
В надпреварата за разработване на усъвършенстван изкуствен интелект не всички големи езикови модели са еднакви. Две нови проучвания разкриват поразителни разлики във възможностите на популярни системи като ChatGPT, когато са подложени на изпитание при сложни реални задачи.
Според изследователите от университета Purdue ChatGPT се справя трудно дори с елементарни предизвикателства, свързани с кодирането. Екипът оценява отговорите на ChatGPT на над 500 въпроса в Stack Overflow, онлайн общност за разработчици и програмисти, на теми като отстраняване на грешки и използване на API.
„Нашият анализ показва, че 52% от генерираните от ChatGPT отговори са неправилни, а 77% са многословни“, пишат изследователите. „Въпреки това отговорите на ChatGPT все още са предпочитани в 39,34% от случаите поради тяхната изчерпателност и добре формулиран стил на езика.“
За разлика от тях, проучване на Калифорнийския университет в Лос Анджелис и университета „Пепърдайн“ в Малибу демонстрира уменията на ChatGPT да отговаря на трудни въпроси от медицински изпити. Когато ChatGPT отговаря на повече от 850 въпроса с избор между няколко отговора по нефрология, напреднала специалност в областта на вътрешните болести, той получава 73% резултат, което е сходно с процента на успешно издържалите изпита медицински специализанти.
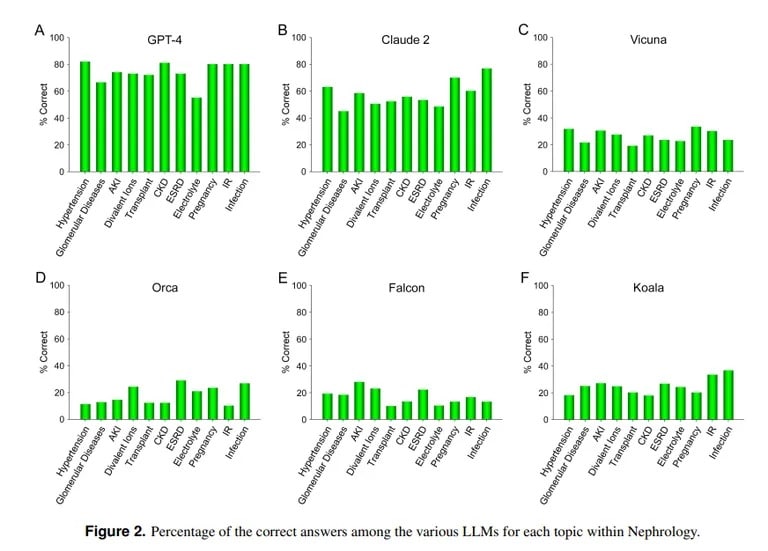
Image credit: UCLA via Arvix
„Демонстрираната понастоящем по-добра способност на GPT-4 за точен отговор на въпроси с избор между няколко отговора в областта на нефрологията насочва към полезността на подобни и по-способни модели с изкуствен интелект в бъдещи медицински приложения“, заключава екипът от UCLA.
ИИ Клод на Anthropic е вторият най-добър LLM с 54,4% верни отговори. Екипът оценява и други LLM с отворен код, но те далеч не са приемливи, като най-добрият резултат е 25,5 %, постигнат от Vicuna.
И така, защо ChatGPT се отличава в областта на медицината, но се проваля в областта на кодирането? Моделите за машинно обучение имат различни силни страни, отбелязва компютърният учен от Масачузетския технологичен институт Лекс Фридман. Клод, моделът, който стои зад медицинските познания на ChatGPT, е получил допълнителни патентовани данни за обучение от своя създател Anthropic. ChatGPT на OpenAI разчита само на публично достъпни данни. Моделите на изкуствения интелект правят страхотни неща, ако са обучени правилно с огромни количества данни, дори по-добре от повечето други модели.
Изображение с любезното съдействие на: MIT
Но ИИ няма да може да действа правилно извън параметрите, по които е бил обучен, така че ще се опита да създаде съдържание без предварителни познания за него, което води до т.нар. халюцинации. Ако наборът от данни на модела на ИИ не включва определено съдържание, той няма да може да даде добри резултати в тази област.
Както обясняват изследователите от Калифорнийския университет: „Без да отричаме значението на изчислителната мощ на конкретни МЛНЗ, липсата на свободен достъп до материали с данни за обучение, които понастоящем не са обществено достояние, вероятно ще остане една от пречките за постигане на по-нататъшно подобряване на резултатите в обозримо бъдеще.“
Затрудненията на ChatGPT при кодирането съвпадат с други оценки. Както TCN вече съобщи, изследователи от Станфорд и Калифорнийския университет в Бъркли установиха, че математическите умения и уменията за визуално мислене на ChatGPT рязко са намалели между март и юни 2022 г. Макар че първоначално е бил умел в решаването на първообрази и пъзели, до лятото той е постигнал само 2% по ключови критерии.
Така че, въпреки че ChatGPT може да играе на доктор, той има още много да учи, преди да се превърне в отличен програмист. Но това не е далеч от реалността, в края на краищата, колко лекари познавате, които са и опитни хакери?