
Es war eine Unternehmensspionage-Geschichte, die sich nicht einmal ein menschlicher Drehbuchautor hätte ausdenken können. OpenAI, das im vergangenen Jahr die weltweite Besessenheit mit KI ausgelöst hat, geriet durch die plötzliche Entlassung und spätere Wiedereinsetzung von Sam Altman, dem CEO des Unternehmens, in die Schlagzeilen.
Auch wenn Altman wieder an seinem alten Platz steht, bleiben viele Fragen offen, darunter auch die, was hinter den Kulissen passiert ist.
Einige beschrieben das Chaos als eine Schlacht auf dem Niveau von HBOs „Succession“ oder „Game of Thrones“. Andere spekulierten, dass es daran lag, dass Altman seinen Schwerpunkt auf andere Unternehmen wie Worldcoin verlagerte.
Aber die neueste und überzeugendste Theorie besagt, dass er wegen eines einzigen Briefes gefeuert wurde: Q.
Ungenannte Quellen sagten Reuters, dass OpenAI CTO Mira Murati sagte, dass eine wichtige Entdeckung – beschrieben als „Q Star“ oder „Q*“ – der Anstoß für den Schritt gegen Altman war, der ohne Beteiligung des Vorstandsvorsitzenden Greg Brockman durchgeführt wurde, der daraufhin aus Protest von OpenAI zurücktrat.
Was in aller Welt ist „Q*“ und warum sollte uns das interessieren? Es geht um die wahrscheinlichsten Pfade, die die KI-Entwicklung von hier aus nehmen könnte:
Enthüllung des Geheimnisses von Q*
Das von Mira Murati, CTO von OpenAI, erwähnte rätselhafte Q* hat in der KI-Gemeinschaft zu wilden Spekulationen geführt. Dieser Begriff könnte sich auf eine von zwei verschiedenen Theorien beziehen: Q-Learning oder der Q*-Algorithmus des Maryland Refutation Proof Procedure System (MRPPS). Das Verständnis des Unterschieds zwischen diesen beiden ist entscheidend, um die potenziellen Auswirkungen von Q* zu erfassen.
Theorie 1: Q-Learning
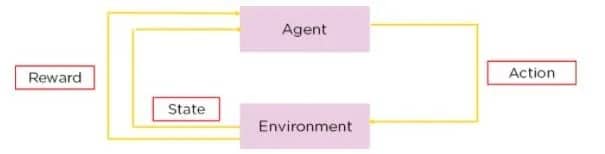
Q-Lernen ist eine Art des Verstärkungslernens, eine Methode, bei der KI lernt, Entscheidungen durch Versuch und Irrtum zu treffen. Beim Q-Learning lernt ein Agent, Entscheidungen zu treffen, indem er die „Qualität“ von Aktions-Zustands-Kombinationen abschätzt.
Quelle: Simplilearn
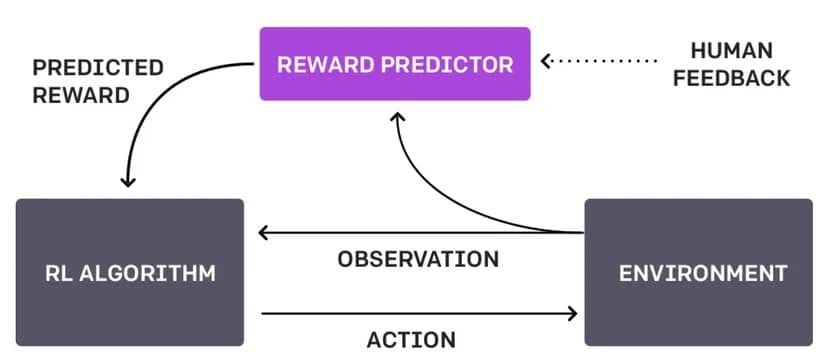
Der Unterschied zwischen diesem Ansatz und dem aktuellen Ansatz von OpenAI – bekannt als Reinforcement Learning Through Human Feedback (RLHF) – besteht darin, dass er sich nicht auf die menschliche Interaktion verlässt und alles selbständig macht.
