponieważ więcej osób korzysta z tej technologii, a każda transakcja dodaje nowe dane do blockchaina. Ponadto technologia blockchain ewoluowała od prostych aplikacji do transferu pieniędzy, takich jak te obejmujące wykorzystanie Bitcoina, do bardziej złożonych aplikacji obejmujących wdrożenie logiki biznesowej w ramach inteligentnych kontraktów. Te inteligentne kontrakty mogą generować duże ilości danych, przyczyniając się do zwiększenia złożoności i rozmiaru blockchaina. Z czasem doprowadziło to do powstania większego i bardziej złożonego blockchaina.
W tym artykule dokonujemy przeglądu ewolucji architektury technologicznej Footprint Analytics w etapach jako studium przypadku, aby zbadać, w jaki sposób stos technologiczny Iceberg-Trino rozwiązuje wyzwania związane z danymi on-chain.
Footprint Analytics zindeksował około 22 publicznych danych blockchain, a także 17 rynków NFT, 1900 projektów GameFi i ponad 100 000 kolekcji NFT w semantyczną warstwę danych abstrakcji. Jest to najbardziej kompleksowe rozwiązanie hurtowni danych blockchain na świecie.
Niezależnie od danych blockchain, które obejmują ponad 20 miliardów rzędów rekordów transakcji finansowych, które analitycy danych często pytają. różni się od dzienników ingresji w tradycyjnych hurtowniach danych.
W ciągu ostatnich kilku miesięcy doświadczyliśmy 3 dużych modernizacji, aby sprostać rosnącym wymaganiom biznesowym:
2. Architektura 1.0 Bigquery
Na początku istnienia Footprint Analytics, używaliśmy Google Bigquery jako naszego magazynu i silnika zapytań; Bigquery to świetny produkt. Jest piekielnie szybki, łatwy w użyciu i zapewnia dynamiczną moc arytmetyczną oraz elastyczną składnię UDF, która pomaga nam szybko wykonać pracę.
Jednak Bigquery ma również kilka problemów.
- Dane nie są kompresowane, co powoduje wysokie koszty, szczególnie przy przechowywaniu surowych danych ponad 22 blockchainów Footprint Analytics.
- Niewystarczająca współbieżność: Bigquery obsługuje tylko 100 jednoczesnych zapytań, co jest nieodpowiednie dla scenariuszy wysokiej współbieżności dla Footprint Analytics podczas obsługi wielu analityków i użytkowników.
- Zamknij się w Google Bigquery, który jest produktem zamkniętym。
Więc postanowiliśmy zbadać inne alternatywne architektury.
3. Architektura 2.0 OLAP
Byliśmy bardzo zainteresowani niektórymi produktami OLAP, które stały się bardzo popularne. Najbardziej atrakcyjną zaletą OLAP jest czas odpowiedzi na zapytanie, który zwykle zajmuje sub-sekundy, aby zwrócić wyniki zapytania dla ogromnych ilości danych, a także może obsługiwać tysiące współbieżnych zapytań.
Wybraliśmy jedną z najlepszych baz OLAP, Doris, aby ją wypróbować. Silnik ten sprawuje się dobrze. Jednak w pewnym momencie natrafiliśmy na kilka innych problemów:
- Typy danych takie jak Array czy JSON nie są jeszcze obsługiwane (listopad, 2022). Tablice są częstym typem danych w niektórych blockchainach. Na przykład pole topic w evm logs. Brak możliwości obliczania na Array bezpośrednio wpływa na naszą zdolność do obliczania wielu metryk biznesowych.
- Ograniczone wsparcie dla DBT oraz dla deklaracji łączenia. Są to częste wymagania dla inżynierów danych dla scenariuszy ETL/ELT, gdzie musimy zaktualizować niektóre nowo indeksowane dane.
To powiedziawszy, nie mogliśmy użyć Doris dla naszego całego potoku danych na produkcji, więc próbowaliśmy użyć Doris jako bazy danych OLAP, aby rozwiązać część naszego problemu w potoku produkcyjnym danych, działając jako silnik zapytań i zapewniając szybkie i wysoce współbieżne możliwości zapytań.
Niestety, nie mogliśmy zastąpić Bigquery przez Doris, więc musieliśmy okresowo synchronizować dane z Bigquery do Doris, używając go jako silnika zapytań. Ten proces synchronizacji miał kilka problemów, a jednym z nich było to, że zapisy aktualizacji szybko się spiętrzały, gdy silnik OLAP był zajęty obsługą zapytań do klientów front-end. W konsekwencji, szybkość procesu zapisu ulegała pogorszeniu, a synchronizacja trwała znacznie dłużej, a czasami nawet stawała się niemożliwa do ukończenia.
