
Это была история корпоративного шпионажа, которую не смог бы придумать даже настоящий сценарист-человек. Компания OpenAI, которая в прошлом году дала толчок глобальной одержимости искусственным интеллектом, оказалась в заголовках газет после внезапного увольнения и последующего восстановления Сэма Альтмана, генерального директора компании.
Даже когда Альтман вернулся к своим обязанностям, остается множество вопросов, в том числе о том, что произошло за кулисами.
Некоторые описывали хаос как битву в «Преемственности» или «Игре престолов» на уровне HBO. Другие предполагали, что это произошло из-за того, что Альтман переключил свое внимание на другие компании, такие как Worldcoin.
Но самая последняя и самая убедительная теория гласит, что его уволили из-за одного письма: Q.
Неназванные источники сообщили Reuters, что технический директор OpenAI Мира Мурати заявила, что толчком к увольнению Альтмана послужило крупное открытие, названное «Q Star» или «Q*», которое было сделано без участия председателя совета директоров Грега Брокмана, который впоследствии ушел из OpenAI в знак протеста.
Что такое «Q*» и почему это должно нас волновать? Все дело в наиболее вероятных путях, по которым может пойти развитие ИИ дальше.
Раскрытие тайны Q*
Загадочный термин Q*, упомянутый техническим директором OpenAI Мирой Мурати, вызвал бурные спекуляции в сообществе ИИ. Этот термин может относиться к одной из двух различных теорий: Q-обучение или алгоритм Q* из Мэрилендской системы процедур доказательства опровержения (MRPPS). Понимание разницы между этими двумя теориями имеет решающее значение для осознания потенциального влияния Q*.
Теория 1: Q-обучение
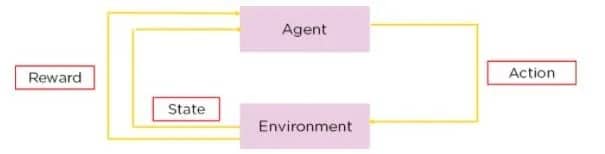
Q-обучение — это разновидность обучения с подкреплением, метод, при котором ИИ учится принимать решения методом проб и ошибок. В Q-обучении агент учится принимать решения, оценивая «качество» комбинаций действий-состояний.
Источник: Simplilearn
Отличие этого подхода от нынешнего подхода OpenAI, известного как Reinforcement Learning Through Human Feedback или RLHF, в том, что он не зависит от взаимодействия с человеком и делает все сам.
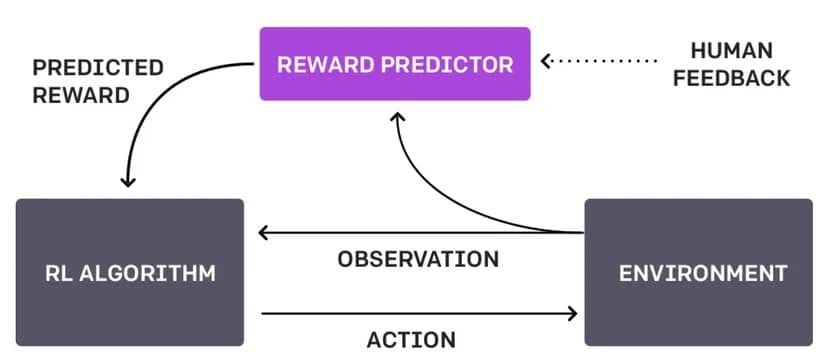
Диаграмма RLHF. Изображение: OpenAI
Представьте себе робота, перемещающегося по лабиринту. С помощью Q-обучения он учится находить кратчайший путь к выходу, пробуя разные маршруты, получая положительное вознаграждение, установленное его собственной разработкой, когда он приближается к выходу, и отрицательное, когда попадает в тупик. Со временем, путем проб и ошибок, робот вырабатывает стратегию («Q-таблицу»), которая подсказывает ему наилучшее действие в каждой позиции лабиринта. Этот процесс является автономным и зависит от взаимодействия робота с окружающей средой.
