
Nvidia-Forscher haben in der sich schnell entwickelnden Landschaft der KI-Tools zur Kunsterzeugung eine innovative neue Methode zur Text-Bild-Personalisierung namens Perfusion vorgestellt. Dabei handelt es sich jedoch nicht um ein millionenschweres Superschwergewicht wie seine Konkurrenten. Mit einer Größe von nur 100 KB und einer Trainingszeit von 4 Minuten ermöglicht Perfusion eine erhebliche kreative Flexibilität bei der Darstellung personalisierter Konzepte, ohne deren Identität zu verändern.
Perfusion wurde in einem von Nvidia und der Tel-Aviv Universität in Israel erstellten Forschungspapier vorgestellt. Trotz seiner geringen Größe ist es in der Lage, Tweaking-Methoden zu übertreffen, die von führenden KI-Kunstgeneratoren wie Stability AI’s Stable Diffusion v1.5, dem kürzlich veröffentlichten Stable Diffusion XL (SDXL) und MidJourney in Bezug auf die Effizienz bestimmter Editionen verwendet werden.

Bild: Nvidia Research
Die wichtigste neue Idee in Perfusion wird „Key-Locking“ genannt. Dabei werden neue Konzepte, die ein Benutzer hinzufügen möchte, wie z. B. eine bestimmte Katze oder ein Stuhl, während der Bilderstellung mit einer allgemeineren Kategorie verknüpft. Zum Beispiel würde die Katze mit dem weiter gefassten Begriff „Katze“ verknüpft.
Auf diese Weise wird eine Überanpassung vermieden, d. h. eine zu enge Abstimmung des Modells auf die genauen Trainingsbeispiele. Eine Überanpassung macht es der KI schwer, neue kreative Versionen des Konzepts zu entwickeln.
Durch die Verknüpfung der neuen Katze mit der allgemeinen Vorstellung von einer Katze kann das Modell die Katze in vielen verschiedenen Posen, Erscheinungsbildern und Umgebungen darstellen. Dabei behält sie aber immer noch die wesentliche „Katzenhaftigkeit“, die sie wie die beabsichtigte Katze aussehen lässt und nicht wie eine beliebige Katze.
Einfach ausgedrückt: Key-Locking ermöglicht es der KI, personalisierte Konzepte flexibel darzustellen und dabei ihre Kernidentität zu bewahren. Es ist, als würde man einem Künstler folgende Anweisungen geben: „Zeichne meinen Kater Tom, wie er schläft, mit Garn spielt und an Blumen schnuppert.“
Warum Nvidia denkt, dass weniger mehr ist
Perfusion ermöglicht auch die Kombination mehrerer personalisierter Konzepte in einem einzigen Bild mit natürlichen Interaktionen, im Gegensatz zu bestehenden Tools, die Konzepte isoliert lernen. Die Benutzer können den Prozess der Bilderstellung mit Hilfe von Textaufforderungen steuern und Konzepte wie eine bestimmte Katze und einen Stuhl miteinander kombinieren.
Perfusion bietet eine bemerkenswerte Funktion, die es dem Benutzer ermöglicht, das Gleichgewicht zwischen visueller Treue (das Bild) und textlicher Ausrichtung (die Eingabeaufforderung) während der Inferenz zu steuern, indem er ein einziges 100 KB großes Modell anpasst. Diese Funktion ermöglicht es dem Benutzer, die Pareto-Front (Textähnlichkeit vs. Bildähnlichkeit) zu erkunden und den optimalen Kompromiss zu finden, der seinen spezifischen Anforderungen entspricht, ohne dass ein erneutes Training erforderlich ist. Es ist wichtig zu beachten, dass das Training eines Modells eine gewisse Finesse erfordert. Wenn man sich zu sehr auf die Reproduktion des Modells konzentriert, führt dies dazu, dass das Modell immer wieder dieselbe Ausgabe produziert, und wenn man es dazu bringt, sich zu eng an die Eingabeaufforderung zu halten und keine Freiheiten zu lassen, führt dies in der Regel zu einem schlechten Ergebnis. Die Flexibilität, den Generator so einzustellen, dass er sich eng an die Eingabeaufforderung hält, ist ein wichtiges Element der Anpassung
Andere KI-Bildgeneratoren bieten zwar Möglichkeiten zur Feinabstimmung der Ausgabe, sind aber sehr sperrig. Als Referenz ist ein LoRA eine beliebte Methode zur Feinabstimmung, die in Stable Diffusion verwendet wird. Sie kann die Anwendung um Dutzende von Megabytes bis zu mehr als einem Gigabyte (GB) erweitern. Eine andere Methode, die textuelle Inversionseinbettung, ist zwar leichter, aber weniger genau. Ein Modell, das mit Dreambooth, der derzeit genauesten Technik, trainiert wurde, wiegt mehr als 2 GB.
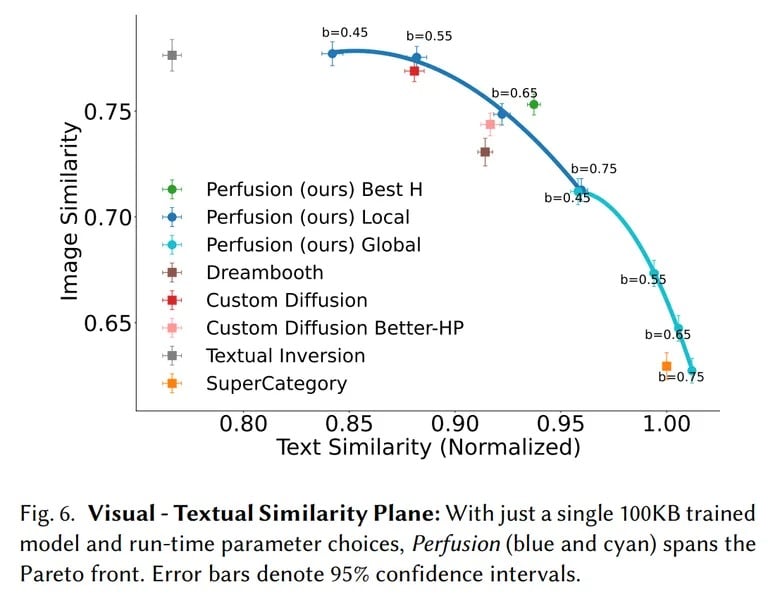
Bild: Nvidia Research
Nvidia sagt, dass Perfusion im Vergleich zu den zuvor genannten führenden KI-Techniken eine bessere visuelle Qualität und eine bessere Anpassung an die Eingabeaufforderungen bietet. Die ultra-effiziente Größe macht es möglich, nur die Teile zu aktualisieren, die es braucht, wenn es eine Feinabstimmung der Bilderzeugung vornimmt, verglichen mit dem Multi-GB-Footprint von Methoden, die eine Feinabstimmung des gesamten Modells vornehmen.
Diese Forschung passt zu Nvidias wachsendem Fokus auf KI. Die Aktie des Unternehmens ist im Jahr 2023 um mehr als 230 % gestiegen, da seine Grafikprozessoren weiterhin das Training von KI-Modellen dominieren. Angesichts der Tatsache, dass Unternehmen wie Anthropic, Google, Microsoft und Baidu Milliarden in generative KI investieren, könnte Nvidias innovatives Perfusionsmodell dem Unternehmen einen Vorteil verschaffen.
Nvidia hat vorerst nur das Forschungspapier vorgelegt und verspricht, den Code bald zu veröffentlichen.