
La diffusione dilagante dei deepfake comporta rischi significativi: dalla creazione di immagini di nudo di minori alla truffa di promozioni fraudolente con deepfake di celebrità, la capacità di distinguere i contenuti generati dall’intelligenza artificiale (AIGC) da quelli creati dall’uomo non è mai stata così cruciale.
La filigrana, una misura anticontraffazione comune nei documenti e nella valuta, è un metodo per identificare tali contenuti, con l’aggiunta di informazioni che aiutano a differenziare un’immagine generata dall’IA da una non generata dall’IA. Ma una recente ricerca ha concluso che i metodi di watermarking semplici o addirittura avanzati potrebbero non essere sufficienti a prevenire i rischi associati alla pubblicazione di materiale generato dall’IA come prodotto dall’uomo.
La ricerca è stata condotta da un team di scienziati della Nanyang Technological University, dell’S-Lab, della NTU, dell’Università di Chongqing, di Shannon.AI e della Zhejiang University.
Uno degli autori, Li Guanlin, ha dichiarato al TCN che “la filigrana può aiutare le persone a sapere se il contenuto è generato dall’IA o dagli esseri umani”. Ma ha aggiunto: “Se la filigrana sull’AIGC è facile da rimuovere o da falsificare, possiamo liberamente far credere che un’opera d’arte sia generata dall’IA aggiungendo una filigrana, o che un AIGC sia creato dall’uomo rimuovendo la filigrana”.
Il documento ha esplorato varie vulnerabilità degli attuali metodi di watermarking.
“Gli schemi di watermarking per AIGC sono vulnerabili agli attacchi avversari, che possono rimuovere la filigrana senza conoscere la chiave segreta”, si legge. Questa vulnerabilità ha implicazioni nel mondo reale, soprattutto per quanto riguarda la disinformazione o l’uso malevolo di contenuti generati dall’intelligenza artificiale.
“Se alcuni utenti malintenzionati diffondono immagini false generate dall’IA di alcune celebrità dopo aver rimosso i watermark, è impossibile dimostrare che le immagini sono state generate dall’IA, poiché non abbiamo prove sufficienti”, ha dichiarato Li al TCN.
Li e il suo team hanno condotto una serie di esperimenti per testare la resilienza e l’integrità degli attuali metodi di watermarking sui contenuti generati dall’IA. Hanno applicato varie tecniche per rimuovere o falsificare i watermark, valutando la facilità e l’efficacia di ciascun metodo. I risultati hanno dimostrato che i watermark possono essere compromessi con relativa facilità.
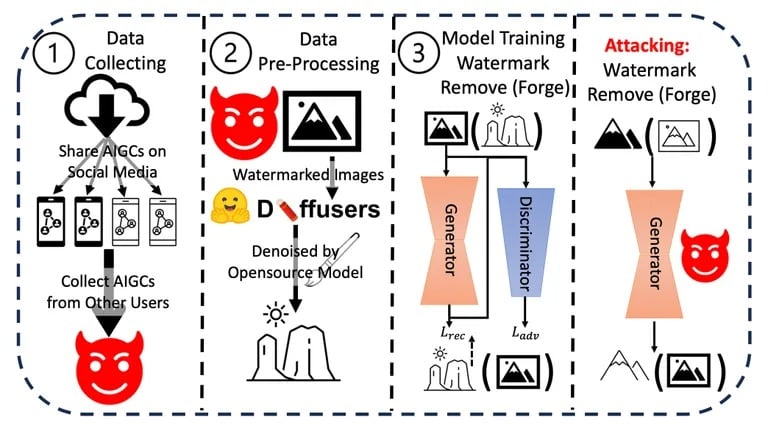
Processo di attacco utilizzato nella ricerca. Immagine: Arvix
Inoltre, hanno valutato le potenziali implicazioni nel mondo reale di queste vulnerabilità, soprattutto in scenari di disinformazione o di uso malevolo di contenuti generati dall’intelligenza artificiale. I risultati cumulativi di questi esperimenti e analisi li hanno portati a concludere che c’è un bisogno urgente di meccanismi di watermarking più robusti.
Anche se aziende come OpenAI hanno annunciato di aver sviluppato metodi per rilevare i contenuti generati dall’IA con un’accuratezza del 99%, la sfida generale rimane. Gli attuali metodi di identificazione, come i metadati e il watermarking invisibile, hanno i loro limiti.
Li suggerisce che “è meglio combinare alcuni metodi di crittografia come la firma digitale con gli schemi di watermarking esistenti per proteggere l’AIGC”, anche se l’implementazione esatta rimane poco chiara.
Altri ricercatori hanno proposto un approccio più estremo. Come riportato di recente da TCN, un team del MIT ha proposto di trasformare le immagini in “veleno” per i modelli di intelligenza artificiale. Se un’immagine “avvelenata” viene utilizzata come input in un set di dati per l’addestramento, il modello finale produrrebbe risultati negativi perché coglierebbe dettagli non visibili dall’occhio umano ma molto influenti nel processo di addestramento. Sarebbe come una filigrana mortale che uccide il modello che addestra.
I rapidi progressi dell’IA, come sottolineato da Sam Altman, CEO di OpenAI, suggeriscono un futuro in cui i processi di pensiero intrinseci dell’IA potrebbero rispecchiare la logica e l’intuizione umana. Con questi progressi, la necessità di misure di sicurezza solide come il watermarking diventa ancora più importante.
Li ritiene che “il watermarking e il governo dei contenuti siano essenziali perché in realtà non influenzano gli utenti normali”, ma il conflitto tra creatori e avversari persiste. “Sarà sempre un gioco tra gatto e topo… Ecco perché dobbiamo continuare ad aggiornare i nostri schemi di watermarking “