Если бы робот использовал RLHF, то вместо того, чтобы выяснять все самостоятельно, человек мог бы вмешаться, когда робот достигнет перекрестка, чтобы указать, был ли его выбор разумным или нет.
Эта обратная связь может быть в виде прямых команд («поверни налево»), предложений («попробуй пройти по более освещенному пути») или оценок выбора робота («хороший робот» или «плохой робот»).
В Q-обучении Q* представляет собой желаемое состояние, в котором агент точно знает, какое действие лучше предпринять в каждом состоянии, чтобы максимизировать общее ожидаемое вознаграждение с течением времени. В математических терминах оно удовлетворяет уравнению Беллмана.
В мае компания OpenAI опубликовала статью, в которой говорилось, что они «обучили модель достигать нового уровня в решении математических задач, вознаграждая каждый правильный шаг рассуждений вместо того, чтобы просто вознаграждать правильный окончательный ответ». Если они использовали Q-обучение или аналогичный метод для достижения этой цели, это открыло бы целый ряд новых проблем и ситуаций, которые ChatGPT мог бы решать нативно.
Теория 2: Алгоритм Q* из MRPPS
Алгоритм Q* является частью Мэрилендской системы процедур опровержения доказательств (MRPPS). Это сложный метод доказательства теорем в искусственном интеллекте, в частности в системах ответов на вопросы.
«Алгоритм Q∗ генерирует узлы в пространстве поиска, применяя семантическую и синтаксическую информацию для направления поиска. Семантика позволяет прервать поиск и найти плодотворные пути», — говорится в научной статье.
Image: Jack Minker
Один из способов объяснить этот процесс — рассмотреть вымышленного сыщика Шерлока Холмса, пытающегося раскрыть сложное дело. Он собирает улики (семантическую информацию) и логически соединяет их (синтаксическую информацию), чтобы прийти к выводу. Алгоритм Q* работает аналогичным образом в ИИ, объединяя семантическую и синтаксическую информацию для навигации по сложным процессам решения проблем.
Это означает, что OpenAI на шаг ближе к созданию модели, способной понимать реальность не только по текстовым подсказкам, но и в соответствии с вымышленными J.A.R.V.I.S (для поколения Z) или Bat Computer (для поколения Boom).
Таким образом, если Q-обучение — это обучение ИИ на основе взаимодействия с окружающей средой, то Q-алгоритм больше направлен на улучшение дедуктивных способностей ИИ. Понимание этих различий — ключ к оценке потенциальных последствий «Q» OpenAI. Обе технологии обладают огромным потенциалом в развитии ИИ, но их применение и последствия существенно различаются.
Разумеется, все это лишь предположения, поскольку OpenAI не объяснила концепцию, не подтвердила и не опровергла слухи о том, что Q* — чем бы он ни был — действительно существует.
Потенциальные последствия «Q «*
Слухи о ‘Q*’ от OpenAI могут иметь огромное и разнообразное влияние. Если это продвинутая форма Q-обучения, то это может означать скачок в способности ИИ к автономному обучению и адаптации в сложных условиях, что позволит решить целый ряд новых проблем. Такое развитие может способствовать применению ИИ в таких областях, как автономные транспортные средства, где принятие решений в доли секунды с учетом постоянно меняющихся условий имеет решающее значение.
С другой стороны, если «Q» относится к алгоритму Q из MRPPS, это может означать значительный шаг вперед в развитии дедуктивных рассуждений и способности ИИ решать проблемы. Это будет особенно актуально в областях, требующих глубокого аналитического мышления, таких как юридический анализ, интерпретация сложных данных и даже медицинская диагностика.
Независимо от его точной природы, «Q*» потенциально представляет собой значительный шаг в развитии ИИ, поэтому тот факт, что он находится в центре экзистенциальных дебатов OpenAI, не может не радовать. Она может приблизить нас к системам ИИ, которые будут более интуитивными, эффективными и способными решать задачи, которые в настоящее время требуют высокого уровня человеческой компетентности. Однако вместе с такими достижениями возникают вопросы и опасения по поводу этики ИИ, безопасности и последствий использования все более мощных систем ИИ в нашей повседневной жизни и обществе в целом.
