
在由 OpenAI 和谷歌等巨头主导的蓬勃发展的技术领域,NExT-GPT–一种开源的多模态人工智能大语言模型(LLM)–可能具备在大联盟中竞争的实力。
ChatGPT 凭借其理解自然语言查询并生成类人回复的能力风靡全球。但是,随着人工智能以迅雷不及掩耳之势不断进步,人们对其提出了更高的要求。纯文本时代已经过去,多模态龙8国际娱乐城正在到来。
由新加坡国立大学(NUS)和清华大学合作开发的NExT-GPT可以处理和生成文本、图像、音频和视频的组合。与基本的 ChatGPT 工具等纯文本模型相比,它能实现更自然的交互。
创建 NExT-GPT 的团队称 NExT-GPT 是一个 “任意对任意 “的系统,这意味着它可以接受任何模式的输入,并以适当的形式作出回应。
快速发展的潜力巨大。作为一个开源模型,用户可以对 NExT-GPT 进行修改,以满足他们的特定需求。这可能会带来超越原版的巨大改进,就像 Stable Diffusion 最初发布时的情况一样。访问的民主化可以让创造者塑造技术,使其发挥最大作用。
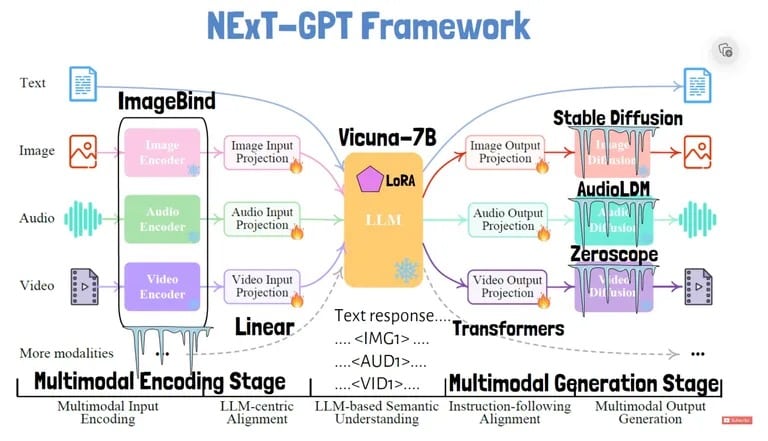
那么 NExT-GPT 是如何工作的呢?正如该模型的研究论文所解释的那样,该系统拥有独立的模块,用于将图像和音频等输入编码为核心语言模型可以处理的文本表述。
研究人员引入了一种名为 “模态切换指令调整 “的技术,以提高跨模态推理能力–将不同类型的输入作为一个连贯结构进行处理的能力。这种调整能让模型在对话过程中无缝切换模式。
为了处理输入,NExT-GPT 使用独特的标记,如图像、音频和视频。每种输入类型都会被转换成语言模型可以理解的嵌入。然后,语言模型可以输出响应文本以及特殊信号标记,以触发其他模式的生成。
例如,响应中的标记会告诉视频解码器生成相应的视频输出。该系统为每种输入和输出模式量身定制了标记,从而实现了灵活的任意转换。
然后,语言模型会输出特殊标记,提示何时应生成图像等非文本输出。然后由不同的解码器为每种模式创建输出: 稳定扩散作为图像解码器,AudioLDM 作为音频解码器,Zeroscope 作为视频解码器。它还使用 Vicuna 作为基础 LLM,并使用 ImageBind 对输入进行编码。
NExT-GPT 本质上是一种模型,它将不同人工智能的力量结合在一起,成为一种一体化的超级人工智能。
Screenshot courtesy of: AI Papers Academy via YouTube
NExT-GPT 实现了这种灵活的 “任意到任意 “转换,同时只训练了总参数的 1%。其余的参数都是冻结的预训练模块,这种高效的设计赢得了研究人员的一致好评。
为了让人们测试 NExT-GPT,研究人员建立了一个演示网站,但其可用性时断时续。
随着谷歌和 OpenAI 等科技巨头纷纷推出自己的多模态人工智能产品,NExT-GPT 代表了一种开放源代码的替代方案,供创造者们在此基础上进行开发。多模态是自然交互的关键。通过开源 NExT-GPT,研究人员为社区提供了一个跳板,让人工智能更上一层楼。