
在人工智能艺术创作工具迅速发展的今天,Nvidia 研究人员推出了一种名为 Perfusion 的全新文本到图像个性化创新方法。但它并不像竞争对手那样是一个价值百万美元的超重量级模型。Perfusion 的大小仅为 100KB,训练时间为 4 分钟,在保持个性化概念身份的同时,还能在描绘个性化概念方面实现极大的创造灵活性。
Nvidia 和以色列特拉维夫大学在一份研究论文中介绍了 Perfusion。尽管它的体积很小,但在特定版本的效率方面,它能够超越领先的人工智能艺术生成器所使用的调整方法,如 Stability AI 的 Stable Diffusion v1.5、最新发布的 Stable Diffusion XL (SDXL) 和 MidJourney。

Image: Nvidia Research
Perfusion 的主要新理念称为 “锁钥”。它的工作原理是在图像生成过程中将用户想要添加的新概念(如特定的猫或椅子)连接到更广泛的类别中。例如,猫将与 “猫科动物 “这一更广泛的概念相联系。
这有助于避免过度拟合,过度拟合是指模型过于狭隘地适应精确的训练实例。过度拟合会使人工智能难以生成新的创造性概念版本。
通过将新猫与猫科动物的一般概念联系起来,模型可以将猫描绘成多种不同的姿势、外观和环境。但它仍然保留了基本的 “猫性”,这使得它看起来就像想要的猫,而不是随便什么猫科动物。
因此,简单来说,”关键锁定 “可以让人工智能灵活地描绘个性化概念,同时保持其核心特征。这就好比给艺术家下达以下指令: “画我的猫汤姆,它在睡觉、玩毛线、闻花 “
为什么英伟达认为少即是多
Perfusion还能通过自然交互将多个个性化概念结合到一张图像中,这与孤立学习概念的现有工具不同。用户可以通过文字提示引导图像创建过程,将特定的猫和椅子等概念合并在一起。
Perfusion 提供了一项出色的功能,用户可以通过调整单个 100KB 的模型,在推理过程中控制视觉保真度(图像)和文本对齐度(提示)之间的平衡。这一功能可让用户轻松探索帕累托前沿(文本相似性与图像相似性),并选择适合其特定需求的最佳权衡方案,而无需重新训练。值得注意的是,训练模型需要一些技巧。如果过于注重复制模型,会导致模型一次又一次地产生相同的输出结果;如果过于严格地按照提示进行训练,而没有任何自由度,通常会产生不好的结果。灵活调整生成器与提示的接近程度是一项重要的定制功能
其他人工智能图像生成器也有让用户微调输出的方法,但它们都很笨重。作为参考,LoRA 是稳定扩散中常用的微调方法。它可以为应用程序增加几十兆字节到一千兆字节(GB)以上的内容。另一种方法是文本反转嵌入,这种方法更轻便,但准确性较低。使用 Dreambooth(目前最准确的技术)训练的模型重量超过 2GB。
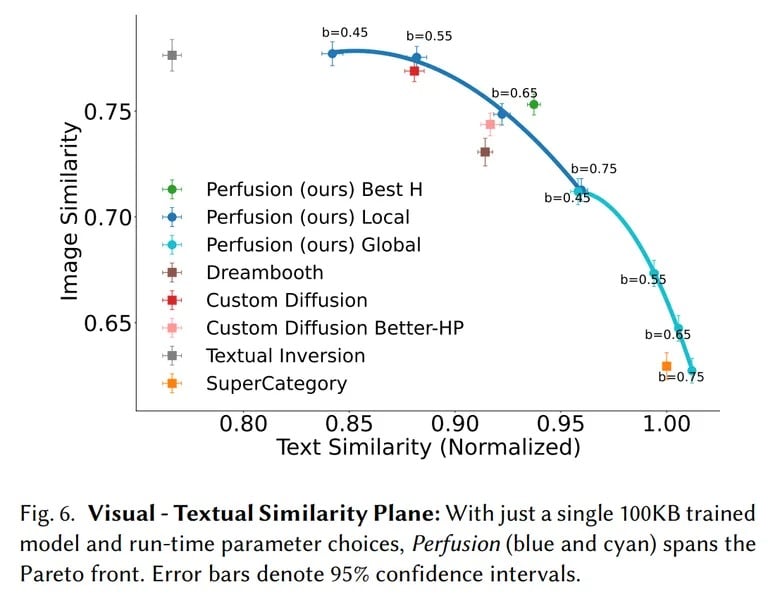
Image: Nvidia Research
相比之下,Nvidia 表示 Perfusion 比前面提到的领先人工智能技术能产生更出色的视觉质量,并能与提示保持一致。与对整个模型进行微调的方法所占用的数 GB 空间相比,Perfusion 的超高效尺寸使其在微调图像生成方式时,只需更新需要更新的部分即可。
这项研究与英伟达(Nvidia)对人工智能的日益关注不谋而合。由于其 GPU 继续主导人工智能模型的训练,该公司的股价在 2023 年飙升了 230% 以上。随着 Anthropic、谷歌、微软和百度等公司向生成式人工智能投入数十亿美元,Nvidia 的创新 Perfusion 模型可能会为其带来优势。
Nvidia 目前只提交了研究论文,并承诺将很快发布代码。