
Dans le paysage en pleine évolution des outils de création artistique par l’IA, les chercheurs de Nvidia ont présenté une nouvelle méthode innovante de personnalisation du texte à l’image appelée Perfusion. Mais il ne s’agit pas d’un modèle super lourd d’un million de dollars comme ses concurrents. Avec une taille de seulement 100 Ko et un temps d’apprentissage de 4 minutes, Perfusion permet une grande flexibilité créative dans la représentation de concepts personnalisés tout en conservant leur identité.
Perfusion a été présenté dans un document de recherche créé par Nvidia et l’université de Tel-Aviv en Israël. Malgré sa petite taille, il est capable de surpasser les méthodes d’ajustement utilisées par les principaux générateurs d’art IA tels que Stable Diffusion v1.5 de Stability AI, Stable Diffusion XL (SDXL), récemment sorti, et MidJourney en termes d’efficacité d’éditions spécifiques.

Image : Nvidia Research
La nouvelle idée principale de Perfusion est appelée « Key-Locking ». Elle consiste à relier les nouveaux concepts que l’utilisateur souhaite ajouter, comme un chat ou une chaise, à une catégorie plus générale lors de la génération de l’image. Par exemple, le chat serait lié à l’idée plus générale de « félin ».
Cela permet d’éviter le surajustement, c’est-à-dire le fait que le modèle soit trop étroitement adapté aux exemples d’apprentissage exacts. Le surajustement rend difficile pour l’IA de générer de nouvelles versions créatives du concept.
En liant le nouveau chat à la notion générale de félin, le modèle peut représenter le chat dans de nombreuses poses, apparences et environnements différents. Mais il conserve toujours la « félinité » essentielle qui lui permet de ressembler au chat prévu, et non à n’importe quel félin.
En d’autres termes, le verrouillage des clés permet à l’IA de représenter avec souplesse des concepts personnalisés tout en conservant leur identité fondamentale. C’est comme si l’on donnait les instructions suivantes à un artiste : « Dessine mon chat Tom, pendant qu’il dort, joue avec du fil et renifle des fleurs. «
Pourquoi Nvidia pense que moins, c’est plus
Perfusion permet également de combiner plusieurs concepts personnalisés dans une seule image avec des interactions naturelles, contrairement aux outils existants qui apprennent les concepts de manière isolée. Les utilisateurs peuvent guider le processus de création d’images à l’aide d’invites textuelles, en fusionnant des concepts tels qu’un chat et une chaise spécifiques.
Perfusion offre une fonctionnalité remarquable qui permet aux utilisateurs de contrôler l’équilibre entre la fidélité visuelle (l’image) et l’alignement textuel (l’invite) pendant l’inférence en ajustant un seul modèle de 100 Ko. Cette capacité permet aux utilisateurs d’explorer facilement le front de Pareto (similarité du texte par rapport à la similarité de l’image) et de sélectionner le compromis optimal qui répond à leurs besoins spécifiques, le tout sans qu’il soit nécessaire de procéder à un nouvel entraînement. Il est important de noter que l’entraînement d’un modèle requiert une certaine finesse. Si l’on se concentre trop sur la reproduction du modèle, celui-ci produira toujours le même résultat, et si on lui fait suivre l’invite de trop près, sans aucune liberté, on obtient généralement un mauvais résultat. La possibilité d’ajuster le degré de proximité du générateur par rapport à l’invite est un élément important de la personnalisation
D’autres générateurs d’images d’IA permettent aux utilisateurs d’affiner le résultat, mais ils sont encombrants. A titre de référence, un LoRA est une méthode d’ajustement populaire utilisée dans Stable Diffusion. Elle peut ajouter des dizaines de mégaoctets à plus d’un gigaoctet (Go) à l’application. Une autre méthode, l’intégration par inversion textuelle, est plus légère mais moins précise. Un modèle formé à l’aide de Dreambooth, la technique la plus précise à l’heure actuelle, pèse plus de 2 Go.
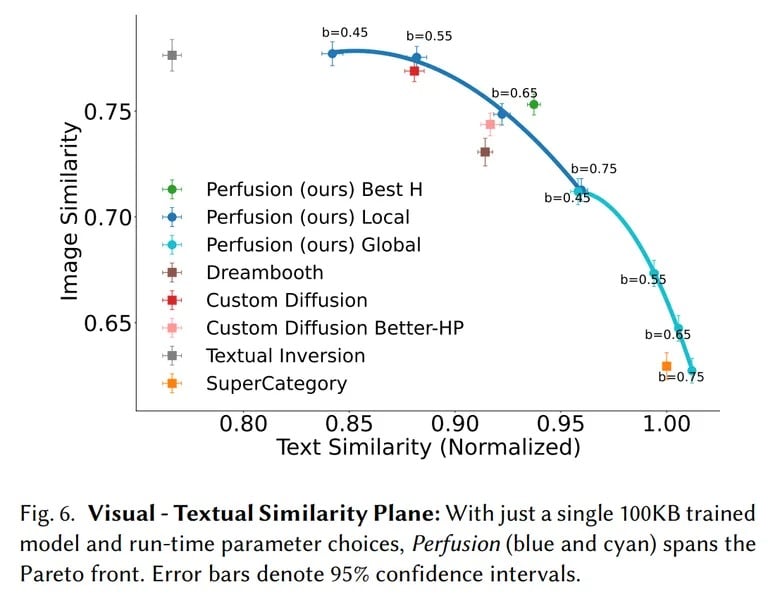
Image : Nvidia Research
En comparaison, Nvidia affirme que Perfusion produit une qualité visuelle et un alignement sur les invites supérieurs à ceux des principales techniques d’IA mentionnées précédemment. Sa taille ultra-efficace lui permet de ne mettre à jour que les parties nécessaires lorsqu’elle affine la manière dont elle produit une image, alors que les méthodes qui affinent l’ensemble du modèle ont une empreinte de plusieurs Gb.
Cette recherche s’inscrit dans le cadre de l’intérêt croissant de Nvidia pour l’IA. L’action de l’entreprise a bondi de plus de 230 % en 2023, car ses GPU continuent de dominer les modèles d’entraînement à l’IA. Alors que des entités comme Anthropic, Google, Microsoft et Baidu investissent des milliards dans l’IA générative, le modèle de perfusion innovant de Nvidia pourrait lui donner une longueur d’avance.
Pour l’instant, Nvidia n’a présenté que le document de recherche, promettant de publier le code prochainement.