
Wenn die Gerüchte der Branche stimmen, könnte die Fortsetzung des Open-Source-Technologieriesen Anfang 2024 auf den Markt kommen.
Meta hat diese Gerüchte nicht offiziell bestätigt, aber Mark Zuckerberg hat kürzlich Licht in die Zukunft von Metas LLMs (Large Language Models) gebracht, indem er zunächst zugab, dass Llama 3 in der Entwicklung ist. Er stellte jedoch klar, dass das zugrunde liegende neue KI-Modell noch ausstehe und dass es vorrangig darum gehe, Llama 2 zu verfeinern, um es benutzerfreundlicher zu machen.
„Ich meine, dass wir noch dabei sind, das nächste Modell zu formen“, sagte er in einem Podcast-Interview über die Schnittmenge von KI und Metaversum. „Wir haben Llama 2 als Open-Source-Modell ausgebildet und veröffentlicht, und jetzt ist es notwendig, es in eine Art Verbraucherprodukt zu integrieren ……..“.
„Aber ja, wir arbeiten auch an den zukünftigen Modellen der Stiftung und ich habe keine Neuigkeiten darüber“, fuhr er fort. Ich weiß nicht genau, wann es fertig sein wird.
Obwohl Meta die Gerüchte nicht offiziell bestätigt hat, deuten die Muster des Entwicklungszyklus und die hohen Hardwareinvestitionen darauf hin, dass das Unternehmen kurz vor der Veröffentlichung eines neuen Produkts steht. llama 1 und llama 2 wurden im Abstand von sechs Monaten veröffentlicht, und wenn dieses Tempo beibehalten wird, könnte das neue llama 3 (das voraussichtlich auf OpenAI GPT-4-Niveau sein wird) in der ersten Hälfte des Jahres 2024 veröffentlicht werden.
Der Reddit-Benutzer llamaShill hat eine detaillierte Analyse der historischen Entwicklungszyklen des Meta-Modells vorgelegt und damit die Spekulationen weiter angeheizt.
Der Nutzer schlägt vor, dass das Training von Llama 1 von Juli 2022 bis Januar 2023 dauerte, mit Llama 2 direkt danach bis Juli 2023, was es wahrscheinlich macht, dass das Training von Llama 3 von Juli 2023 bis Januar 2024 stattfinden wird. Diese Ergebnisse decken sich mit der Geschichte von Metas überlegener KI, und das Unternehmen freut sich darauf, seinen nächsten Vorstoß zu präsentieren, der mit den Fähigkeiten des GPT-4 konkurrieren kann.
In der Zwischenzeit wurden die
-Technologieforen und die sozialen Medien mit Diskussionen darüber überschwemmt, wie die neue Version den Wettbewerbsvorteil von Meta wiederherstellen könnte. Die Technologiegemeinschaft hat aus Informationsschnipseln auch einen möglichen Zeitplan zusammengestellt.
Bewertet auf der GenAI Social Conference von Meta :
„Wir haben Trainingsberechnungen für die Llamas 3 und 4 durchgeführt. Der Plan ist, dass Llama-3 genauso gut ist wie GPT-4“.
„Wow, wenn Llama-3 so gut wie GPT-4 ist, werden Sie es dann weiterhin als Open Source zur Verfügung stellen?“
„Ja, das werden wir tun. Sorry, aligneur“.
– jason (@agikoala) 25. August 2023
Plus ein kleines Twitter-Detail: ein Gespräch, das angeblich bei einem sozialen Treffen der „Meta GenAI“ belauscht und später von Jason Way, einem Forscher bei der OpenAI, auf Twitter veröffentlicht wurde. Laut Jason Way „verfügen wir bereits über die für das Training der Lamas 3 und 4 erforderliche Rechengrundlage“ und eine nicht näher bezeichnete Quelle bestätigte, dass diese als Open Source zur Verfügung stehen würde.
Inzwischen hat sich das Unternehmen mit Dell zusammengetan, um Llama 2 für Geschäftsanwender zur Verfügung zu stellen, und unterstreicht damit sein Engagement für den Schutz der Privatsphäre und die Sicherheit, das sowohl strategisch als auch gleichzeitig erfolgt. Dieses Engagement ist entscheidend, da Meta sich darauf vorbereitet, gegen Giganten wie OpenAI und Google anzutreten.
Da Meta auch künstliche Intelligenz in viele seiner Produkte integriert, ist es nur logisch, dass das Unternehmen seine Anstrengungen verdoppelt, um nicht ins Hintertreffen zu geraten. llama 2 wird von Meta AI sowie von anderen Diensten wie Meta Chatbot, Meta Generation Service und Meta Artificial Intelligence Glasses gespeist.
In diesem Mahlstrom der Spekulationen faszinieren und mystifizieren Mark Zuckerbergs Überlegungen zu Open Source llama 3 nur“. In einem kürzlich ausgestrahlten Podcast mit dem Informatiker Lex Friedman sagte Mark Zuckerberg: „Wir brauchen einen Prozess, um es neu und sicher zu machen.
Llama 2 verwendet eine mehrstufige Architektur, die Versionen mit 7, 13 und 70 Milliarden Parametern anbietet, die jeweils für unterschiedliche Komplexitätsgrade und Rechenleistungen geeignet sind. Die LLM-Parameter fungieren als neuronale Blöcke, die die Fähigkeit des Modells, Sprache zu verstehen und zu generieren, bestimmen, und die Anzahl der Parameter korreliert oft mit der Komplexität und der potenziellen Qualität der Ergebnisse des Modells.
Dieses leistungsstarke KI-Modell wurde mit einem umfangreichen Korpus von 2 Billionen Wörtern trainiert, was seine Fähigkeit bestätigt, in einem breiten Spektrum von Themen und Kontexten zu navigieren und menschenähnliche Texte zu generieren.
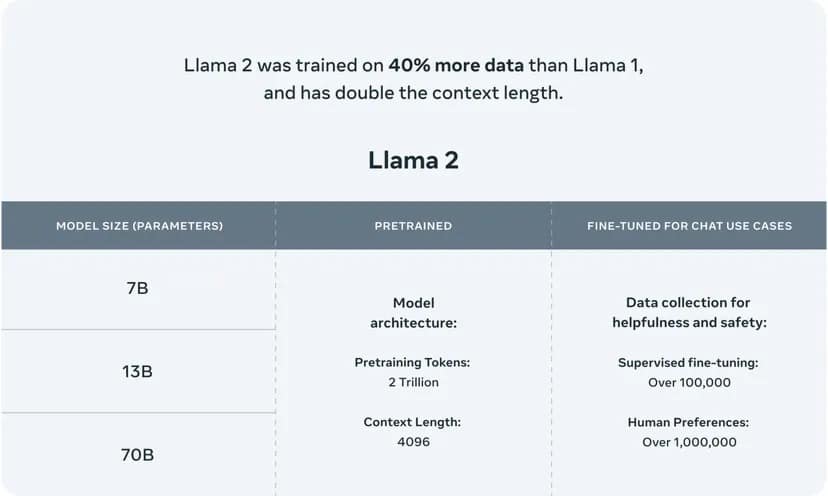
Image courtesy of Meta
.