
В связи с тем, что широкое распространение глубоких подделок несет в себе значительные риски — от создания обнаженных изображений несовершеннолетних до мошеннических рекламных акций с использованием глубоких подделок знаменитостей, — способность отличать контент, созданный искусственным интеллектом (ИИ), от контента, созданного человеком, как никогда важна.
Одним из методов идентификации такого контента является нанесение водяных знаков — распространенная мера защиты от подделок, применяемая в документах и валюте, — с добавлением информации, позволяющей отличить изображение, созданное ИИ, от изображения, не созданного ИИ. Однако в недавнем исследовании был сделан вывод о том, что простых или даже продвинутых методов нанесения водяных знаков может оказаться недостаточно для предотвращения рисков, связанных с выдачей материалов, созданных ИИ, за человеческие.
Исследование проводилось группой ученых из Наньянского технологического университета, S-Lab, NTU, Чунцинского университета, Shannon.AI и Чжэцзянского университета.
Один из авторов, Ли Гуаньлинь, рассказал TCN, что «водяной знак может помочь людям узнать, сгенерирован ли контент искусственным интеллектом или человеком». Однако, добавил он, «если водяной знак на AIGC легко удалить или подделать, мы можем свободно заставить других поверить, что художественное произведение создано искусственным интеллектом, добавив водяной знак, или что AIGC создан человеком, удалив водяной знак».
В работе исследованы различные уязвимости существующих методов водяных знаков.
«Схемы водяных знаков для AIGC уязвимы для атак противника, который может удалить водяной знак, не зная секретного ключа, — говорится в статье. Эта уязвимость имеет реальные последствия, особенно если речь идет о дезинформации или злонамеренном использовании контента, созданного ИИ.
«Если какие-то злоумышленники распространят сгенерированные ИИ поддельные изображения знаменитостей после удаления водяных знаков, то доказать, что эти изображения сгенерированы ИИ, будет невозможно, поскольку у нас нет достаточных доказательств», — сказал Ли в интервью TCN.
Ли и его команда провели серию экспериментов, проверяя устойчивость и целостность существующих методов нанесения водяных знаков на контент, сгенерированный искусственным интеллектом. Они применяли различные методы удаления или подделки водяных знаков, оценивая простоту и эффективность каждого из них. Результаты показали, что водяные знаки могут быть скомпрометированы с относительной легкостью.
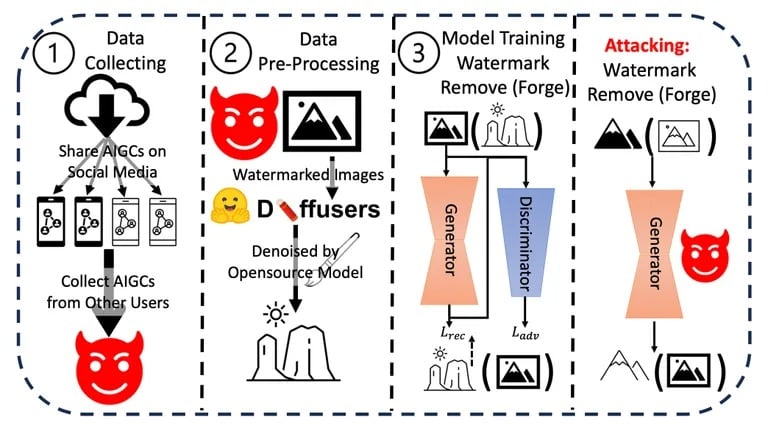
Процесс атаки, использованный в исследовании. Изображение: Arvix
Дополнительно они оценили потенциальные последствия этих уязвимостей в реальном мире, особенно в сценариях, связанных с дезинформацией или злонамеренным использованием контента, созданного ИИ. Совокупность результатов этих экспериментов и анализов позволила им сделать вывод о том, что существует острая необходимость в более надежных механизмах водяных знаков.
Несмотря на то что такие компании, как OpenAI, объявили о разработке методов обнаружения контента, созданного искусственным интеллектом, с точностью 99%, общая проблема остается актуальной. Существующие методы идентификации, такие как метаданные и невидимые водяные знаки, имеют свои недостатки.
Ли считает, что «для защиты AIGC лучше сочетать некоторые методы криптографии, такие как цифровая подпись, с существующими схемами водяных знаков», хотя точная реализация остается неясной.
Другие исследователи предложили более экстремальный подход. Как недавно сообщило издание TCN, группа специалистов Массачусетского технологического института предложила превратить изображения в «яд» для моделей искусственного интеллекта. Если «отравленное» изображение использовать в качестве входного в обучающем наборе данных, то итоговая модель будет давать плохие результаты, поскольку будет улавливать детали, которые не видны человеческому глазу, но оказывают большое влияние на процесс обучения. Это было бы похоже на смертоносный водяной знак, который убивает обучаемую модель.
Стремительный прогресс в области ИИ, о котором говорит генеральный директор OpenAI Сэм Альтман, позволяет предположить, что в будущем мыслительные процессы, присущие ИИ, могут стать зеркальным отражением человеческой логики и интуиции. С таким развитием событий необходимость в надежных мерах безопасности, таких как водяные знаки, становится еще более актуальной.
Ли считает, что «водяные знаки и управление контентом необходимы, поскольку они фактически не влияют на обычных пользователей», однако конфликт между создателями и противниками сохраняется. «Это всегда будет игра в кошки-мышки… Именно поэтому нам необходимо постоянно обновлять схемы водяных знаков».