RLHF-Diagramm. Bild: OpenAI
Stellen Sie sich einen Roboter vor, der durch ein Labyrinth navigiert. Mit Q-Learning lernt er, den schnellsten Weg zum Ausgang zu finden, indem er verschiedene Routen ausprobiert. Er erhält positive Belohnungen, die von ihm selbst festgelegt werden, wenn er sich dem Ausgang nähert, und negative Belohnungen, wenn er in eine Sackgasse gerät. Im Laufe der Zeit entwickelt der Roboter durch Versuch und Irrtum eine Strategie (eine „Q-Tabelle“), die ihm sagt, was er von jeder Position im Labyrinth aus am besten tun sollte. Dieser Prozess ist autonom und beruht auf den Interaktionen des Roboters mit seiner Umgebung.
Würde der Roboter RLHF verwenden, könnte ein Mensch eingreifen, wenn der Roboter eine Kreuzung erreicht, um ihm mitzuteilen, ob seine Wahl klug war oder nicht.
Dieses Feedback könnte in Form von direkten Befehlen („biege links ab“), Vorschlägen („versuche den Weg mit mehr Licht“) oder Bewertungen der Entscheidungen des Roboters („guter Roboter“ oder „schlechter Roboter“) erfolgen.
Beim Q-Lernen stellt Q* den gewünschten Zustand dar, in dem ein Agent genau weiß, welche Aktion er in jedem Zustand am besten ausführen sollte, um seinen erwarteten Gesamtgewinn über die Zeit zu maximieren. Mathematisch ausgedrückt, erfüllt es die Bellman-Gleichung:
Im Mai veröffentlichte OpenAI einen Artikel, in dem es hieß, dass sie „ein Modell trainiert haben, um einen neuen Stand der Technik beim Lösen mathematischer Probleme zu erreichen, indem sie jeden korrekten Denkschritt belohnen, anstatt einfach die richtige endgültige Antwort zu belohnen.“ Wenn sie Q-Learning oder eine ähnliche Methode verwenden, um dies zu erreichen, würde dies eine ganze Reihe neuer Probleme und Situationen eröffnen, die ChatGPT von Haus aus lösen könnte.
Theorie 2: Q* Algorithmus von MRPPS
Der Q*-Algorithmus ist ein Teil des Maryland Refutation Proof Procedure System (MRPPS). Es handelt sich dabei um eine hochentwickelte Methode zum Theorembeweisen in der KI, insbesondere in Frage-Antwort-Systemen.
„Der Q∗-Algorithmus erzeugt Knoten im Suchraum, wobei er semantische und syntaktische Informationen verwendet, um die Suche zu lenken. Die Semantik erlaubt es, Pfade zu beenden und fruchtbare Pfade zu erforschen“, heißt es in dem Forschungspapier.
Bild: Jack Minker
Eine Möglichkeit, den Prozess zu erklären, ist, sich den fiktiven Detektiv Sherlock Holmes vorzustellen, der versucht, einen komplexen Fall zu lösen. Er sammelt Hinweise (semantische Informationen) und verknüpft sie logisch (syntaktische Informationen), um zu einer Schlussfolgerung zu gelangen. Der Q*-Algorithmus funktioniert in der KI ähnlich, indem er semantische und syntaktische Informationen kombiniert, um komplexe Problemlösungsprozesse zu steuern.
Dies würde bedeuten, dass OpenAI einen Schritt näher an ein Modell herankommt, das in der Lage ist, seine Realität jenseits von bloßen Textaufforderungen zu verstehen, und eher mit dem fiktiven J.A.R.V.I.S (für GenZers) oder dem Bat Computer (für Boomer) vergleichbar ist.
