
Разпространението на дълбоки фалшификати носи значителни рискове – от създаването на голи изображения на непълнолетни лица до измама на лица с измамни промоции, използващи дълбоки фалшификати на известни личности – способността да се разграничава съдържанието, генерирано от изкуствен интелект (AI-generated content – AIGC), от това, създадено от хора, никога не е била по-важна.
Водният знак, често срещана мярка за борба с фалшифицирането на документи и парични знаци, е един от методите за идентифициране на такова съдържание, като се добавя информация, която помага за разграничаването на изображение, генерирано от ИИ, от изображение, което не е генерирано от ИИ. Но в неотдавнашен изследователски документ се стига до заключението, че простите или дори усъвършенстваните методи за воден знак може наистина да не са достатъчни за предотвратяване на рисковете, свързани с пускането на материали с ИИ като създадени от човека.
Изследването е проведено от екип от учени от Технологичния университет в Нанянг, S-Lab, NTU, Университета в Чунцин, Shannon.AI и Университета в Джъдзян.
Един от авторите, Ли Гуанлин, заяви пред TCN, че „водният знак може да помогне на хората да разберат дали съдържанието е генерирано от ИИ или от хора“. Но той добави: „Ако водният знак на AIGC е лесен за премахване или фалшифициране, можем свободно да накараме другите да повярват, че дадено произведение на изкуството е генерирано от ИИ, като добавим воден знак, или че AIGC е създаден от хора, като премахнем водния знак.“
В статията са изследвани различни уязвимости в настоящите методи за създаване на водни знаци.
„Схемите за създаване на водни знаци за AIGC са уязвими на атаки от противници, които могат да премахнат водния знак, без да знаят тайния ключ“, се казва в него. Тази уязвимост поражда последици в реалния свят, особено що се отнася до дезинформацията или злонамереното използване на съдържание, генерирано от изкуствен интелект.
„Ако някои злонамерени потребители разпространяват генерирани от ИИ фалшиви изображения на някои известни личности след премахване на водните знаци, не е възможно да се докаже, че изображенията са генерирани от ИИ, тъй като нямаме достатъчно доказателства“, казва Ли пред TCN.
Ли и неговият екип проведоха серия от експерименти, в които тестваха устойчивостта и целостта на настоящите методи за водни знаци върху съдържание, генерирано от ИИ. Те приложиха различни техники за премахване или подправяне на водните знаци, като оцениха лекотата и ефективността на всеки метод. Резултатите последователно показаха, че водните знаци могат да бъдат компрометирани сравнително лесно.
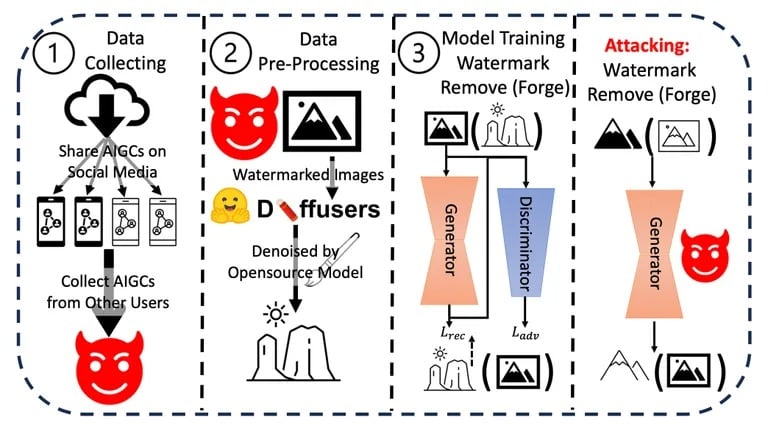
Процес на атака, използван в изследването. Изображение: Arvix
Допълнително те оцениха потенциалните последици от тези уязвимости в реалния свят, особено при сценарии, включващи дезинформация или злонамерено използване на съдържание, генерирано от изкуствен интелект. Кумулативните констатации от тези експерименти и анализи ги доведоха до заключението, че съществува неотложна необходимост от по-стабилни механизми за водни знаци.
Въпреки че компании като OpenAI обявиха, че са разработили методи за откриване на съдържание, генерирано от изкуствен интелект, с точност 99%, цялостното предизвикателство остава. Настоящите методи за идентификация, като метаданни и невидими водни знаци, имат своите ограничения.
Ли предполага, че „е по-добре да се комбинират някои криптографски методи като цифров подпис със съществуващите схеми за водни знаци, за да се защити АИГК“, въпреки че точното изпълнение остава неясно.
Други изследователи са предложили по-краен подход. Както неотдавна съобщи TCN, екип от Масачузетския технологичен институт (MIT) е предложил да превърне изображенията в „отрова“ за моделите на изкуствения интелект. Ако „отровено“ изображение се използва като входна информация в набор от данни за обучение, крайният модел ще даде лоши резултати, защото ще улови детайли, които не се виждат от човешкото око, но са силно влиятелни в процеса на обучение. То би било като смъртоносен воден знак, който убива обучаващия го модел.
Бързият напредък в областта на ИИ, подчертан от главния изпълнителен директор на OpenAI Сам Алтман, предполага бъдеще, в което присъщите на ИИ мисловни процеси биха могли да отразяват човешката логика и интуиция. При такъв напредък необходимостта от надеждни мерки за сигурност, като например водни знаци, става още по-важна.
Ли смята, че „водните знаци и управлението на съдържанието са от съществено значение, защото всъщност няма да повлияят на нормалните потребители“, но конфликтът между създателите и противниците продължава. „Това винаги ще бъде игра на котка и мишка… Ето защо трябва да продължаваме да актуализираме схемите си за водни знаци. „