
In einer aufkeimenden Technologieszene, die von Giganten wie OpenAI und Google dominiert wird, könnte NExT-GPT – ein Open-Source-Modell für multimodale KI (Large Language Model, LLM) – das Zeug dazu haben, in der ersten Liga mitzuspielen.
ChatGPT hat die Welt mit seiner Fähigkeit, natürlichsprachliche Anfragen zu verstehen und menschenähnliche Antworten zu generieren, im Sturm erobert. Da sich die KI jedoch in rasantem Tempo weiterentwickelt, haben die Menschen nach mehr Leistung verlangt. Die Ära des reinen Textes ist bereits vorbei, und multimodale LLMs sind im Kommen.
NExT-GPT, das in Zusammenarbeit zwischen der National University of Singapore (NUS) und der Tsinghua University entwickelt wurde, kann Kombinationen aus Text, Bildern, Audio und Video verarbeiten und erzeugen. Dies ermöglicht natürlichere Interaktionen als reine Textmodelle wie das grundlegende ChatGPT-Tool.
Das Team, das es entwickelt hat, preist NExT-GPT als ein „Any-to-Any“-System an, d. h. es kann Eingaben in jeder Modalität annehmen und Antworten in der entsprechenden Form liefern.
Das Potenzial für rasche Fortschritte ist enorm. Da es sich um ein Open-Source-Modell handelt, kann NExT-GPT von den Nutzern an ihre spezifischen Bedürfnisse angepasst werden. Dies könnte zu dramatischen Verbesserungen gegenüber dem Original führen, ähnlich wie es bei Stable Diffusion gegenüber der ersten Version der Fall war. Durch die Demokratisierung des Zugangs können die Schöpfer die Technologie so gestalten, dass sie maximale Wirkung entfaltet.
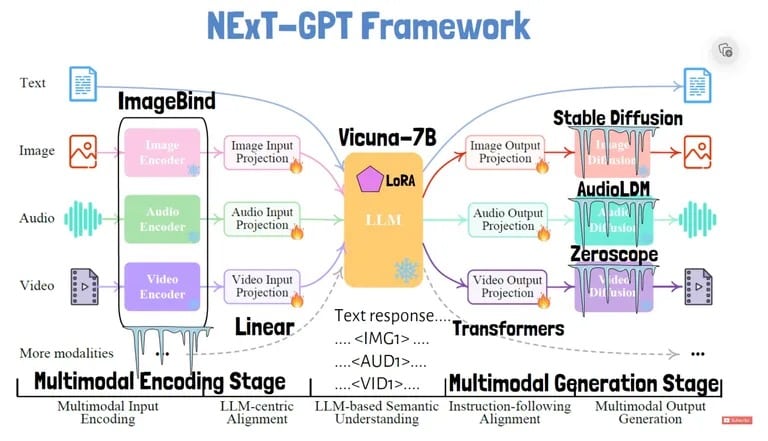
Wie funktioniert also NExT-GPT? Wie im Forschungspapier zu diesem Modell erläutert, verfügt das System über separate Module, die Eingaben wie Bilder und Audio in textähnliche Darstellungen kodieren, die das zentrale Sprachmodell verarbeiten kann.
Die Forscher führten eine Technik ein, die als „modality-switching instruction tuning“ bezeichnet wird, um die Fähigkeiten des Systems zum modalitätsübergreifenden Denken zu verbessern, d. h. seine Fähigkeit, verschiedene Arten von Eingaben als eine kohärente Struktur zu verarbeiten. Durch dieses Tuning lernt das Modell, während einer Konversation nahtlos zwischen den Modalitäten zu wechseln.
Um Eingaben zu verarbeiten, verwendet NExT-GPT eindeutige Token, z. B. für Bilder, Audio und Video. Jeder Eingabetyp wird in Einbettungen umgewandelt, die das Sprachmodell versteht. Das Sprachmodell kann dann einen Antworttext ausgeben, sowie spezielle Signal-Token, um die Generierung in anderen Modalitäten auszulösen.
Ein Token in der Antwort weist zum Beispiel den Videodecoder an, eine entsprechende Videoausgabe zu erzeugen. Die Verwendung von maßgeschneiderten Token für jede Eingabe- und Ausgabemodalität ermöglicht eine flexible Konvertierung von beliebig nach beliebig.
Das Sprachmodell gibt dann spezielle Token aus, um zu signalisieren, wenn Nicht-Text-Ausgaben wie Bilder erzeugt werden sollen. Verschiedene Decoder erzeugen dann die Ausgaben für jede Modalität: Stable Diffusion als Bilddecoder, AudioLDM als Audiodecoder und Zeroscope als Videodecoder. Außerdem werden Vicuna als Basis-LLM und ImageBind für die Kodierung der Eingaben verwendet.
NExT-GPT ist im Wesentlichen ein Modell, das die Leistung verschiedener KIs zu einer Art All-in-One-Super-KI kombiniert.
Screenshot mit freundlicher Genehmigung von: AI Papers Academy via YouTube
NExT-GPT erreicht diese flexible „any-to-any“-Umwandlung, während nur 1% der Gesamtparameter trainiert wird. Der Rest der Parameter sind eingefrorene, vortrainierte Module, die von den Forschern als sehr effizientes Design gelobt werden.
Es wurde eine Demoseite eingerichtet, auf der NExT-GPT getestet werden kann, die jedoch nur sporadisch verfügbar ist.
Angesichts der Tatsache, dass Tech-Giganten wie Google und OpenAI ihre eigenen multimodalen KI-Produkte auf den Markt bringen, stellt NExT-GPT eine Open-Source-Alternative dar, auf die Entwickler aufbauen können. Multimodalität ist der Schlüssel zu natürlichen Interaktionen. Indem sie NExT-GPT als Open Source zur Verfügung stellen, bieten die Forscher der Gemeinschaft ein Sprungbrett, um die KI auf die nächste Stufe zu heben.