Während es beim Q-Learning also darum geht, der KI beizubringen, aus der Interaktion mit ihrer Umgebung zu lernen, geht es beim Q-Algorithmus eher um die Verbesserung der deduktiven Fähigkeiten der KI. Das Verständnis dieser Unterschiede ist der Schlüssel zum Verständnis der potenziellen Auswirkungen von OpenAIs „Q“. Beide haben ein immenses Potenzial für die Weiterentwicklung der KI, aber ihre Anwendungen und Auswirkungen unterscheiden sich erheblich.
All dies sind natürlich nur Spekulationen, da OpenAI das Konzept weder erklärt noch die Gerüchte bestätigt oder dementiert hat, dass Q* – was auch immer es ist – tatsächlich existiert.
Potenzielle Implikationen von ‚Q’*
OpenAIs gemunkeltes „Q*“ könnte weitreichende und vielfältige Auswirkungen haben. Wenn es sich um eine fortgeschrittene Form des Q-Learnings handelt, könnte dies einen Sprung in der Fähigkeit der KI bedeuten, in komplexen Umgebungen selbstständig zu lernen und sich anzupassen und damit eine ganz neue Reihe von Problemen zu lösen. Ein solcher Fortschritt könnte KI-Anwendungen in Bereichen wie autonomen Fahrzeugen verbessern, wo sekundenschnelle Entscheidungen auf der Grundlage sich ständig ändernder Bedingungen entscheidend sind.
Bezieht sich „Q“ hingegen auf den Q-Algorithmus von MRPPS, so könnte dies einen bedeutenden Fortschritt in der deduktiven Denkweise und den Problemlösungsfähigkeiten der KI bedeuten. Dies wäre vor allem in Bereichen von Bedeutung, die tiefgreifendes analytisches Denken erfordern, wie z. B. die juristische Analyse, die Interpretation komplexer Daten und sogar die medizinische Diagnose.
Unabhängig von seiner genauen Natur stellt „Q*“ potenziell einen bedeutenden Schritt in der KI-Entwicklung dar, so dass die Tatsache, dass es im Mittelpunkt einer existenziellen Debatte von OpenAI steht, richtig klingt. Es könnte uns näher an KI-Systeme heranführen, die intuitiver und effizienter sind und Aufgaben bewältigen können, die derzeit ein hohes Maß an menschlichem Fachwissen erfordern. Mit solchen Fortschritten kommen jedoch auch Fragen und Bedenken in Bezug auf die KI-Ethik, die Sicherheit und die Auswirkungen von immer leistungsfähigeren KI-Systemen auf unser tägliches Leben und die Gesellschaft im Allgemeinen.
Das Gute und das Schlechte von Q*
Potenzieller Nutzen von Q*:
Verbesserte Problemlösungsfähigkeit und Effizienz: Wenn Q* eine fortgeschrittene Form des Q-Learnings oder des Q*-Algorithmus ist, könnte es zu KI-Systemen führen, die komplexe Probleme effizienter lösen, was Sektoren wie dem Gesundheitswesen, dem Finanzwesen und dem Umweltmanagement zugute käme.
Bessere Mensch-KI-Zusammenarbeit: Eine KI mit verbesserten Lern- oder Schlussfolgerungsfähigkeiten könnte die menschliche Arbeit ergänzen und zu einer effektiveren Zusammenarbeit in Forschung, Innovation und bei täglichen Aufgaben führen.
Fortschritte in der Automatisierung: „Q*“ könnte zu ausgefeilteren Automatisierungstechnologien führen, die die Produktivität verbessern und möglicherweise neue Branchen und Beschäftigungsmöglichkeiten schaffen.
Risiken und Bedenken:
Ethische und Sicherheitsaspekte: Je fortschrittlicher die KI-Systeme werden, desto schwieriger wird es, ihren ethischen und sicheren Betrieb zu gewährleisten. Es besteht das Risiko unbeabsichtigter Folgen, insbesondere wenn KI-Aktionen nicht perfekt mit menschlichen Werten übereinstimmen.