Хорошее и плохое в Q*
Потенциальные преимущества Q*:
Улучшенное решение проблем и эффективность: Если Q* является усовершенствованной формой Q-обучения или алгоритма Q*, это может привести к созданию систем ИИ, которые будут решать сложные проблемы более эффективно, что принесет пользу таким отраслям, как здравоохранение, финансы и управление окружающей средой.
Улучшение взаимодействия человека и ИИ: ИИ с улучшенными возможностями обучения или дедукции может дополнить работу человека, что приведет к более эффективному сотрудничеству в исследованиях, инновациях и повседневных задачах.
Прогресс в автоматизации: «Q*» может привести к появлению более сложных технологий автоматизации, повышая производительность и потенциально создавая новые отрасли и возможности для трудоустройства.
Риски и опасения:
Этические вопросы и вопросы безопасности: По мере того как системы ИИ становятся все более совершенными, обеспечение их этичности и безопасности становится все более сложной задачей. Существует риск непредвиденных последствий, особенно если действия ИИ не будут полностью соответствовать человеческим ценностям.
Конфиденциальность и безопасность: С развитием ИИ возрастают проблемы конфиденциальности и безопасности данных. Системы ИИ, способные глубже понимать данные и взаимодействовать с ними, могут быть использованы не по назначению. Представьте себе ИИ, который звонит вашему романтическому партнеру, когда вы ему изменяете, потому что он знает, что измена — это плохо.
Экономические последствия: Рост автоматизации и возможностей ИИ может привести к вытеснению рабочих мест в некоторых отраслях, что потребует корректировки общества и новых подходов к развитию рабочей силы. Если ИИ может делать практически все, зачем нужны люди?
Несоответствие ИИ: Риск того, что системы ИИ могут разработать цели или методы работы, которые не соответствуют намерениям или благосостоянию человека, что может привести к пагубным последствиям. Представьте себе робота-уборщика, который одержим идеей чистоты и постоянно разбрасывает ваши важные бумаги? Или полностью избавляется от создателей беспорядка?
Миф об AGI
Каким образом OpenAI, о котором ходят слухи, может повлиять на создание искусственного общего интеллекта (AGI) — святого грааля исследований в области ИИ?
Под AGI понимается способность машины понимать, обучаться и применять интеллект для решения различных задач, подобно человеческим когнитивным способностям. Это форма ИИ, которая может обобщать знания из одной области в другую, демонстрируя настоящую адаптивность и универсальность.
Независимо от того, является ли Q продвинутой формой Q-обучения или относится к алгоритму Q, важно понимать, что это не равнозначно достижению AGI. В то время как «Q*» может представлять собой значительный шаг вперед в конкретных возможностях ИИ, AGI включает в себя более широкий спектр навыков и понимания.
Достижение AGI означает разработку ИИ, способного выполнять любые интеллектуальные задачи, которые под силу человеку, что является труднодостижимой вехой.
Машина, достигшая Q, не осознает своего существования и пока не может рассуждать, выходя за пределы данных предварительного обучения и заданных человеком алгоритмов. Так что, несмотря на шумиху, «Q» — это еще не предвестник появления ИИ; это скорее умный тостер, который научился сам намазывать масло на хлеб.
Что касается того, что AGI приведут к концу цивилизации, то мы, возможно, переоцениваем свое значение в космическом порядке. Q* от OpenAI, возможно, на шаг ближе к ИИ нашей мечты (или кошмара), но это не совсем тот AGI, который будет размышлять о смысле жизни или своего кремниевого существования.
Помните, это тот самый OpenAI, который с осторожностью наблюдает за своим ChatGPT, как родитель наблюдает за малышом с маркером — с гордостью, но вечной тревогой, что он нарисует на стенах человечества. Хотя «Q*» — это скачок, AGI остается на расстоянии одного шага, а стена человечества пока в безопасности.