
1. Le défi d’une pile de données moderne pour blockchain
Il y a plusieurs défis qu’une startup moderne d’indexation de blockchain peut rencontrer, notamment :
- Massive quantité de données. À mesure que la quantité de données sur la blockchain augmente, l’index de données devra se mettre à l’échelle pour gérer la charge accrue et fournir un accès efficace aux données. Par conséquent, cela entraîne des coûts de stockage plus élevés, un calcul lent des métriques et une charge accrue sur le serveur de la base de données.
- Pipeline de traitement des données complexe. La technologie blockchain est complexe, et la construction d’un index de données complet et fiable nécessite une compréhension approfondie des structures de données et des algorithmes sous-jacents. La diversité des implémentations de blockchain en hérite. Pour donner des exemples précis, les NFT sur Ethereum sont généralement créés au sein de smart contracts suivant les formats ERC721 et ERC1155. En revanche, leur mise en œuvre sur Polkadot, par exemple, est généralement construite directement dans le runtime de la blockchain. Ceux-ci doivent être considérés comme des NFTs et doivent être enregistrés comme tels.
- Capacités d’intégration. Pour fournir une valeur maximale aux utilisateurs, une solution d’indexation de blockchain peut avoir besoin d’intégrer son index de données avec d’autres systèmes, tels que des plateformes analytiques ou des API. Cela représente un défi et nécessite un effort important placé dans la conception de l’architecture.
A mesure que la technologie blockchain s’est répandue, la quantité de données stockées sur la blockchain a augmenté. Cela s’explique par le fait que davantage de personnes utilisent cette technologie et que chaque transaction ajoute de nouvelles données à la blockchain. En outre, la technologie blockchain a évolué, passant de simples applications de transfert d’argent, telles que celles impliquant l’utilisation du bitcoin, à des applications plus complexes impliquant la mise en œuvre d’une logique commerciale dans des contrats intelligents. Ces contrats intelligents peuvent générer de grandes quantités de données, ce qui contribue à accroître la complexité et la taille de la blockchain. Au fil du temps, cela a conduit à une blockchain plus grande et plus complexe.
Dans cet article, nous examinons l’évolution de l’architecture technologique de Footprint Analytics par étapes comme une étude de cas pour explorer comment la pile technologique Iceberg-Trino relève les défis des données sur la chaîne.
Footprint Analytics a indexé environ 22 données de blockchain publiques, et 17 places de marché NFT, 1900 projets GameFi, et plus de 100 000 collections NFT dans une couche de données d’abstraction sémantique. Il s’agit de la solution d’entrepôt de données blockchain la plus complète au monde.
Indépendamment des données blockchain, qui comprennent plus de 20 milliards de lignes d’enregistrements de transactions financières, que les analystes de données interrogent fréquemment. il est différent des journaux d’ingestion dans les entrepôts de données traditionnels.
Nous avons connu 3 mises à niveau majeures au cours des derniers mois pour répondre aux exigences croissantes de l’entreprise:
2.  ; Architecture 1.0 Bigquery
Au début de Footprint Analytics, nous avons utilisé Google Bigquery comme moteur de stockage et d’interrogation ; Bigquery est un excellent produit. Il est incroyablement rapide, facile à utiliser et offre une puissance arithmétique dynamique ainsi qu’une syntaxe UDF flexible qui nous aide à accomplir rapidement notre travail.
Cependant, Bigquery présente également plusieurs problèmes.
- Les données ne sont pas compressées, ce qui entraîne des coûts élevés, notamment lors du stockage des données brutes de plus de 22 blockchains de Footprint Analytics.
- Concurrence insuffisante : Bigquery ne prend en charge que 100 requêtes simultanées, ce qui est inadapté aux scénarios de forte concurrence pour Footprint Analytics lorsqu’il s’agit de servir de nombreux analystes et utilisateurs.
- La connexion avec Google Bigquery, qui est un produit à code fermé。
So we decided to explore other alternative architectures.
3.  ; Architecture 2.0 OLAP
Nous étions très intéressés par certains produits OLAP qui étaient devenus très populaires. L’avantage le plus attrayant d’OLAP est son temps de réponse aux requêtes, qui prend généralement moins de quelques secondes pour renvoyer les résultats des requêtes pour des quantités massives de données, et il peut également supporter des milliers de requêtes simultanées.
Nous avons choisi l’une des meilleures bases de données OLAP, Doris, pour l’essayer. Ce moteur fonctionne bien. Cependant, à un moment donné, nous avons rencontré d’autres problèmes:
- Les types de données tels que Array ou JSON ne sont pas encore supportés (Nov, 2022). Les tableaux sont un type de données courant dans certaines blockchains. Par exemple, le champ topic dans les logs evm. L’impossibilité de calculer sur Array affecte directement notre capacité à calculer de nombreuses mesures commerciales.