Zdaliśmy sobie sprawę, że OLAP może rozwiązać kilka problemów, z którymi się borykamy, ale nie może stać się rozwiązaniem „pod klucz” dla Footprint Analytics, zwłaszcza dla potoku przetwarzania danych. Nasz problem jest większy i bardziej złożony, i można powiedzieć, że OLAP jako sam silnik zapytań nam nie wystarczył.
4. Architektura 3.0 Góra lodowa + Trino
Witamy w architekturze Footprint Analytics 3.0, czyli kompletnej przebudowie architektury bazowej. Przeprojektowaliśmy całą architekturę od podstaw, aby rozdzielić przechowywanie, obliczanie i wyszukiwanie danych na trzy różne części. Wykorzystując lekcje z dwóch wcześniejszych architektur Footprint Analytics i ucząc się z doświadczeń innych udanych projektów big data, takich jak Uber, Netflix i Databricks.
4.1. Wprowadzenie do jeziora danych
Najpierw zwróciliśmy uwagę na jezioro danych, czyli nowy typ przechowywania danych zarówno strukturalnych, jak i nieustrukturyzowanych. Jezioro danych jest idealne do przechowywania danych on-chain, ponieważ formaty danych on-chain są bardzo zróżnicowane – od nieustrukturyzowanych danych surowych po ustrukturyzowane dane abstrakcyjne, z których Footprint Analytics jest dobrze znany. Spodziewaliśmy się, że wykorzystamy jezioro danych do rozwiązania problemu przechowywania danych, a najlepiej byłoby, gdyby wspierało ono również główne silniki obliczeniowe, takie jak Spark i Flink, tak aby nie było bólem integrowanie się z różnymi typami silników przetwarzania w miarę rozwoju Footprint Analytics.
Iceberg bardzo dobrze integruje się ze Sparkiem, Flink, Trino i innymi silnikami obliczeniowymi, a my możemy wybrać najbardziej odpowiednie obliczenia dla każdej z naszych metryk. Na przykład:
- Dla tych, które wymagają skomplikowanej logiki obliczeniowej, wyborem będzie Spark.
- Flinki do obliczeń w czasie rzeczywistym.
- Dla prostych zadań ETL, które można wykonać za pomocą SQL, używamy Trino.
4.2. Silnik zapytań
Po rozwiązaniu przez Iceberg problemów składowania i obliczania musieliśmy zastanowić się nad wyborem silnika zapytań. Nie ma zbyt wielu dostępnych opcji. Alternatywy, które rozważaliśmy, to
- Trino: SQL Query Engine (silnik zapytań)
- Presto: Silnik zapytań SQL
- Kyuubi: Bezserwerowy Spark SQL
Najważniejszą rzeczą, którą rozważaliśmy przed zagłębieniem się w temat, było to, że przyszły silnik zapytań musiał być zgodny z naszą obecną architekturą.
- Wsparcie Bigquery jako źródła danych
- Obsługa DBT, na którym polegamy przy tworzeniu wielu metryk
- Wspieranie metabaz danych narzędzi BI
Bazując na powyższym, wybraliśmy Trino, które ma bardzo dobre wsparcie dla Iceberg, a zespół był tak responsywny, że zgłosiliśmy błąd, który został naprawiony następnego dnia i wydany do najnowszej wersji w następnym tygodniu. To był najlepszy wybór dla zespołu Footprint, który również wymaga wysokiej responsywności wdrożenia.
4.3. Testowanie wydajności
Gdy już zdecydowaliśmy się na nasz kierunek, wykonaliśmy test wydajnościowy na kombinacji Trino + Iceberg, aby sprawdzić, czy może ona spełnić nasze potrzeby i ku naszemu zaskoczeniu, zapytania były niesamowicie szybkie.
Wiedząc, że Presto + Hive był najgorszym komparatorem od lat w całym szumie OLAP, kombinacja Trino + Iceberg całkowicie rozwaliła nasze umysły.
Oto wyniki naszych testów.
przypadek 1: dołączenie do dużego zbioru danych
800 GB tabela1 łączy inną 50 GB tabelę2 i wykonuje złożone obliczenia biznesowe.
przypadek 2: użycie dużej pojedynczej tabeli do wykonania zapytania distinct
Test sql: select distinct(adres) from the table group by day

Kombinacja Trino+Iceberg jest około 3 razy szybsza od Dorisa w tej samej konfiguracji.
