
Społeczność sztucznej inteligencji zyskała nowe pióro w swojej czapce wraz z wydaniem Falcon 180B, dużego modelu językowego (LLM) o otwartym kodzie źródłowym, który może pochwalić się 180 miliardami parametrów wyszkolonych na górze danych. Ten potężny nowicjusz przewyższył wcześniejsze modele LLM typu open source na kilku frontach.
Ogłoszony w poście na blogu przez społeczność Hugging Face AI, Falcon 180B został wydany na Hugging Face Hub. Najnowsza architektura modelu opiera się na poprzedniej serii LLM typu open source Falcon, wykorzystując innowacje, takie jak uwaga na wiele zapytań, w celu skalowania do 180 miliardów parametrów wytrenowanych na 3,5 biliona tokenów.
Stanowi to najdłuższy jak dotąd wstępny trening pojedynczego depo dla modelu open source. Aby osiągnąć takie wyniki, 4096 procesorów graficznych było używanych jednocześnie przez około 7 milionów godzin pracy GPU, wykorzystując Amazon SageMaker do szkolenia i udoskonalania.
Aby spojrzeć na rozmiar Falcona 180B z odpowiedniej perspektywy, jego parametry są 2,5 razy większe niż modelu LLaMA 2 firmy Meta. LLaMA 2 był wcześniej uważany za najbardziej wydajny LLM typu open source po jego uruchomieniu na początku tego roku, szczycąc się 70 miliardami parametrów wytrenowanych na 2 bilionach tokenów.
Falcon 180B przewyższa LLaMA 2 i inne modele zarówno pod względem skali, jak i wydajności w wielu zadaniach przetwarzania języka naturalnego (NLP). Plasuje się w czołówce modeli otwartego dostępu z 68,74 punktami i osiąga niemal równość z modelami komercyjnymi, takimi jak PaLM-2 Google, w ocenach takich jak benchmark HellaSwag.
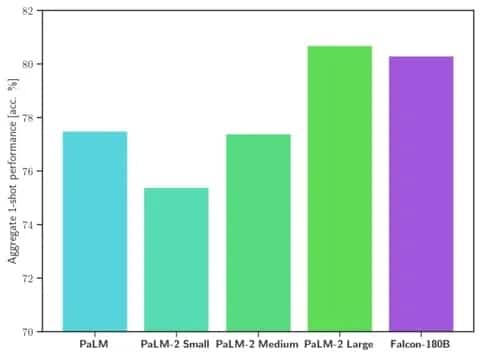
Image: Hugging Face
W szczególności Falcon 180B dorównuje lub przewyższa PaLM-2 Medium w powszechnie używanych benchmarkach, w tym HellaSwag, LAMBADA, WebQuestions, Winogrande i innych. Zasadniczo jest na równi z PaLM-2 Large firmy Google. Stanowi to niezwykle wysoką wydajność dla modelu open-source, nawet w porównaniu z rozwiązaniami opracowanymi przez gigantów w branży.
W porównaniu z ChatGPT, model ten jest bardziej wydajny niż darmowa wersja, ale nieco mniej wydajny niż płatna usługa „plus”.
„Falcon 180B zazwyczaj plasuje się gdzieś pomiędzy GPT 3.5 a GPT4, w zależności od benchmarku oceny, a dalsze dostrajanie przez społeczność będzie bardzo interesujące do śledzenia teraz, gdy jest otwarcie wydany” – czytamy na blogu.
Wydanie Falcon 180B stanowi najnowszy krok naprzód w szybkim postępie, jaki ostatnio poczyniono w zakresie LLM. Oprócz skalowania parametrów, techniki takie jak LoRA, randomizacja wagi i Perfusion firmy Nvidia umożliwiły znacznie wydajniejsze szkolenie dużych modeli sztucznej inteligencji.
Ponieważ Falcon 180B jest teraz swobodnie dostępny na Hugging Face, naukowcy przewidują, że model ten odnotuje dodatkowe korzyści dzięki dalszym ulepszeniom opracowanym przez społeczność. Jednak jego demonstracja zaawansowanych możliwości języka naturalnego od samego początku oznacza ekscytujący rozwój sztucznej inteligencji typu open source.