- Prise en charge limitée de DBT et des instructions de fusion. Il s’agit d’exigences courantes pour les ingénieurs de données dans les scénarios ETL/ELT où nous devons mettre à jour des données nouvellement indexées.
Ceci étant dit, nous ne pouvions pas utiliser Doris pour l’ensemble de notre pipeline de données en production, nous avons donc essayé d’utiliser Doris comme base de données OLAP pour résoudre une partie de notre problème dans le pipeline de production de données, en agissant comme un moteur de requête et en fournissant des capacités de requête rapides et hautement concurrentes.
Malheureusement, nous n’avons pas pu remplacer Bigquery par Doris, et nous avons donc dû synchroniser périodiquement les données de Bigquery vers Doris en l’utilisant comme moteur d’interrogation. Ce processus de synchronisation présentait plusieurs problèmes, dont l’un était que les écritures de mise à jour s’empilaient rapidement lorsque le moteur OLAP était occupé à servir des requêtes aux clients frontaux. Par conséquent, la vitesse du processus d’écriture était affectée, et la synchronisation prenait beaucoup plus de temps et devenait parfois même impossible à terminer.
Nous avons réalisé que l’OLAP pouvait résoudre plusieurs problèmes auxquels nous sommes confrontés et ne pouvait pas devenir la solution clé en main de Footprint Analytics, en particulier pour le pipeline de traitement des données. Notre problème est plus grand et plus complexe, et nous pourrions dire que l’OLAP en tant que moteur de requête seul n’était pas suffisant pour nous.
4.
4.  ; Architecture 3.0 Iceberg + Trino
Welcome4.  ;.
Bienvenue à l’architecture 3.0 de Footprint Analytics, une refonte complète de l’architecture sous-jacente. Nous avons repensé toute l’architecture depuis le début pour séparer le stockage, le calcul et l’interrogation des données en trois parties différentes. Nous avons tiré les leçons des deux architectures précédentes de Footprint Analytics et de l’expérience d’autres projets big data réussis comme Uber, Netflix et Databricks.
4.1. Introduction du lac de données
Nous avons d’abord porté notre attention sur le lac de données, un nouveau type de stockage de données pour les données structurées et non structurées. Le lac de données est parfait pour le stockage des données sur la chaîne, car les formats des données sur la chaîne vont des données brutes non structurées aux données d’abstraction structurées pour lesquelles Footprint Analytics est bien connu. Nous espérions utiliser le lac de données pour résoudre le problème du stockage des données et, idéalement, il devrait également prendre en charge les moteurs de calcul courants tels que Spark et Flink, afin qu’il ne soit pas difficile d’intégrer différents types de moteurs de traitement à mesure que Footprint Analytics évolue.
Iceberg s’intègre très bien avec Spark, Flink, Trino et d’autres moteurs de calcul, et nous pouvons choisir le calcul le plus approprié pour chacune de nos métriques. Par exemple:
- Pour ceux qui nécessitent une logique de calcul complexe, Spark sera le choix.
- Pour le calcul en temps réel.
- Pour les tâches ETL simples qui peuvent être effectuées en utilisant SQL, nous utilisons Trino.
4.2. Moteur de requêtes
Avec Iceberg qui résout les problèmes de stockage et de calcul, nous avons dû réfléchir au choix d’un moteur de requêtes. Il n’y a pas beaucoup d’options disponibles. Les alternatives que nous avons envisagées sont les suivantes :
- Trino : Moteur de requête SQL
- Presto : Moteur de requête SQL
- Kyuubi : Spark SQL sans serveur
La chose la plus importante que nous avons considérée avant d’aller plus loin était que le futur moteur de requête devait être compatible avec notre architecture actuelle
- Pour supporter Bigquery comme source de données
- Pour supporter DBT, sur lequel nous nous appuyons pour produire de nombreuses métriques.
- Pour prendre en charge la métabase de l’outil de BI
Sur la base de ce qui précède, nous avons choisi Trino, qui offre un très bon support pour Iceberg et dont l’équipe a été si réactive que nous avons signalé un bogue, qui a été corrigé le jour suivant et mis à disposition dans la dernière version la semaine suivante. C’était le meilleur choix pour l’équipe de Footprint, qui a également besoin d’une grande réactivité dans la mise en œuvre.
