
To była historia korporacyjnego szpiegostwa, której nie wymyśliłby nawet prawdziwy ludzki scenarzysta. OpenAI, które w zeszłym roku wywołało globalną obsesję na punkcie sztucznej inteligencji, znalazło się na pierwszych stronach gazet wraz z nagłym zwolnieniem i ostatecznym przywróceniem Sama Altmana, dyrektora generalnego firmy.
Nawet z Altmanem z powrotem tam, gdzie zaczynał, pozostaje wirująca chmura pytań, w tym o to, co wydarzyło się za kulisami.
Niektórzy opisywali chaos jako bitwę na poziomie HBO „Sukcesja” lub „Gra o tron”. Inni spekulowali, że stało się tak, ponieważ Altman przeniósł swoją uwagę na inne firmy, takie jak Worldcoin.
Ale najnowsza i najbardziej przekonująca teoria mówi, że został zwolniony z powodu jednego listu: Q.
Bezimienne źródła podały agencji Reuters, że CTO OpenAI Mira Murati powiedziała, że główne odkrycie – opisane jako „Q Star” lub „Q*” – było impulsem do działania przeciwko Altmanowi, które zostało wykonane bez udziału prezesa zarządu Grega Brockmana, który następnie zrezygnował z OpenAI w proteście.
Czym w ogóle jest „Q*” i dlaczego powinno nas to obchodzić? Chodzi o najbardziej prawdopodobne ścieżki, którymi może podążyć rozwój sztucznej inteligencji.
Odkrywanie tajemnicy Q*
Enigmatyczne Q* przywołane przez CTO OpenAI Mirę Murati doprowadziło do szalejących spekulacji w społeczności AI. Termin ten może odnosić się do jednej z dwóch różnych teorii: Q-learning lub algorytmu Q* z Maryland Refutation Proof Procedure System (MRPPS). Zrozumienie różnicy między nimi jest kluczowe dla zrozumienia potencjalnego wpływu Q*.
Teoria 1: Q-Learning
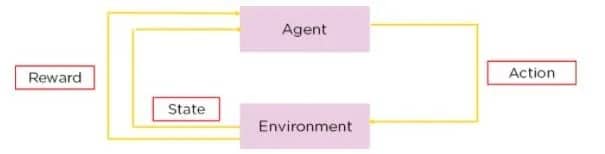
Q-learning to rodzaj uczenia ze wzmocnieniem, metoda, w której sztuczna inteligencja uczy się podejmować decyzje metodą prób i błędów. W Q-learning agent uczy się podejmować decyzje poprzez szacowanie „jakości” kombinacji stanów akcji.
Źródło: Simplilearn
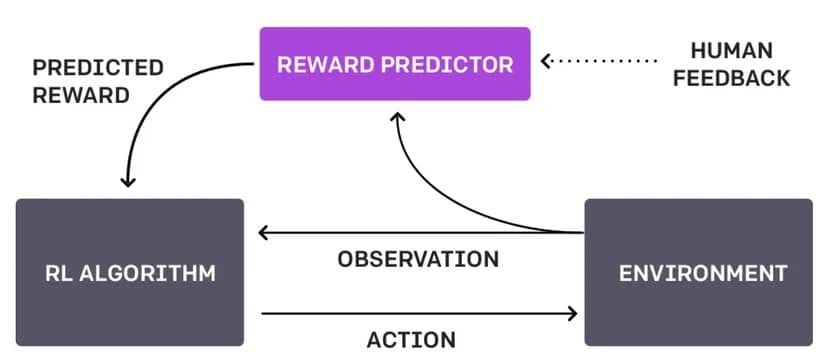
Różnica między tym podejściem a obecnym podejściem OpenAI – znanym jako Reinforcement Learning Through Human Feedback lub RLHF – polega na tym, że nie polega ono na interakcji z człowiekiem i robi wszystko samodzielnie.
Schemat RLHF. Image: OpenAI
Wyobraź sobie robota poruszającego się po labiryncie. Dzięki uczeniu Q uczy się on znajdować najszybszą ścieżkę do wyjścia, próbując różnych tras, otrzymując pozytywne nagrody ustalone przez jego własny projekt, gdy zbliża się do wyjścia i negatywne nagrody, gdy trafia w ślepy zaułek. Z biegiem czasu, metodą prób i błędów, robot opracowuje strategię („tabelę Q”), która podpowiada mu najlepsze działanie z każdej pozycji w labiryncie. Proces ten jest autonomiczny i opiera się na interakcji robota z otoczeniem.
Gdyby robot korzystał z RLHF, zamiast samodzielnie odkrywać pewne rzeczy, człowiek mógłby interweniować, gdy robot dotrze do skrzyżowania, aby wskazać, czy wybór robota był mądry, czy nie.
Informacje zwrotne mogą mieć formę bezpośrednich poleceń („skręć w lewo”), sugestii („spróbuj ścieżki z większą ilością światła”) lub oceny wyborów robota („dobry robot” lub „zły robot”).
