
De ongebreidelde verspreiding van deepfakes brengt aanzienlijke risico’s met zich mee – van het maken van afbeeldingen van naakte minderjarigen tot frauduleuze promoties waarbij deepfakes van beroemdheden worden gebruikt, het vermogen om AI-gegenereerde content (AIGC) te onderscheiden van door mensen gemaakte content is nog nooit zo kritisch geweest.
Eén methode om dergelijke inhoud te identificeren is
Watermerken, een veelgebruikte antivervalsingsmaatregel die voorkomt in documenten en geld, met toevoeging van informatie die helpt om een AI-gegenereerde afbeelding te onderscheiden van een niet-kunstmatige intelligentie-gegenereerde afbeelding. Recent onderzoek heeft echter geconcludeerd dat eenvoudige of zelfs geavanceerde watermerkmethoden mogelijk niet voldoende zijn om de risico’s te vermijden die gepaard gaan met het doorgaan van door AI gecreëerd materiaal als door mensen gemaakt.
Het onderzoek werd uitgevoerd door een team van onderzoekers van de Nanyang Technological University, S-Lab, NTU, Chongqing University, Shannon.AI en Zhejiang University.
Een van de auteurs, Li Guanlin, vertelde TCN dat “watermerken mensen kunnen helpen om te weten of inhoud door AI of mensen is gemaakt”. Hij voegde er echter aan toe dat “als het watermerk op de AIGC gemakkelijk te verwijderen of te vervalsen is, we door het watermerk toe te voegen anderen willekeurig kunnen overtuigen dat het kunstwerk door AI is gemaakt, of dat de AIGC door mensen is gemaakt door het watermerk te verwijderen.”
De paper onderzocht verschillende kwetsbaarheden van de huidige watermerkmethoden.
“Watermerkschema’s voor AIGC zijn kwetsbaar voor aanvallen door een tegenstander die het watermerk kan verwijderen zonder de geheime sleutel te kennen,” aldus het rapport. Deze kwetsbaarheid heeft gevolgen voor de echte wereld, vooral als het gaat om verkeerde informatie of kwaadwillig gebruik van AI-gegenereerde inhoud.
“Als kwaadwillende gebruikers valse AI-gegenereerde afbeeldingen van beroemdheden verspreiden na het verwijderen van watermerken, is het onmogelijk om te bewijzen dat de afbeeldingen door AI zijn gegenereerd, omdat we niet genoeg bewijs hebben,” vertelde Li aan TCN.
Li en zijn team voerden een reeks experimenten uit om de robuustheid en integriteit van de huidige watermerkmethoden te testen op AI-gegenereerde inhoud. Ze gebruikten verschillende technieken om watermerken te verwijderen of te vervalsen en evalueerden het gemak en de effectiviteit van elke methode. De resultaten lieten consistent zien dat watermerken relatief eenvoudig te verstoren zijn.
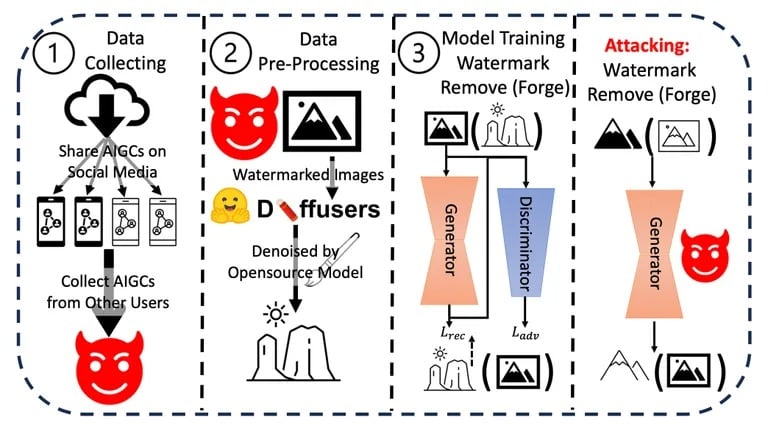
Aanvalsprocedure gebruikt in het onderzoek. Afbeelding: Arvix
Verder evalueerden ze de mogelijke gevolgen van deze kwetsbaarheden in de echte wereld, met name in scenario’s met verkeerde informatie of kwaadaardig gebruik van AI-gegenereerde inhoud. De cumulatieve bevindingen van deze experimenten en analyses leidden tot de conclusie dat er dringend robuustere watermerkmechanismen nodig zijn.
Hoewel bedrijven als OpenAI hebben aangekondigd dat ze methoden hebben ontwikkeld om AI-gegenereerde inhoud met 99% nauwkeurigheid te detecteren, blijft de algehele uitdaging bestaan. Huidige identificatiemethoden zoals metadata en onzichtbare watermerken hebben hun beperkingen.
Li suggereert dat “om AIGC te beschermen, het beter is om sommige cryptografische methoden, zoals digitale handtekeningen, te combineren met bestaande watermerkschema’s,” hoewel de exacte implementatie onduidelijk blijft.
Andere onderzoekers hebben een extremere aanpak bedacht. Zoals TCN onlangs meldde, heeft een MIT-team voorgesteld om afbeeldingen te veranderen in “vergif” voor kunstmatige intelligentiemodellen. Als een “vergiftigde” afbeelding zou worden gebruikt als input voor een trainingsdataset, zou het resulterende model slechte resultaten opleveren omdat het details zou bevatten die niet zichtbaar zijn voor het menselijk oog, maar wel een grote impact hebben op het trainingsproces. Het zou als een dodelijk watermerk zijn dat het getrainde model om zeep helpt.
De snelle vooruitgang in AI, benadrukt door OpenAI CEO Sam Altman, suggereert een toekomst waarin de natuurlijke denkprocessen van AI de menselijke logica en intuïtie kunnen weerspiegelen. Met zulke vooruitgang wordt de behoefte aan robuuste beveiligingsmaatregelen zoals watermerken nog dringender.
Li is van mening dat “watermerken en contentbeheer noodzakelijk zijn omdat ze niet echt van invloed zijn op gewone gebruikers”, maar het conflict tussen makers en tegenstanders blijft bestaan. “Het zal altijd een kat-en-muisspel blijven… Daarom moeten we onze watermerkschema’s constant bijwerken.”