4.3. Tests de performance
Une fois que nous avons décidé de notre orientation, nous avons effectué un test de performance sur la combinaison Trino + Iceberg pour voir si elle pouvait répondre à nos besoins et à notre grande surprise, les requêtes étaient incroyablement rapides.
Sachant que Presto + Hive a été le pire comparateur pendant des années dans tout le battage OLAP, la combinaison de Trino + Iceberg nous a complètement époustouflés.
Voici les résultats de nos tests.
cas 1 : joindre un grand ensemble de données
Une table 1 de 800 Go rejoint une autre table 2 de 50 Go et effectue des calculs commerciaux complexes.
cas2 : utiliser une grande table unique pour effectuer une requête distincte
Test sql : select distinct(address) from the table group by day

La combinaison Trino+Iceberg est environ 3 fois plus rapide que Doris dans la même configuration.
En outre, il y a une autre surprise, car Iceberg peut utiliser des formats de données tels que Parquet, ORC, etc. Le stockage des tables d’Iceberg ne prend qu’environ 1/5 de l’espace des autres entrepôts de données La taille de stockage d’une même table dans les trois bases de données est la suivante :
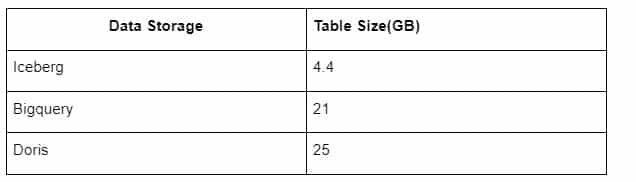
Note : Les tests ci-dessus sont des exemples que nous avons rencontrés en production réelle et ne sont donnés qu’à titre indicatif.
4.4. Effet de mise à niveau
Les rapports des tests de performance nous ont donné suffisamment de performance pour que notre équipe mette environ 2 mois à effectuer la migration. Voici un diagramme de notre architecture après la mise à niveau.
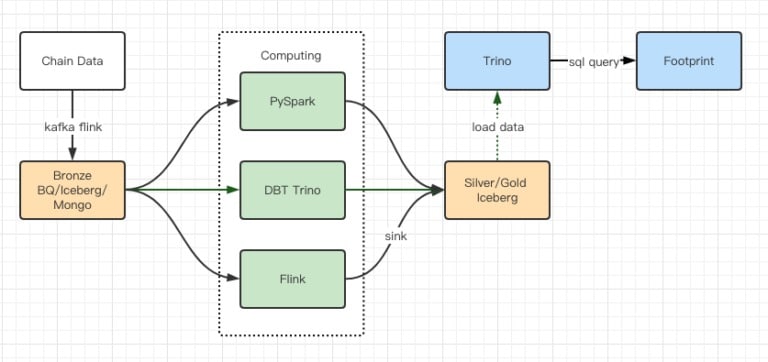
- Multiples moteurs d’ordinateurs répondant à nos différents besoins.
- Trino supporte DBT, et peut interroger directement Iceberg, ce qui nous évite de devoir nous occuper de la synchronisation des données.
- Les performances étonnantes de Trino + Iceberg nous permettent d’ouvrir toutes les données de Bronze (données brutes) à nos utilisateurs.
5. Résumé
Depuis son lancement en août 2021, l’équipe de Footprint Analytics a réalisé trois mises à niveau architecturales en moins d’un an et demi, grâce à sa forte volonté et sa détermination à apporter les avantages de la meilleure technologie de base de données à ses utilisateurs de crypto-monnaies et à une exécution solide de la mise en œuvre et de la mise à niveau de son infrastructure et de son architecture sous-jacentes.
La mise à niveau de l’architecture de Footprint Analytics 3.0 a apporté une nouvelle expérience à ses utilisateurs, permettant à des utilisateurs d’horizons différents d’obtenir des informations dans des utilisations et des applications plus variées :
- Bâti avec l’outil BI Metabase, Footprint permet aux analystes d’accéder aux données décodées de la chaîne, d’explorer en toute liberté les outils (sans code ou en dur), d’interroger l’historique complet et de croiser les ensembles de données pour obtenir des informations en un rien de temps.
- Intégrez les données on-chain et off-chain à l’analyse  ; à travers  ; web2 + web3 ;
- En construisant / interrogeant des métriques au dessus de l’abstraction métier de Footprint, les analystes ou les développeurs gagnent du temps sur 80% du travail répétitif de traitement des données et se concentrent sur des métriques significatives, des recherches et des solutions produits basées sur leur activité.
- Expérience transparente depuis Footprint Web jusqu’aux appels REST API, le tout basé sur SQL
Alertes en temps réel et notifications exploitables sur les signaux clés pour soutenir les décisions d’investissement