W uczeniu Q, Q* reprezentuje pożądany stan, w którym agent dokładnie zna najlepsze działanie, jakie należy podjąć w każdym stanie, aby zmaksymalizować całkowitą oczekiwaną nagrodę w czasie. Z matematycznego punktu widzenia spełnia on równanie Bellmana.
W maju firma OpenAI opublikowała artykuł, w którym napisała, że „wytrenowała model, aby osiągnąć nowy stan wiedzy w rozwiązywaniu problemów matematycznych poprzez nagradzanie każdego poprawnego kroku rozumowania zamiast po prostu nagradzania poprawnej odpowiedzi końcowej”. Gdyby wykorzystali do tego Q-learning lub podobną metodę, odblokowałoby to zupełnie nowy zestaw problemów i sytuacji, które ChatGPT byłby w stanie rozwiązać natywnie.
Teoria 2: Algorytm Q* z MRPPS
Algorytm Q* jest częścią Maryland Refutation Proof Procedure System (MRPPS). Jest to zaawansowana metoda dowodzenia twierdzeń w sztucznej inteligencji, w szczególności w systemach odpowiadających na pytania.
„Algorytm Q∗ generuje węzły w przestrzeni wyszukiwania, stosując informacje semantyczne i składniowe do kierowania wyszukiwaniem. Semantyka pozwala na kończenie ścieżek i odkrywanie owocnych ścieżek” – czytamy w artykule badawczym.
Image: Jack Minker
Jednym ze sposobów wyjaśnienia tego procesu jest rozważenie fikcyjnego detektywa Sherlocka Holmesa próbującego rozwiązać złożoną sprawę. Zbiera on wskazówki (informacje semantyczne) i łączy je logicznie (informacje syntaktyczne), aby dojść do konkluzji. Algorytm Q* działa podobnie w sztucznej inteligencji, łącząc informacje semantyczne i syntaktyczne w celu poruszania się po złożonych procesach rozwiązywania problemów.
Oznaczałoby to, że OpenAI jest o krok bliżej do posiadania modelu zdolnego do zrozumienia rzeczywistości poza zwykłymi podpowiedziami tekstowymi i bardziej zgodnego z fikcyjnym J.A.R.V.I.S (dla GenZers) lub Bat Computer (dla boomers).
Tak więc, podczas gdy Q-learning polega na uczeniu sztucznej inteligencji uczenia się na podstawie interakcji z otoczeniem, algorytm Q polega bardziej na poprawie zdolności dedukcyjnych sztucznej inteligencji. Zrozumienie tych różnic jest kluczem do docenienia potencjalnych implikacji „Q” OpenAI. Oba mają ogromny potencjał w rozwijaniu sztucznej inteligencji, ale ich zastosowania i implikacje znacznie się różnią.
Wszystko to oczywiście tylko spekulacje, ponieważ OpenAI nie wyjaśniło tej koncepcji ani nawet nie potwierdziło ani nie zaprzeczyło pogłoskom, że Q* – czymkolwiek jest – faktycznie istnieje.
Potencjalne implikacje „Q „*
Potwierdzone przez OpenAI „Q*” może mieć ogromny i zróżnicowany wpływ. Jeśli jest to zaawansowana forma uczenia się Q, może to oznaczać skok w zdolności sztucznej inteligencji do uczenia się i autonomicznej adaptacji w złożonych środowiskach, rozwiązując zupełnie nowy zestaw problemów. Taki postęp mógłby usprawnić zastosowania sztucznej inteligencji w obszarach takich jak pojazdy autonomiczne, w których kluczowe znaczenie ma podejmowanie decyzji w ułamku sekundy w oparciu o stale zmieniające się warunki.
Z drugiej strony, jeśli „Q” odnosi się do algorytmu Q z MRPPS, może to oznaczać znaczący krok naprzód w dedukcyjnym rozumowaniu AI i możliwościach rozwiązywania problemów. Miałoby to szczególne znaczenie w dziedzinach wymagających głębokiego analitycznego myślenia, takich jak analiza prawna, interpretacja złożonych danych, a nawet diagnostyka medyczna.
Niezależnie od jego dokładnej natury, „Q*” potencjalnie stanowi znaczący krok w rozwoju sztucznej inteligencji, więc fakt, że jest on w centrum egzystencjalnej debaty OpenAI, brzmi prawdziwie. Może to przybliżyć nas do systemów sztucznej inteligencji, które są bardziej intuicyjne, wydajne i zdolne do obsługi zadań, które obecnie wymagają wysokiego poziomu ludzkiej wiedzy. Jednak wraz z takimi postępami pojawiają się pytania i obawy dotyczące etyki sztucznej inteligencji, bezpieczeństwa i implikacji coraz potężniejszych systemów sztucznej inteligencji w naszym codziennym życiu i całym społeczeństwie.