Datenschutz und Sicherheit: Mit fortgeschrittener KI wachsen die Bedenken hinsichtlich des Datenschutzes und der Datensicherheit. KI-Systeme, die in der Lage sind, Daten besser zu verstehen und mit ihnen zu interagieren, könnten missbraucht werden. Stellen Sie sich also eine KI vor, die Ihren Liebespartner anruft, wenn Sie ihn betrügen, weil sie weiß, dass Betrug schlecht ist.
Wirtschaftliche Auswirkungen: Die zunehmende Automatisierung und die KI-Fähigkeiten könnten in bestimmten Sektoren zur Verdrängung von Arbeitsplätzen führen, was gesellschaftliche Anpassungen und neue Ansätze bei der Entwicklung von Arbeitskräften erforderlich macht. Wenn eine KI fast alles kann, wozu dann noch menschliche Arbeitskräfte?
KI-Fehlanpassung: Das Risiko, dass KI-Systeme Ziele oder Arbeitsmethoden entwickeln, die nicht mit den Absichten oder dem Wohlergehen des Menschen übereinstimmen, was zu schädlichen Ergebnissen führen kann. Stellen Sie sich einen Hausputzroboter vor, der besessen von Ordnung ist und ständig wichtige Papiere wegwirft. Oder der die Verursacher von Unordnung ganz ausschaltet?
Der Mythos der AGI
Wo steht OpenAIs gemunkeltes Q* inmitten des Strebens nach Künstlicher Allgemeiner Intelligenz (AGI) – dem heiligen Gral der KI-Forschung?
AGI bezieht sich auf die Fähigkeit einer Maschine, zu verstehen, zu lernen und Intelligenz auf verschiedene Aufgaben anzuwenden, ähnlich wie die kognitiven Fähigkeiten des Menschen. Es handelt sich um eine Form der KI, die das Lernen von einem Bereich auf einen anderen verallgemeinern kann und damit echte Anpassungsfähigkeit und Vielseitigkeit demonstriert.
Unabhängig davon, ob Q eine fortgeschrittene Form des Q-Learnings ist oder sich auf den Q-Algorithmus bezieht, ist es wichtig zu verstehen, dass dies nicht gleichbedeutend mit dem Erreichen einer AGI ist. Während „Q*“ einen bedeutenden Fortschritt bei den spezifischen KI-Fähigkeiten darstellen mag, umfasst AGI ein breiteres Spektrum an Fähigkeiten und Verständnis.
Das Erreichen von AGI würde bedeuten, eine KI zu entwickeln, die jede intellektuelle Aufgabe ausführen kann, die auch ein Mensch ausführen kann – ein schwer zu erreichender Meilenstein.
Eine Maschine, die Q erreicht hat, ist sich ihrer eigenen Existenz nicht bewusst und kann noch nicht über die Grenzen ihrer vortrainierten Daten und von Menschen eingestellten Algorithmen hinaus denken. Trotz des großen Interesses ist „Q“ also noch nicht der Vorbote unserer künstlichen Intelligenz; es ist eher ein intelligenter Toaster, der gelernt hat, sich selbst die Butter aufs Brot zu schmieren.
Was das Ende der Zivilisation durch AGI angeht, so überschätzen wir vielleicht unsere Bedeutung in der kosmischen Hackordnung. Q* von OpenAI könnte der KI unserer Träume (oder Albträume) einen Schritt näher kommen, aber es ist nicht ganz die AGI, die über den Sinn des Lebens oder ihre eigene Siliziumexistenz nachdenken wird.
Denken Sie daran, dass es sich um dieselbe OpenAI handelt, die ihr ChatGPT vorsichtig beäugt wie ein Elternteil sein Kleinkind mit einem Marker – stolz, aber immer in Sorge, dass es die Wände der Menschheit bemalt. Während „Q*“ ein Sprung ist, bleibt AGI noch einen Schritt entfernt, und die Mauer der Menschheit ist vorerst sicher.