Do tego dochodzi jeszcze jedna niespodzianka, ponieważ Iceberg może korzystać z formatów danych takich jak Parquet, ORC itp, które będą kompresować i przechowywać dane. Przechowywanie tabel w Iceberg zajmuje tylko około 1/5 miejsca innych hurtowni danych Rozmiar przechowywania tej samej tabeli w trzech bazach danych jest następujący:
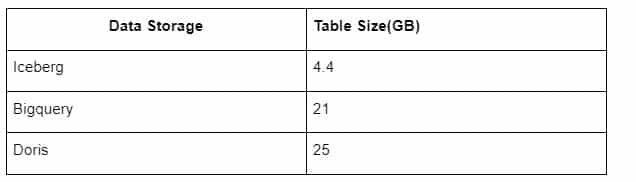
Uwaga: Powyższe testy są przykładami, z którymi zetknęliśmy się w rzeczywistej produkcji i mają charakter wyłącznie referencyjny.
4.4. Efekt aktualizacji
Raporty z testów wydajnościowych dały nam wystarczającą wydajność, że zakończenie migracji zajęło naszemu zespołowi około 2 miesięcy, a to jest diagram naszej architektury po aktualizacji.
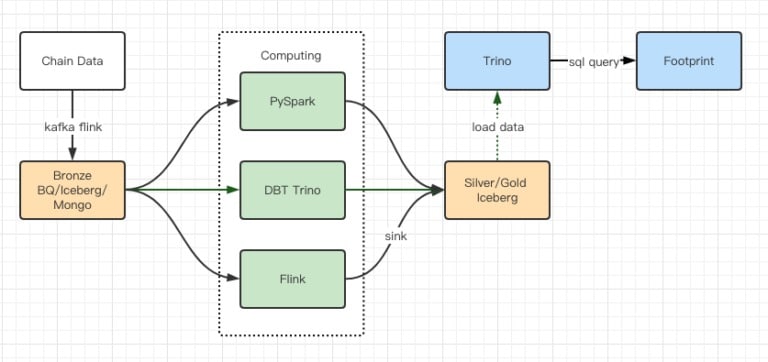
- Wielość silników komputerowych odpowiada naszym różnym potrzebom.
- Trino obsługuje DBT i może bezpośrednio odpytywać Iceberg, więc nie musimy już zajmować się synchronizacją danych.
- Niesamowita wydajność Trino + Iceberg pozwala nam otworzyć wszystkie dane z brązu (raw data) dla naszych użytkowników.
5. Podsumowanie
Od momentu uruchomienia w sierpniu 2021 r. zespół Footprint Analytics ukończył trzy aktualizacje architektury w mniej niż półtora roku, dzięki silnemu pragnieniu i determinacji, aby przynieść korzyści z najlepszej technologii bazodanowej swoim użytkownikom kryptowalut i solidnej egzekucji w zakresie wdrażania i modernizacji podstawowej infrastruktury i architektury.
Aktualizacja architektury Footprint Analytics 3.0 kupiła nowe doświadczenie dla swoich użytkowników, pozwalając użytkownikom z różnych środowisk uzyskać wgląd w bardziej zróżnicowane wykorzystanie i aplikacje:
- Zbudowany z narzędziem Metabase BI, Footprint ułatwia analitykom dostęp do zdekodowanych danych on-chain, eksplorację z pełną swobodą wyboru narzędzi (no-code lub hardcord), przeszukiwanie całej historii i krzyżowe badanie zestawów danych, aby uzyskać wgląd w krótkim czasie.
Integracja zarówno danych on-chain, jak i off-chain do analizy przez web2 + web3; - Budując/zapytując o metryki na szczycie abstrakcji biznesowej Footprinta, analitycy lub programiści oszczędzają czas na 80% powtarzalnych prac związanych z przetwarzaniem danych i skupiają się na istotnych metrykach, badaniach i rozwiązaniach produktowych opartych na ich działalności.
- Bezproblemowe doświadczenie z Footprint Web do wywołań REST API, wszystko w oparciu o SQL
Alerty i powiadomienia w czasie rzeczywistym o kluczowych sygnałach wspierających decyzje inwestycyjne
Real-time alerts and actionable notifications on key signals to support investment decisions