
OpenAI wypuściło nowego bota indeksującego sieć, GPTBot, aby rozszerzyć swój zbiór danych do szkolenia następnej generacji systemów sztucznej inteligencji – a następna iteracja najwyraźniej ma oficjalną nazwę. Firma zastrzegła termin „GPT-5”, sugerując nadchodzącą premierę, jednocześnie dając wydawcom internetowym wskazówki, jak trzymać ich treści z dala od ogromnego korpusu.
Według OpenAI, crawler będzie zbierał publicznie dostępne dane ze stron internetowych, unikając jednocześnie treści płatnych, wrażliwych i zabronionych. Podobnie jak w przypadku innych wyszukiwarek, takich jak Google, Bing i Yandex, system jest jednak domyślnie wyłączony – GPTBot zakłada, że dostępne informacje są uczciwą grą. Aby uniemożliwić indeksowanie strony przez OpenAI, jej właściciel musi dodać regułę „disallow” do standardowego pliku na serwerze.
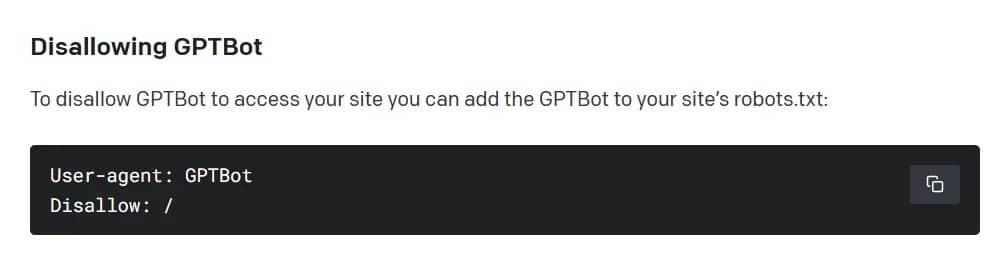
Jak zablokować GPTBot OpenAI. Image: OpenAI
OpenAI twierdzi również, że GPTBot będzie zapobiegawczo skanować zeskrobane dane w celu usunięcia informacji umożliwiających identyfikację osoby (PII) i tekstu, który narusza jej zasady.
Według niektórych etyków technologicznych podejście opt-out nadal budzi jednak wątpliwości dotyczące zgody.
W serwisie Hacker News niektórzy użytkownicy usprawiedliwiali posunięcie OpenAI, mówiąc, że musi zebrać wszystko, co może, jeśli ludzie chcą mieć w przyszłości zdolne narzędzie do generowania sztucznej inteligencji. „Nadal potrzebują aktualnych danych, w przeciwnym razie ich modele GPT utkną na zawsze we wrześniu 2021 r.” – powiedział jeden z użytkowników. Inny, bardziej świadomy prywatności użytkownik argumentował, że „OpenAI nawet nie cytuje z umiarem. Tworzy dzieło pochodne bez cytowania, tym samym zaciemniając je”.
Wydanie GPTBot jest następstwem niedawnej krytyki OpenAI, która wcześniej skrobała dane bez pozwolenia w celu trenowania dużych modeli językowych (LLM), takich jak ChatGPT. Aby rozwiać te obawy, firma zaktualizowała swoją politykę prywatności w kwietniu.
Tymczasem niedawne zgłoszenie znaku towarowego dla GPT-5 wydaje się potwierdzać, że OpenAI trenuje swój kolejny model do przyszłej premiery. Nowy system najprawdopodobniej obejmowałby skrobanie stron internetowych na dużą skalę w celu aktualizacji i rozszerzenia danych szkoleniowych.
Może to oznaczać odejście od wczesnego nacisku OpenAI na przejrzystość i bezpieczeństwo sztucznej inteligencji, ale nie jest to zaskakujące, biorąc pod uwagę, że ChatGPT jest najczęściej używanym LLM na świecie, pomimo coraz bardziej zatłoczonego i potężnego rynku. Gwiezdny produkt OpenAI – i każdego LLM – jest tak dobry, jak jakość danych wykorzystywanych do jego szkolenia.
