
OpenAI发布了新的网络爬虫机器人GPTBot,以扩大其训练下一代人工智能系统的数据集–下一代机器人显然有了正式名称。该公司将 “GPT-5 “注册为商标,暗示了即将发布的版本,同时也给网络出版商提了个醒,告诉他们如何将自己的内容排除在其庞大的语料库之外。
据 OpenAI 称,该网络爬虫将收集网站上的公开数据,同时避开付费内容、敏感内容和违禁内容。不过,与谷歌、必应和 Yandex 等其他搜索引擎类似,GPTBot 的系统也是选择性关闭的–默认情况下,GPTBot 会认为可访问的信息都是公平的。为了防止 OpenAI 网络爬虫抓取网站,网站所有者必须在服务器上的标准文件中添加 “禁止 “规则。
如何禁止 OpenAI 的 GPTBot。图像: OpenAI” src=”https://www.todayscrypto.news/wp-content/uploads/2023/08/1.Disallow-OpenAI-Web-Crawler.png.jpg” width=”1000″ height=”275″ /☻
OpenAI还表示,GPTBot会预先扫描刮擦数据,删除违反其政策的个人身份信息(PII)和文本。
不过,一些技术伦理学家认为,选择退出的方法仍然会引发同意问题。
在《黑客新闻》(Hacker News)上,一些用户为 OpenAI 此举辩解说,如果人们想在未来拥有一个有能力的生成式人工智能工具,就必须收集一切可以收集到的信息。”一位用户说:”他们仍然需要当前的数据,否则他们的 GPT 模型将永远停留在 2021 年 9 月。另一位更注重隐私的用户则认为:”OpenAI 甚至不是在适度引用。它在制作衍生作品,却没有引用,从而掩盖了它。”
在发布 GPTBot 之前,OpenAI 最近遭到了批评,称其之前未经许可就擅自使用数据来训练大型语言模型(LLM),如 ChatGPT。为了解决这些问题,该公司在四月份更新了隐私政策。
与此同时,最近的 GPT-5 商标申请似乎证实了 OpenAI 正在为未来推出的下一个模型进行训练。新系统很可能涉及大规模的网络搜刮,以更新和扩展其训练数据。
这可能代表着 OpenAI 从早期强调透明度和人工智能安全性的方向发生了转变,但考虑到 ChatGPT 是世界上使用最多的 LLM,尽管市场日益拥挤和强大,这也就不足为奇了。OpenAI 的明星产品–以及任何 LLM 的明星产品–的好坏取决于用于训练它的数据的质量。
OpenAI 需要更多、更新的数据,而且需要大量的数据。
另一方面,社交媒体巨头 Meta 组建了一个开源 LLM。这家科技巨头免费提供其模型,只要你不是竞争对手,也不是太大的企业。Meta 没有透露它使用了哪些数据集来训练模型,也没有透露它收集了哪些信息。不过,这种方法可以让用户使用自己的数据集对模型进行微调。
OpenAI 依靠其所有抓取的数据来训练模型,并围绕其人工智能工具建立一个可盈利的生态系统,而 Meta 则希望围绕其数据建立一个可盈利的业务。因此,Meta 不仅利用这些数据创建更好的模型,还与第三方共享数据,以便他们使用。
“我们不会出售你的信息。相反,根据我们掌握的信息,广告商和其他合作伙伴会付钱给我们,让我们向你展示个性化的广告,”Meta 解释说。根据 Meta 的标准隐私披露,该公司收集的部分数据包括购物、浏览器历史记录、ID、财务信息、联系人和未披露的敏感信息等。
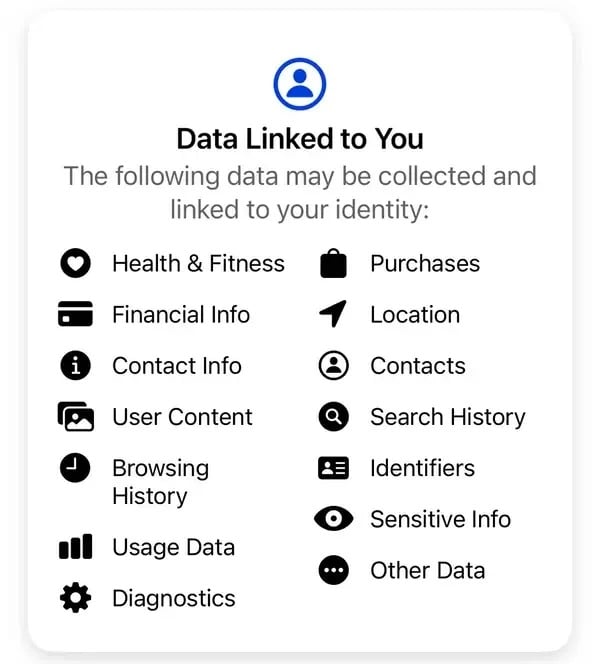
Meta从其Thread应用程序用户处收集的部分数据。图片:Meta Meta
ChatGPT 目前每月活跃用户超过 15 亿。微软对 OpenAI 的 100 亿美元投资似乎很有先见之明,因为 ChatGPT 的集成提升了必应的功能。
目前,OpenAI 在炙手可热的人工智能领域处于领先地位,科技巨头们正竞相追赶。该公司的新网络爬虫可能会进一步提高其模型的能力。但是,不断扩大的互联网数据收集也引发了有关版权和同意权的伦理问题。
随着人工智能系统越来越复杂,平衡透明度、道德和能力仍将是一项复杂的平衡工作。