Dobre i złe strony Q*
Potencjalne korzyści z Q*:
Ulepszone rozwiązywanie problemów i wydajność: Jeśli Q* jest zaawansowaną formą uczenia Q lub algorytmu Q*, może to prowadzić do systemów sztucznej inteligencji, które skuteczniej rozwiązują złożone problemy, przynosząc korzyści sektorom takim jak opieka zdrowotna, finanse i zarządzanie środowiskiem.
Lepsza współpraca człowieka ze sztuczną inteligencją: Sztuczna inteligencja z ulepszonymi możliwościami uczenia się lub dedukcji mogłaby wspomagać pracę człowieka, prowadząc do bardziej efektywnej współpracy w zakresie badań, innowacji i codziennych zadań.
Postępy w automatyzacji: „Q*” może prowadzić do bardziej wyrafinowanych technologii automatyzacji, zwiększając produktywność i potencjalnie tworząc nowe branże i możliwości zatrudnienia.
Ryzyka i obawy:
Kwestie etyczne i bezpieczeństwa: W miarę jak systemy sztucznej inteligencji stają się coraz bardziej zaawansowane, zapewnienie ich etycznego i bezpiecznego działania staje się coraz większym wyzwaniem. Istnieje ryzyko niezamierzonych konsekwencji, zwłaszcza jeśli działania AI nie są idealnie dostosowane do ludzkich wartości.
Prywatność i bezpieczeństwo: Wraz z bardziej zaawansowaną sztuczną inteligencją nasilają się obawy dotyczące prywatności i bezpieczeństwa danych. Systemy AI zdolne do głębszego zrozumienia i interakcji z danymi mogą zostać niewłaściwie wykorzystane. Wyobraźmy sobie sztuczną inteligencję, która dzwoni do naszego romantycznego partnera, gdy go zdradzamy, ponieważ wie, że zdrada jest zła.
Skutki ekonomiczne: Zwiększona automatyzacja i możliwości sztucznej inteligencji mogą prowadzić do zwolnienia miejsc pracy w niektórych sektorach, wymagając dostosowań społecznych i nowego podejścia do rozwoju siły roboczej. Jeśli sztuczna inteligencja może zrobić prawie wszystko, po co zatrudniać ludzi?
Niedopasowanie SI: Ryzyko, że systemy AI mogą opracować cele lub metody działania, które są niezgodne z ludzkimi intencjami lub dobrobytem, potencjalnie prowadząc do szkodliwych skutków. Wyobraź sobie robota sprzątającego, który ma obsesję na punkcie porządku i wyrzuca ważne dokumenty? Albo całkowicie eliminuje twórców bałaganu?
Mit AGI
Gdzie plasuje się Q* od OpenAI w pogoni za Sztuczną Inteligencją Ogólną (AGI) – świętym Graalem badań nad SI?
AGI odnosi się do zdolności maszyny do rozumienia, uczenia się i stosowania inteligencji w różnych zadaniach, podobnie jak ludzkie zdolności poznawcze. Jest to forma sztucznej inteligencji, która może uogólniać uczenie się z jednej dziedziny na inną, wykazując prawdziwą zdolność adaptacji i wszechstronność.
Niezależnie od tego, czy Q jest zaawansowaną formą uczenia się Q, czy też odnosi się do algorytmu Q, ważne jest, aby zrozumieć, że nie jest to równoznaczne z osiągnięciem AGI. Podczas gdy „Q*” może stanowić znaczący krok naprzód w zakresie konkretnych możliwości AI, AGI obejmuje szerszy zakres umiejętności i zrozumienia.
Osiągnięcie AGI oznaczałoby opracowanie sztucznej inteligencji, która może wykonać każde zadanie intelektualne, które może wykonać człowiek – co jest nieuchwytnym kamieniem milowym.
Maszyna, która osiągnęła Q, nie jest świadoma własnego istnienia i nie może jeszcze rozumować poza granicami swoich danych przedtreningowych i algorytmów ustawionych przez człowieka. Więc nie, pomimo szumu, „Q” nie jest jeszcze zwiastunem naszych władców AI; jest bardziej jak inteligentny toster, który nauczył się smarować masłem własny chleb.
Jeśli chodzi o AGI zapowiadające koniec cywilizacji, możemy przeceniać nasze znaczenie w kosmicznym porządku dziobania. Q* od OpenAI może być o krok bliżej do SI z naszych snów (lub koszmarów), ale nie jest to AGI, która będzie zastanawiać się nad sensem życia lub własnym krzemowym istnieniem.
Pamiętajmy, że jest to ta sama OpenAI, która ostrożnie przygląda się swojemu ChatGPT, jak rodzic obserwujący malucha z markerem – dumny, ale wiecznie zaniepokojony, że narysuje na ścianach ludzkości. Podczas gdy „Q*” jest skokiem, AGI pozostaje o krok dalej, a ściana ludzkości jest na razie bezpieczna.