OpenAI potrzebuje więcej i nowszych danych, i potrzebuje ich dużo.
Z drugiej strony istnieje LLM typu open-source, zmontowany przez giganta mediów społecznościowych Meta. Ten technologiczny gigant zaoferował swój model za darmo, o ile nie jesteś konkurentem ani zbyt dużą firmą. Meta nie ujawniła, jakie zbiory danych wykorzystała do trenowania swojego modelu i jakie informacje zebrała. Podejście to umożliwia jednak użytkownikom dostrojenie modelu przy użyciu własnych zestawów danych.
Podczas gdy OpenAI polega na wszystkich swoich indeksowanych danych, aby trenować swoje modele i budować dochodowy ekosystem wokół swoich narzędzi AI, Meta stara się zbudować dochodowy biznes wokół swoich danych. W związku z tym Meta nie tylko wykorzystuje je do tworzenia lepszych modeli, ale także udostępnia je stronom trzecim, aby mogły z nich korzystać.
„Nie sprzedajemy informacji o użytkownikach. Zamiast tego, w oparciu o posiadane przez nas informacje, reklamodawcy i inni partnerzy płacą nam za wyświetlanie spersonalizowanych reklam” – wyjaśnia Meta. Zgodnie ze standardowymi informacjami o prywatności Meta, niektóre z danych gromadzonych przez firmę obejmują między innymi zakupy, historię przeglądarki, identyfikatory, informacje finansowe, kontakty i nieujawnione wrażliwe informacje.
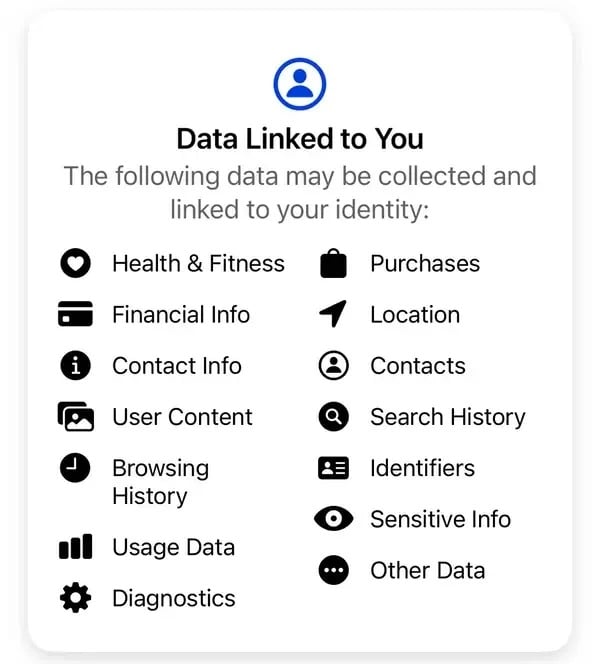
Niektóre dane zebrane przez Metę od użytkowników jej aplikacji Thread. Image: Meta
ChatGPT przyciąga obecnie ponad 1,5 miliarda aktywnych użytkowników miesięcznie. A inwestycja Microsoftu w OpenAI o wartości 10 miliardów dolarów wydaje się trafna, ponieważ integracja ChatGPT zwiększyła możliwości Bing.
Na razie OpenAI jest liderem w gorącej przestrzeni sztucznej inteligencji, a giganci technologiczni ścigają się, by nadrobić zaległości. Nowy crawler internetowy firmy może jeszcze bardziej zwiększyć możliwości jej modeli. Jednak rozszerzenie gromadzenia danych internetowych rodzi również pytania etyczne dotyczące praw autorskich i zgody.
W miarę jak systemy sztucznej inteligencji stają się coraz bardziej wyrafinowane, równoważenie przejrzystości, etyki i możliwości pozostanie złożonym aktem równoważenia.