
Na rozvíjející se technologické scéně, které dominují giganti jako OpenAI a Google, má NExT-GPT – open source multimodální velký jazykový model (LLM) – možná na to, aby mohl konkurovat v první lize.
ChatGPT uchvátil svět svou schopností porozumět dotazům v přirozeném jazyce a generovat odpovědi podobné lidským. Ale protože umělá inteligence se stále vyvíjí rychlostí blesku, lidé požadují větší výkon. Éra čistě textových služeb již skončila a nastupují multimodální LLM.
Systém NExT-GPT, vyvinutý ve spolupráci Národní univerzity v Singapuru (NUS) a univerzity Tsinghua, dokáže zpracovávat a generovat kombinace textu, obrázků, zvuku a videa. To umožňuje přirozenější interakce než modely využívající pouze text, jako je základní nástroj ChatGPT.
Tým, který jej vytvořil, představuje NExT-GPT jako systém „any-to-any“, což znamená, že může přijímat vstupy v jakékoli modalitě a poskytovat odpovědi v odpovídající formě.
Potenciál rychlého pokroku je obrovský. Protože se jedná o model s otevřeným zdrojovým kódem, mohou si uživatelé NExT-GPT upravit podle svých specifických potřeb. To by mohlo vést k dramatickému vylepšení oproti původnímu stavu, podobně jako se to stalo se stabilní difuzí oproti jejímu prvotnímu vydání. Demokratizace přístupu umožňuje tvůrcům utvářet technologii tak, aby měla co největší dopad.
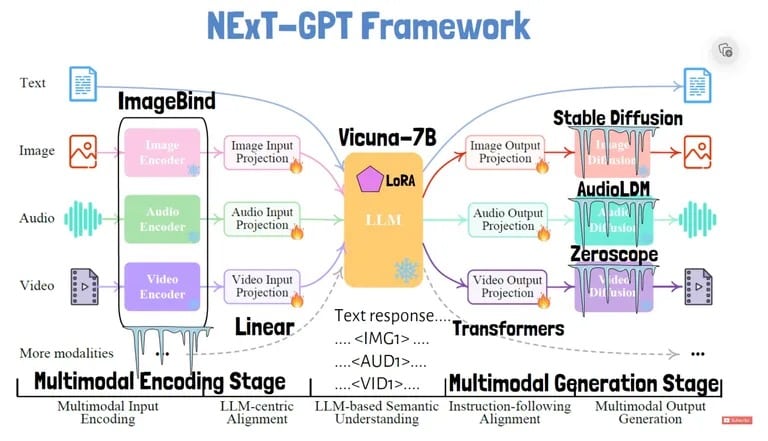
Jak tedy NExT-GPT funguje? Jak je vysvětleno ve výzkumném dokumentu modelu, systém má samostatné moduly pro kódování vstupů, jako jsou obrázky a zvuky, do reprezentací podobných textu, které může zpracovat hlavní jazykový model.
Výzkumníci zavedli techniku zvanou „modality-switching instruction tuning“, aby zlepšili schopnosti cross-modal reasoning – jeho schopnost zpracovávat různé typy vstupů jako jednu souvislou strukturu. Toto ladění učí model plynule přepínat mezi modalitami během konverzace.
Ke zpracování vstupů používá NExT-GPT jedinečné tokeny, například pro obrázky, pro zvuk a pro video. Každý typ vstupu se převede na embeddingy, kterým jazykový model rozumí. Jazykový model pak může vypisovat text odpovědi a také speciální signální tokeny pro spuštění generování v jiných modalitách.
Token v odpovědi například říká dekodéru videa, aby vytvořil odpovídající výstup videa. Použití tokenů na míru pro každou vstupní a výstupní modalitu systému umožňuje flexibilní převod z libovolného na libovolný.
Jazykový model pak vypisuje speciální tokeny, které signalizují, kdy mají být generovány netextové výstupy, například obrázky. Výstupy pro každou modalitu pak vytvářejí různé dekodéry: Stable Diffusion jako dekodér obrazu, AudioLDM jako dekodér zvuku a Zeroscope jako dekodér videa. Dále používá Vicuna jako základní LLM a ImageBind pro kódování vstupů.
NExT-GPT je v podstatě model, který kombinuje sílu různých UI a stává se jakousi superUI typu vše v jednom.
Snímek obrazovky s laskavým svolením: AI Papers Academy via YouTube
NExT-GPT dosahuje tohoto flexibilního převodu „z libovolného na libovolný“, přičemž trénuje pouze 1 % celkových parametrů. Zbytek parametrů tvoří zmrazené, předem natrénované moduly – za to si od výzkumníků vysloužil pochvalu jako velmi efektivní návrh.
Byla zřízena ukázková stránka, která umožňuje zájemcům testovat NExT-GPT, ale její dostupnost je nepravidelná.
Vzhledem k tomu, že technologičtí giganti jako Google a OpenAI uvádějí na trh vlastní multimodální produkty umělé inteligence, představuje NExT-GPT alternativu s otevřeným zdrojovým kódem, na které mohou tvůrci stavět. Multimodalita je pro přirozené interakce klíčová. A díky otevřenému zdrojovému kódu NExT-GPT poskytují výzkumníci komunitě odrazový můstek, aby mohla AI posunout na další úroveň.