
OpenAIやGoogleのような巨大企業が支配する急成長中のテクノロジーシーンにおいて、NExT-GPTはオープンソースのマルチモーダルAI大規模言語モデル(LLM)であり、大リーグで競争するために必要なものを持っているかもしれない。
ChatGPTは、自然言語のクエリを理解し、人間のような応答を生成する能力で一世を風靡した。しかし、AIが電光石火のスピードで進歩し続ける中、人々はより大きな力を求めている。純粋なテキストの時代はすでに終わりを告げ、マルチモーダルなLLMが登場しつつある。
シンガポール国立大学(NUS)と清華大学の共同研究によって開発されたNExT-GPTは、テキスト、画像、音声、動画の組み合わせを処理し、生成することができる。これにより、基本的なChatGPTツールのようなテキストのみのモデルよりも自然なインタラクションが可能になる。
NExT-GPTを開発したチームは、NExT-GPTを “any-to-any “システムとして売り込んでいる。
急速な進歩の可能性は非常に大きい。オープンソースモデルであるNExT-GPTは、ユーザーがそれぞれのニーズに合わせて変更することができる。これは、Stable Diffusionの初期リリース時に起こったような、オリジナルを超える劇的な改良につながる可能性がある。アクセスを民主化することで、クリエイターは最大限の影響を与えるために技術を形作ることができる。
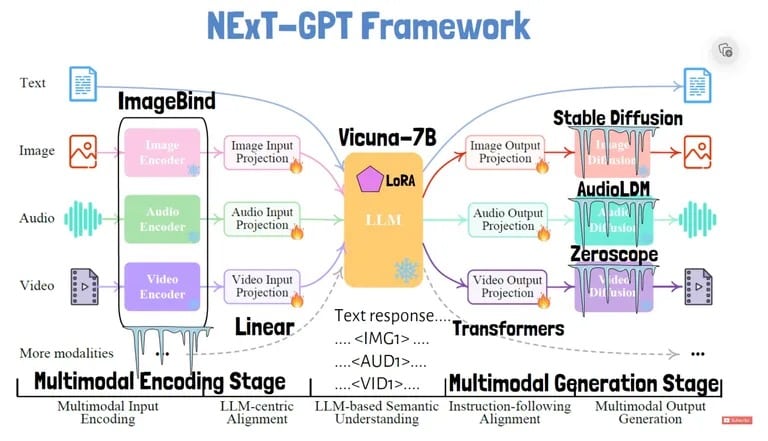
では、NExT-GPTはどのように機能するのだろうか?このモデルの研究論文で説明されているように、このシステムは、画像や音声などの入力を、コアの言語モデルが処理できるテキストのような表現にエンコードするための個別のモジュールを備えている。
研究者たちは、クロスモーダル推論能力(異なるタイプの入力を1つの一貫した構造として処理する能力)を向上させるために、「モダリティ切り替え命令チューニング」と呼ばれる技術を導入した。このチューニングにより、会話中にモダリティをシームレスに切り替えることができるようになる。
入力を処理するために、NExT-GPTは、画像、音声、ビデオのような固有のトークンを使用する。各入力タイプは、言語モデルが理解できるエンベッディングに変換される。言語モデルは、応答テキストを出力し、他のモダリティでの生成をトリガーするための特別なシグナル・トークンも出力できる。
応答のトークンは、例えばビデオデコーダーに対応するビデオ出力を生成するよう指示する。このシステムでは、入力と出力のモダリティごとに調整されたトークンを使用することで、柔軟なany-to-any変換を可能にしている。
言語モデルは、画像のような非テキスト出力がいつ生成されるべきかを示す特別なトークンを出力する。その後、異なるデコーダが各モダリティの出力を生成する: 画像デコーダーはStable Diffusion、音声デコーダーはAudioLDM、ビデオデコーダーはZeroscopeである。また、VicunaをベースLLMとして使用し、ImageBindで入力をエンコードする。
NExT-GPTは本質的に、異なるAIのパワーを組み合わせて、オールインワンのスーパーAIとなるモデルである
。
Screenshot courtesy of: AI Papers Academy via YouTube
NExT-GPTは、全パラメータの1%しかトレーニングしないのに、この柔軟な「any-to-any」変換を実現している。残りのパラメータは凍結され、事前に学習されたモジュールであり、非常に効率的な設計として研究者から賞賛を得た。
NExT-GPTをテストできるデモサイトが開設されているが、利用は断続的である。
グーグルやOpenAIのようなハイテク大手が独自のマルチモーダルAI製品を発表する中、NExT-GPTはクリエイターが構築できるオープンソースの選択肢となる。マルチモーダリティは自然なインタラクションの鍵です。そして、NExT-GPTをオープンソース化することで、研究者たちはAIを次のレベルに引き上げるための踏み台をコミュニティに提供している。